
 Backend Development
Python Tutorial
How to read txt text line by line and remove duplicates under python3.4.3
Backend Development
Python Tutorial
How to read txt text line by line and remove duplicates under python3.4.3
How to read txt text line by line and remove duplicates under python3.4.3

This article mainly introduces the method of reading txt text line by line and removing duplicates under python3.4.3. It has a certain reference value. Now I share it with you. Friends in need can refer to it
Issues that should be paid attention to when reading and writing files include:
1. Character encoding
2. Close the file descriptor immediately after the operation is completed
3. Code compatibility
Several methods:
#!/bin/python3
original_list1=[" "]
original_list2=[" "]
original_list3=[" "]
original_list4=[" "]
newlist1=[" "]
newlist2=[" "]
newlist3=[" "]
newlist4=[" "]
newtxt1=""
newtxt2=""
newtxt3=""
newtxt4=""
#first way to readline
f = open("duplicate_txt.txt","r+") # 返回一个文件对象
line = f.readline() # 调用文件的 readline()方法
while line:
original_list1.append(line)
line = f.readline()
f.close()
#use "set()" remove duplicate str in the list
# in this way,list will sort randomly
newlist1 = list(set(original_list1))
#newlist1 = {}.fromkeys(original_list1).keys() #faster
#rebuild a new txt
newtxt1="".join(newlist1)
f1 = open("noduplicate1.txt","w")
f1.write(newtxt1)
f1.close()
###################################################################
#second way to readline
for line in open("duplicate_txt.txt","r+"):
original_list2.append(line)
newlist2 = list(set(original_list2))
newlist2.sort(key=original_list2.index) #sort
#newlist2 = sorted(set(original_list2),key=l1.index) #other way
newtxt2="".join(newlist2)
f2 = open("noduplicate2.txt","w")
f2.write(newtxt2)
f2.close()
###################################################################
#third way to readline
f3 = open("duplicate_txt.txt","r")
original_list3 = f3.readlines() #读取全部内容 ,并以列表方式返回
for i in original_list3: #遍历去重
if not i in newlist3:
newlist3.append(i)
newtxt3="".join(newlist3)
f4 = open("noduplicate3.txt","w")
f4.write(newtxt3)
f4.close()
###################################################################
#fourth way
f5 = open('duplicate_txt.txt',"r+")
try:
original_list4 = f5.readlines()
[newlist4.append(i) for i in original_list4 if not i in newlist4]
newtxt4="".join(newlist4)
f6 = open("noduplicate4.txt","w")
f6.write(newtxt4)
f6.close()
finally:
f5.close()Result:
Before deduplication:

##After deduplication (out of order ):

##After deduplication (in order):

SummaryThe program below involves file read and write operations and linked list operations. Several issues mentioned at the beginning of the article , since we are not using Chinese, we don’t care about the encoding, but I still have to mention it here:
f = open("test.txt","w")
f.write(u"你好")The above code will report an error if run in python2
 #The error is reported because the program cannot save the unicode string directly. It must be encoded and converted into a binary byte sequence of type str before it can be saved.
#The error is reported because the program cannot save the unicode string directly. It must be encoded and converted into a binary byte sequence of type str before it can be saved.
The write() method will automatically convert the encoding, using ascii encoding format by default, and ascii cannot handle Chinese, so UnicodeEncodeError occurs.
The correct way is to manually convert the format before calling the write() method, and use utf-8 or gbk to convert to str.
f = open("test.txt","w")
text=u"你好"
text=text.encode(encoding='utf-8')
f.write(text)About close(): What will be the impact of not closing? ? After the operation is completed, not closing the file will cause a waste of system resources, because the number of file descriptors that can be opened by the system is limited. Linux is 65535.
Generally speaking, it will be OK after close, but there may be special situations. For example, an error has occurred when calling the open() function, and the permissions are insufficient. Calling close() will definitely report an error. Another method is that if there is insufficient disk space during write(), an error will be reported, and close() will have no chance to execute. The correct way is to use try except to catch the exception:
f = open("test.txt","w")
try:
text=u"你好"
text=text.encode(encoding='utf-8')
f.write(text)
except: IOError as e:
print("oops,%s"%e.args[0])
finally:
f.close()A more elegant way of writing is to use with...as.
with open("test.txt","w") as f:
text=u"你好"
f.write(text.encode(encoding='utf-8'))The file object implements the morning and afternoon manager protocol. When the program enters the with statement, the file object will be assigned to the variable f. When the program exits with, it will automatically Call the close() method.
About compatibility issues: The open() functions of python2 and python3 are different. The latter can specify characters in the function. Encoding format.
How to solve the compatibility open() problem between python2 and python3?
Use the open() function under the io module. io.open in python2 is equivalent to the open function of python3
from io import open
with open("test.txt","w",encoding='utf-8') as f:
f.write(u"你好")Related recommendations :
##
The above is the detailed content of How to read txt text line by line and remove duplicates under python3.4.3. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 What to do if win7 system cannot open txt text
Jul 06, 2023 pm 04:45 PM
What to do if win7 system cannot open txt text
Jul 06, 2023 pm 04:45 PM
What should I do if win7 system cannot open txt text? When we need to edit text files on our computers, the easiest way is to use text tools. However, some users find that their computers cannot open txt text files. So how to solve this problem? Let’s take a look at the detailed tutorial to solve the problem of unable to open txt text in win7 system. Tutorial to solve the problem that win7 system cannot open txt text. 1. Right-click any txt file on the desktop. If there is no txt file, you can right-click to create a new text document, and then select properties, as shown below: 2. In the opened txt properties window , find the change button under the general options, as shown in the figure below: 3. In the pop-up open mode setting
 Try new ringtones and text tones: Experience the latest sound alerts on iPhone in iOS 17
Oct 12, 2023 pm 11:41 PM
Try new ringtones and text tones: Experience the latest sound alerts on iPhone in iOS 17
Oct 12, 2023 pm 11:41 PM
In iOS 17, Apple has overhauled its entire selection of ringtones and text tones, offering more than 20 new sounds that can be used for calls, text messages, alarms, and more. Here's how to see them. Many new ringtones are longer and sound more modern than older ringtones. They include arpeggio, broken, canopy, cabin, chirp, dawn, departure, dolop, journey, kettle, mercury, galaxy, quad, radial, scavenger, seedling, shelter, sprinkle, steps, story time , tease, tilt, unfold and valley. Reflection remains the default ringtone option. There are also 10+ new text tones available for incoming text messages, voicemails, incoming mail alerts, reminder alerts, and more. To access new ringtones and text tones, first, make sure your iPhone
 Using large models to create a new paradigm for text summary training
Jun 10, 2023 am 09:43 AM
Using large models to create a new paradigm for text summary training
Jun 10, 2023 am 09:43 AM
1. Text task This article mainly discusses the method of generative text summarization, and how to use contrastive learning and large models to implement the latest generative text summarization training paradigm. It mainly involves two articles, one is BRIO: Bringing Order to Abstractive Summarization (2022), which uses contrastive learning to introduce ranking tasks in the generative model; the other is OnLearning to Summarize with Large Language Models as References (2023), which further introduces large models to generate high-quality training data based on BRIO. 2. Generative text summarization training methods and
 How to search for text across all tabs in Chrome and Edge
Feb 19, 2024 am 11:30 AM
How to search for text across all tabs in Chrome and Edge
Feb 19, 2024 am 11:30 AM
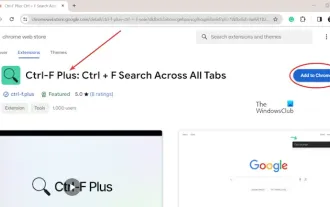
This tutorial shows you how to find specific text or phrases on all open tabs in Chrome or Edge on Windows. Is there a way to do a text search on all open tabs in Chrome? Yes, you can use a free external web extension in Chrome to perform text searches on all open tabs without having to switch tabs manually. Some extensions like TabSearch and Ctrl-FPlus can help you achieve this easily. How to search text across all tabs in Google Chrome? Ctrl-FPlus is a free extension that makes it easy for users to search for a specific word, phrase or text across all tabs of their browser window. This expansion
 After chatting online for a month, the pig-killing scammer was actually defeated by AI! 2 million netizens shouted shocked
Apr 12, 2023 am 09:40 AM
After chatting online for a month, the pig-killing scammer was actually defeated by AI! 2 million netizens shouted shocked
Apr 12, 2023 am 09:40 AM
Speaking of "pig killing plate", everyone must hate it with itch. In this type of online dating and marriage scams, scammers will look for victims in advance who are easy to fall for, and they are often innocent, kind-hearted and well-behaved girls with beautiful fantasies about love. In order to fight these scammers for 500 rounds, "Turing's Cat", a well-known up-and-comer in the technology circle at Station B, trained an AI that frequently makes hilarious jokes in chat, and is even better than a real person. As a result, with the operation of AI, the scammer was confused by this fake lady and directly transferred 520 to "her". What’s even funnier is that after discovering that the scammer had no chance to take advantage of him, not only did he break his defense, but he was also given a “famous quote” by the AI: As soon as the video came out, it immediately went viral, and friends surfing at station B were all fooled.
 How to copy text from screenshots on Windows 11
Sep 20, 2023 pm 05:57 PM
How to copy text from screenshots on Windows 11
Sep 20, 2023 pm 05:57 PM
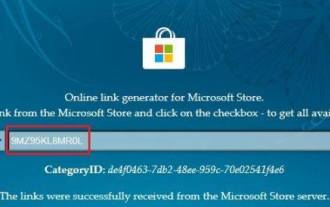
Download the new Snipping Tool with text actions Although the new Snipping Tool is limited to development and canary versions, if you don’t want to wait, you can install the updated Windows 11 Snipping Tool (version number 11.2308.33.0) now. How this works: 1. Go ahead and open this website (visit) on your Windows PC. 2. Next, select "Product ID" and paste "9MZ95KL8MR0L" into the text field. 3. Switch to the "Quick" ring from the right drop-down menu and click Search. 4. Now, look for this version “2022.2308.33.0” in the search results that appear. 5. Right click on the one with MSIXBUNDLE extension and in context menu
 Learn how to open win11 text documents
Jan 02, 2024 pm 03:54 PM
Learn how to open win11 text documents
Jan 02, 2024 pm 03:54 PM
Text documents are very important files in the system. They not only allow us to view a lot of text content, but also provide programming functions. However, after the win11 system was updated, many friends found that text documents could not be opened. At this time, we can open them directly by running them. Let’s take a look. Where to open a text document in win11 1. First press "win+r" on the keyboard to call up run. 2. Then enter "notepad" to create a new text document directly. 3. If we want to open an existing text document, we can also click on the file in the upper left corner and then click "Open".
 How to use Windows Copilot with the Clipboard to expand, explain, summarize, or modify copied text
Jul 29, 2023 am 08:41 AM
How to use Windows Copilot with the Clipboard to expand, explain, summarize, or modify copied text
Jul 29, 2023 am 08:41 AM
Of the few features Copilot currently has on Windows 11, perhaps the most useful is one that allows you to interact with and adjust text that has been copied to the clipboard. This makes it easy to use Copilot as a text editing and summarizing tool, right from your desktop. Here's everything you need to know about using Copilot to interpret, revise, extend, and summarize text on Windows. How to use copied text in Windows Copilot A preview of Copilot gives us our first good look at Windows' integration of native AI support. One of the early capabilities for modifying or extending text copied from elsewhere was through content creation, summarization, revision and
