

Python method to parse and read the contents of PDF files

This article mainly introduces the method of Python parsing and reading the content of PDF files. It also describes the relevant operating techniques of Python2.7 in win32 and win64 environments to read PDF in the form of examples. Friends in need can refer to the following
The examples in this article describe how Python parses and reads the contents of PDF files. Share it with everyone for your reference, the details are as follows:
1. Problem description
Use python to read the PDF text content.
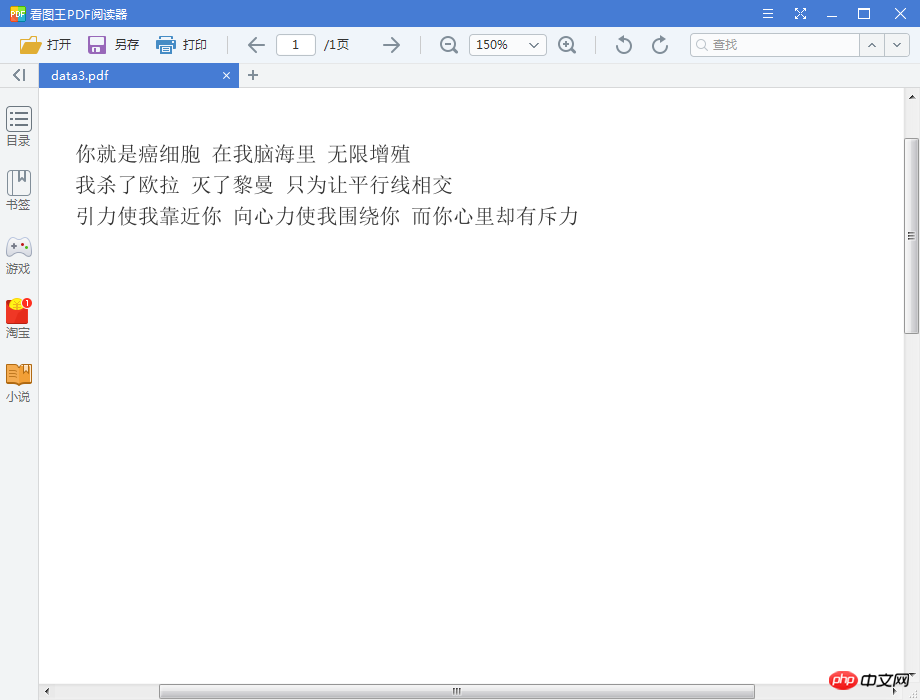
2. Effect
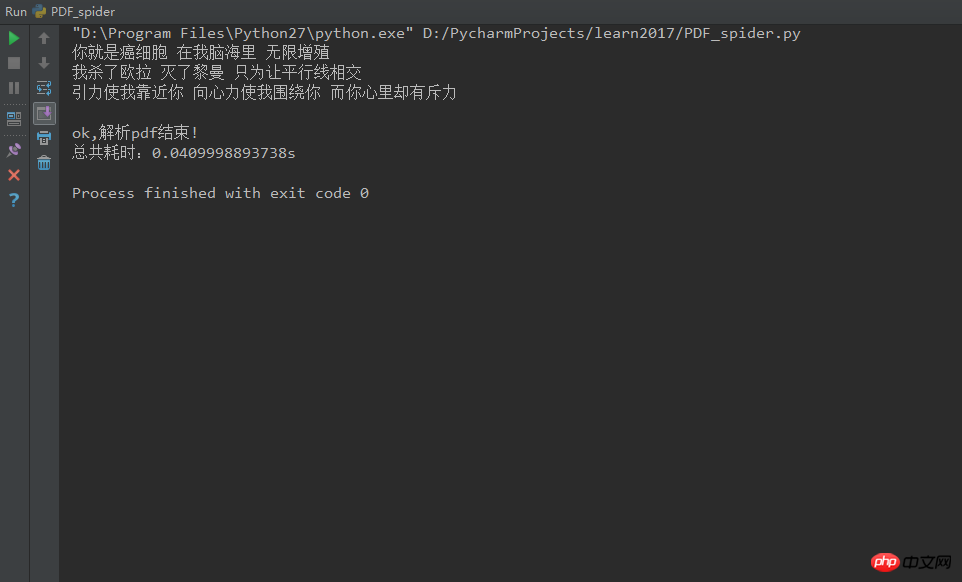
# #3. Running environment
python2.74. Libraries that need to be installed
pip install pdfminer
5. Implementation source code
Code 1 (win64)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/data3.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'Code 2 (win32)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument(praser)
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(doc): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/36.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'Python implements the method of grabbing HTML web pages and saving them as PDF files
The above is the detailed content of Python method to parse and read the contents of PDF files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python excels in gaming and GUI development. 1) Game development uses Pygame, providing drawing, audio and other functions, which are suitable for creating 2D games. 2) GUI development can choose Tkinter or PyQt. Tkinter is simple and easy to use, PyQt has rich functions and is suitable for professional development.
 PHP and Python: Comparing Two Popular Programming Languages
Apr 14, 2025 am 12:13 AM
PHP and Python: Comparing Two Popular Programming Languages
Apr 14, 2025 am 12:13 AM
PHP and Python each have their own advantages, and choose according to project requirements. 1.PHP is suitable for web development, especially for rapid development and maintenance of websites. 2. Python is suitable for data science, machine learning and artificial intelligence, with concise syntax and suitable for beginners.
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
To maximize the efficiency of learning Python in a limited time, you can use Python's datetime, time, and schedule modules. 1. The datetime module is used to record and plan learning time. 2. The time module helps to set study and rest time. 3. The schedule module automatically arranges weekly learning tasks.
 Nginx SSL Certificate Update Debian Tutorial
Apr 13, 2025 am 07:21 AM
Nginx SSL Certificate Update Debian Tutorial
Apr 13, 2025 am 07:21 AM
This article will guide you on how to update your NginxSSL certificate on your Debian system. Step 1: Install Certbot First, make sure your system has certbot and python3-certbot-nginx packages installed. If not installed, please execute the following command: sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx Step 2: Obtain and configure the certificate Use the certbot command to obtain the Let'sEncrypt certificate and configure Nginx: sudocertbot--nginx Follow the prompts to select
 How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Configuring an HTTPS server on a Debian system involves several steps, including installing the necessary software, generating an SSL certificate, and configuring a web server (such as Apache or Nginx) to use an SSL certificate. Here is a basic guide, assuming you are using an ApacheWeb server. 1. Install the necessary software First, make sure your system is up to date and install Apache and OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
 GitLab's plug-in development guide on Debian
Apr 13, 2025 am 08:24 AM
GitLab's plug-in development guide on Debian
Apr 13, 2025 am 08:24 AM
Developing a GitLab plugin on Debian requires some specific steps and knowledge. Here is a basic guide to help you get started with this process. Installing GitLab First, you need to install GitLab on your Debian system. You can refer to the official installation manual of GitLab. Get API access token Before performing API integration, you need to get GitLab's API access token first. Open the GitLab dashboard, find the "AccessTokens" option in the user settings, and generate a new access token. Will be generated
 What service is apache
Apr 13, 2025 pm 12:06 PM
What service is apache
Apr 13, 2025 pm 12:06 PM
Apache is the hero behind the Internet. It is not only a web server, but also a powerful platform that supports huge traffic and provides dynamic content. It provides extremely high flexibility through a modular design, allowing for the expansion of various functions as needed. However, modularity also presents configuration and performance challenges that require careful management. Apache is suitable for server scenarios that require highly customizable and meet complex needs.
