
 Backend Development
Python Tutorial
Python implements finding the longest non-repeating substring for a given string
Backend Development
Python Tutorial
Python implements finding the longest non-repeating substring for a given string
Python implements finding the longest non-repeating substring for a given string

This article mainly introduces Python's method of finding the longest non-repeating substring for a given string, involving Python's traversal, sorting, calculation and other related operation skills for strings. Friends who need it can refer to it
The example in this article describes Python's method of finding the longest non-repeating substring for a given string. Share it with everyone for your reference, the details are as follows:
Question:
Given a string, find the longest repeating subsequence in it , if the string is composed of a single character, such as "aaaaaaaaaaaaa", then the output that meets the requirements is a
Thinking:
There are two ideas here The first thing I can think of is
(1) Traverse the string from the beginning, set the flag bit, and when you find that it coincides with the previous flag bit in the process of going back, go back and check the new substring. Whether the string is the same as the previous string or the substring of the previous string, if it is the same, the substring is recorded and the count is increased by 1 until the processing is completed
(2) Use the sliding window slicing mechanism to generate all slice connections For statistics and processing, the function of double sorting is mainly used.
This article uses the second method. The following is the specific implementation:
#!usr/bin/env python
#encoding:utf-8
'''''
__Author__:沂水寒城
功能:给定一个字符串,寻找最长重复子串
'''
from collections import Counter
def slice_window(one_str,w=1):
'''''
滑窗函数
'''
res_list=[]
for i in range(0,len(one_str)-w+1):
res_list.append(one_str[i:i+w])
return res_list
def main_func(one_str):
'''''
主函数
'''
all_sub=[]
for i in range(1,len(one_str)):
all_sub+=slice_window(one_str,i)
res_dict={}
#print Counter(all_sub)
threshold=Counter(all_sub).most_common(1)[0][1]
slice_w=Counter(all_sub).most_common(1)[0][0]
for one in all_sub:
if one in res_dict:
res_dict[one]+=1
else:
res_dict[one]=1
sorted_list=sorted(res_dict.items(), key=lambda e:e[1], reverse=True)
tmp_list=[one for one in sorted_list if one[1]>=threshold]
tmp_list.sort(lambda x,y:cmp(len(x[0]),len(y[0])),reverse=True)
#print tmp_list
print tmp_list[0][0]
if __name__ == '__main__':
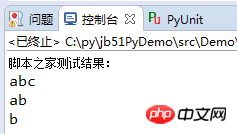
print "脚本之家测试结果:"
one_str='abcabcd'
two_str='abcabcabd'
three_str='bbbbbbb'
main_func(one_str)
main_func(two_str)
main_func(three_str)The results are as follows:
Related recommendations:
Python implementation follows Specify the requirement to output a number in reverse order
Python implements the method of inputting multiple lines in IDLE
The above is the detailed content of Python implements finding the longest non-repeating substring for a given string. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
The key to running Jupyter Notebook in VS Code is to ensure that the Python environment is properly configured, understand that the code execution order is consistent with the cell order, and be aware of large files or external libraries that may affect performance. The code completion and debugging functions provided by VS Code can greatly improve coding efficiency and reduce errors.
 Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang is more suitable for high concurrency tasks, while Python has more advantages in flexibility. 1.Golang efficiently handles concurrency through goroutine and channel. 2. Python relies on threading and asyncio, which is affected by GIL, but provides multiple concurrency methods. The choice should be based on specific needs.
