
 Backend Development
Python Tutorial
Detailed explanation of how to quickly build a neural network with PyTorch and save and extract it
Backend Development
Python Tutorial
Detailed explanation of how to quickly build a neural network with PyTorch and save and extract it
Detailed explanation of how to quickly build a neural network with PyTorch and save and extract it

This article mainly introduces PyTorch to quickly build a neural network and a detailed explanation of its saving and extraction methods. Now I share it with you and give it a reference. Let’s take a look together
Sometimes we have trained a model and want to save it for direct use next time without spending time training it again next time. In this section we will explain how to quickly build a neural network with PyTorch and its Detailed explanation of the saving and extraction method
1. How to quickly build a neural network with PyTorch
First look at the experimental code:
import torch
import torch.nn.functional as F
# 方法1,通过定义一个Net类来建立神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net1 = Net(2, 10, 2)
print('方法1:\n', net1)
# 方法2 通过torch.nn.Sequential快速建立神经网络结构
net2 = torch.nn.Sequential(
torch.nn.Linear(2, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 2),
)
print('方法2:\n', net2)
# 经验证,两种方法构建的神经网络功能相同,结构细节稍有不同
'''''
方法1:
Net (
(hidden): Linear (2 -> 10)
(predict): Linear (10 -> 2)
)
方法2:
Sequential (
(0): Linear (2 -> 10)
(1): ReLU ()
(2): Linear (10 -> 2)
)
'''I previously learned how to build a neural network by defining a Net class. In classNet, first inherit the construction method of the torch.nn.Module module through the super function, and then pass Build the structural information of each layer of the neural network by adding attributes, improve the connection information between each layer of the neural network in the forward method, and then complete the construction of the neural network structure by defining Net class objects.
Another way to build a neural network, which can also be said to be a quick construction method, is to directly complete the establishment of the neural network through torch.nn.Sequential.
The neural network structures constructed by the two methods are exactly the same, and the network information can be printed out through the print function, but the print results will be slightly different.
2. PyTorch neural network storage and extraction
When learning and researching deep learning, when we go through a certain period of training, When we get a better model, of course we want to save the model and model parameters for later use, so it is necessary to save the neural network and extract and reload the model parameters.
First of all, we need to save the network structure and model parameters through torch.save() after the definition and training part of the neural network that needs to save the network structure and its model parameters. There are two saving methods: one is to save the structural information and model parameter information of the entire neural network, and the object of save is the network net; the other is to save only the training model parameters of the neural network, and the object of save is net.state_dict(), The saved results are stored in the form of .pkl files.
Corresponds to the above two saving methods, and there are two reloading methods. Corresponding to the first complete network structure information, you can directly initialize the new neural network object through torch.load(‘.pkl’) when reloading. Corresponding to the second method, which only saves model parameter information, you need to first build the same neural network structure and complete the reloading of model parameters through net.load_state_dict(torch.load('.pkl')). When the network is relatively large, the first method will take more time.
Code implementation:
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 创建数据
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y = x.pow(2) + 0.2*torch.rand(x.size())
x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False)
# 将待保存的神经网络定义在一个函数中
def save():
# 神经网络结构
net1 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
optimizer = torch.optim.SGD(net1.parameters(), lr=0.5)
loss_function = torch.nn.MSELoss()
# 训练部分
for i in range(300):
prediction = net1(x)
loss = loss_function(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 绘图部分
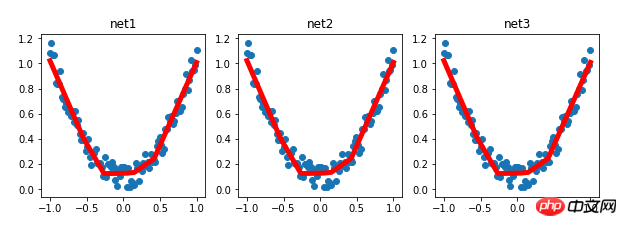
plt.figure(1, figsize=(10, 3))
plt.subplot(131)
plt.title('net1')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 保存神经网络
torch.save(net1, '7-net.pkl') # 保存整个神经网络的结构和模型参数
torch.save(net1.state_dict(), '7-net_params.pkl') # 只保存神经网络的模型参数
# 载入整个神经网络的结构及其模型参数
def reload_net():
net2 = torch.load('7-net.pkl')
prediction = net2(x)
plt.subplot(132)
plt.title('net2')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 只载入神经网络的模型参数,神经网络的结构需要与保存的神经网络相同的结构
def reload_params():
# 首先搭建相同的神经网络结构
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
# 载入神经网络的模型参数
net3.load_state_dict(torch.load('7-net_params.pkl'))
prediction = net3(x)
plt.subplot(133)
plt.title('net3')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 运行测试
save()
reload_net()
reload_params()Experimental results:
Related recommendations:
Method of implementing convolutional neural network CNN on PyTorch
Detailed explanation of PyTorch batch training and optimizer comparison
mnist classification example for getting started with Pytorch
The above is the detailed content of Detailed explanation of how to quickly build a neural network with PyTorch and save and extract it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 iFlytek: Huawei's Ascend 910B's capabilities are basically comparable to Nvidia's A100, and they are working together to create a new base for my country's general artificial intelligence
Oct 22, 2023 pm 06:13 PM
iFlytek: Huawei's Ascend 910B's capabilities are basically comparable to Nvidia's A100, and they are working together to create a new base for my country's general artificial intelligence
Oct 22, 2023 pm 06:13 PM
This site reported on October 22 that in the third quarter of this year, iFlytek achieved a net profit of 25.79 million yuan, a year-on-year decrease of 81.86%; the net profit in the first three quarters was 99.36 million yuan, a year-on-year decrease of 76.36%. Jiang Tao, Vice President of iFlytek, revealed at the Q3 performance briefing that iFlytek has launched a special research project with Huawei Shengteng in early 2023, and jointly developed a high-performance operator library with Huawei to jointly create a new base for China's general artificial intelligence, allowing domestic large-scale models to be used. The architecture is based on independently innovative software and hardware. He pointed out that the current capabilities of Huawei’s Ascend 910B are basically comparable to Nvidia’s A100. At the upcoming iFlytek 1024 Global Developer Festival, iFlytek and Huawei will make further joint announcements on the artificial intelligence computing power base. He also mentioned,
 YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
Today's deep learning methods focus on designing the most suitable objective function so that the model's prediction results are closest to the actual situation. At the same time, a suitable architecture must be designed to obtain sufficient information for prediction. Existing methods ignore the fact that when the input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost. This article will delve into important issues when transmitting data through deep networks, namely information bottlenecks and reversible functions. Based on this, the concept of programmable gradient information (PGI) is proposed to cope with the various changes required by deep networks to achieve multi-objectives. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights. In addition, a new lightweight network framework is designed
 Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
In natural language generation tasks, sampling method is a technique to obtain text output from a generative model. This article will discuss 5 common methods and implement them using PyTorch. 1. GreedyDecoding In greedy decoding, the generative model predicts the words of the output sequence based on the input sequence time step by time. At each time step, the model calculates the conditional probability distribution of each word, and then selects the word with the highest conditional probability as the output of the current time step. This word becomes the input to the next time step, and the generation process continues until some termination condition is met, such as a sequence of a specified length or a special end marker. The characteristic of GreedyDecoding is that each time the current conditional probability is the best
 The perfect combination of PyCharm and PyTorch: detailed installation and configuration steps
Feb 21, 2024 pm 12:00 PM
The perfect combination of PyCharm and PyTorch: detailed installation and configuration steps
Feb 21, 2024 pm 12:00 PM
PyCharm is a powerful integrated development environment (IDE), and PyTorch is a popular open source framework in the field of deep learning. In the field of machine learning and deep learning, using PyCharm and PyTorch for development can greatly improve development efficiency and code quality. This article will introduce in detail how to install and configure PyTorch in PyCharm, and attach specific code examples to help readers better utilize the powerful functions of these two. Step 1: Install PyCharm and Python
 An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
The current mainstream AI chips are mainly divided into three categories: GPU, FPGA, and ASIC. Both GPU and FPGA are relatively mature chip architectures in the early stage and are general-purpose chips. ASIC is a chip customized for specific AI scenarios. The industry has confirmed that CPUs are not suitable for AI computing, but they are also essential in AI applications. GPU Solution Architecture Comparison between GPU and CPU The CPU follows the von Neumann architecture, the core of which is the storage of programs/data and serial sequential execution. Therefore, the CPU architecture requires a large amount of space to place the storage unit (Cache) and the control unit (Control). In contrast, the computing unit (ALU) only occupies a small part, so the CPU is performing large-scale parallel computing.
 'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
In Minecraft, redstone is a very important item. It is a unique material in the game. Switches, redstone torches, and redstone blocks can provide electricity-like energy to wires or objects. Redstone circuits can be used to build structures for you to control or activate other machinery. They themselves can be designed to respond to manual activation by players, or they can repeatedly output signals or respond to changes caused by non-players, such as creature movement and items. Falling, plant growth, day and night, and more. Therefore, in my world, redstone can control extremely many types of machinery, ranging from simple machinery such as automatic doors, light switches and strobe power supplies, to huge elevators, automatic farms, small game platforms and even in-game machines. built computer. Recently, B station UP main @
 Implementing noise removal diffusion model using PyTorch
Jan 14, 2024 pm 10:33 PM
Implementing noise removal diffusion model using PyTorch
Jan 14, 2024 pm 10:33 PM
Before we understand the working principle of the Denoising Diffusion Probabilistic Model (DDPM) in detail, let us first understand some of the development of generative artificial intelligence, which is also one of the basic research of DDPM. VAEVAE uses an encoder, a probabilistic latent space, and a decoder. During training, the encoder predicts the mean and variance of each image and samples these values from a Gaussian distribution. The result of the sampling is passed to the decoder, which converts the input image into a form similar to the output image. KL divergence is used to calculate the loss. A significant advantage of VAE is its ability to generate diverse images. In the sampling stage, one can directly sample from the Gaussian distribution and generate new images through the decoder. GAN has made great progress in variational autoencoders (VAEs) in just one year.
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
