

When you enthusiastically learn basic crawler knowledge from the Internet, just find a goal and practice it , the short book with a large number of articles contains a lot of valuable information, so it will naturally become your choice. If you try it, you will find that it is not as simple as you think, because it contains a lot of js-related data transmission. Let me use a traditional crawler to demonstrate it first: >
Open the homepage of the Jianshu, there seems to be nothing special

jianshu home page
Open the developer mode of
chrome, and found that the title of the article andhrefare all in theatag, and there seems to be none What’s different

The next step is to find all thea
tags on the page, But wait, if you look carefully, you will find that when the pulley is halfway rolled, the page will load more. This step will be repeated three times until theRead morebuttonappears at the bottom.

Pulley
Not only that but the read more
hrefat the bottom does not tell us to load the rest of the page information , the only way iskeep clicking the read more button
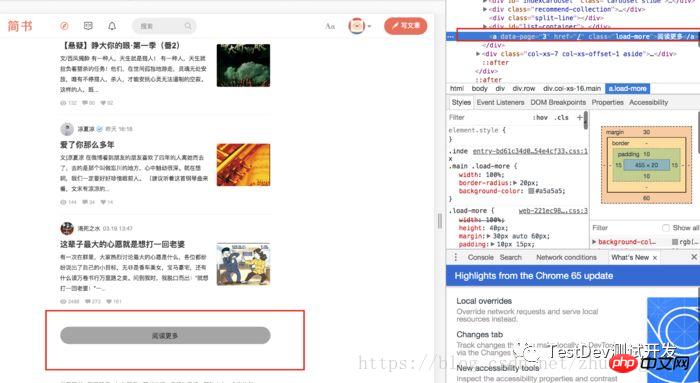
Repeat the pulley three times to slide the center of the page and keep clicking the button This kind of operation http request cannot be done, is this more like a js operation? That's right, Jianshu's article is not a regular http request. We cannot constantly redirect according to different URLs, but some actions on the page to load the page information.

a tags. First you have to download the selenium package in python
>>> pip3 install selenium
在写代码之前一定要把chromedriver同一文件夹内,因为我们需要引用PATH,这样方便点。首先我们的第一个任务是刷出加载更多的按钮,需要做3次将滑轮重复三次滑倒页面的中央,这里方便起见我滑到了底部
from selenium import webdriverimport time
browser = webdriver.Chrome("./chromedriver")
browser.get("https://www.jianshu.com/")for i in range(3):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") // execute_script是插入js代码的
time.sleep(2) //加载需要时间,2秒比较合理看看效果
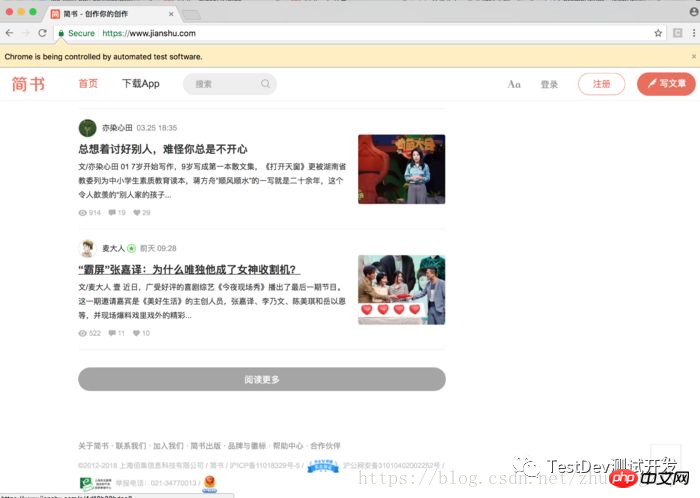
刷出了按钮
接下来就是不断点击按钮加载页面,继续加入刚才的py文件之中
for j in range(10): //这里我模拟10次点击
try:
button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();")
time.sleep(2) except: pass'''
上面的js代码说明一下
var a = document.getElementsByClassName('load-more');选择load-more这个元素
a[0].click(); 因为a是一个集合,索引0然后执行click()函数
'''这个我就不贴图了,成功之后就是不断地加载页面 ,知道循环完了为止,接下来的工作就简单很多了,就是寻找a标签,get其中的text和href属性,这里我直接把它们写在了txt文件之中.
titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try:
f.write(t.text + " " + t.get_attribute("href"))
f.write("\n") except TypeError: pass最终结果
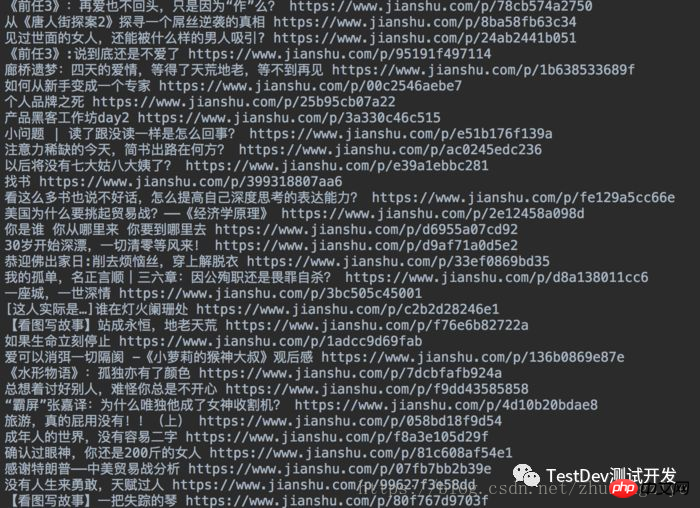
简书文章
不断加载页面肯定也很烦人,所以我们测试成功之后并不想把浏览器显示出来,这需要加上headless模式
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome("./chromedriver", chrome_options=options) //把上面的browser加入chrome_options参数当我们没办法使用正常的http请求爬取时,可以使用selenium操纵浏览器来抓取我们想要的内容,这样有利有弊,比如
优点
可以暴力爬虫
简书并不需要cookie才能查看文章,不需要费劲心思找代理,或者说我们可以无限抓取并且不会被ban
首页应该为ajax传输,不需要额外的http请求
缺点
爬取速度太满,想象我们的程序,点击一次需要等待2秒那么点击600次需要1200秒, 20分钟...
这是所有完整的代码
from selenium import webdriverimport time
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome("./chromedriver", chrome_options=options)
browser.get("https://www.jianshu.com/")for i in range(3):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)# print(browser)for j in range(10): try:
button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();")
time.sleep(2) except: pass#titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try:
f.write(t.text + " " + t.get_attribute("href"))
f.write("\n") except TypeError: pass相关推荐:
[python爬虫] Selenium爬取新浪微博内容及用户信息
[Python爬虫]利用Selenium等待Ajax加载及模拟自动翻页,爬取东方财富网公司公告
Python爬虫:Selenium+ BeautifulSoup 爬取JS渲染的动态内容(雪球网新闻)
The above is the detailed content of How selenium+python crawls Jianshu website. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



