

node+async implements concurrency control
This time I will bring you node async to control concurrency. What are the precautions for node async to control concurrency? The following is a practical case, let's take a look.
Objective
Create a lesson5 project and write code in it. The entry point of the code is app.js. When node app.js is called, it will output the titles of all topics on the CNode (https://cnodejs.org/) community homepage. Link and first comment in json format.
Note: Unlike the previous lesson, the number of concurrent connections needs to be controlled at 5. Output example:[
{
"title": "【公告】发招聘帖的同学留意一下这里",
"href": "http://cnodejs.org/topic/541ed2d05e28155f24676a12",
"comment1": "呵呵呵呵"
},
{
"title": "发布一款 Sublime Text 下的 JavaScript 语法高亮插件",
"href": "http://cnodejs.org/topic/54207e2efffeb6de3d61f68f",
"comment1": "沙发!"
}
]Knowledge points##Learn async(https://github.com/caolan/async ) usage of. Here is a detailed async demo: https://github.com/alsotang/async_demo
Learn to use async to control the number of concurrent connections.
Course content#lesson4’s code is actually imperfect. The reason why we say this is because in lesson4, we sent 40 concurrent requests at one time. You must know that, except for CNode, other websites may treat you as a malicious request because you send too many concurrent connections. , block your IP.
When we write a crawler, if there are 1,000 links to crawl, it is impossible to send out 1,000 concurrent links at the same time, right? We need to control the number of concurrencies, for example, 10 concurrencies, and then slowly capture these 1,000 links.
Doing this with async is easy.
This time we are going to introduce the
mapLimit(arr, limit, iterator, callback) interface of async. In addition, there is a commonly used interface for controlling the number of concurrent connections: queue(worker, concurrency). You can go to https://github.com/caolan/async#queueworker-concurrency for instructions. This time I won’t take you to crawl the website. Let’s focus on the knowledge point: controlling the number of concurrent connections.
By the way, another question is, when to use eventproxy and when to use async? Aren't they all used for asynchronous
process controlWhen you need to go to multiple sources (usually less than 10)
to summarize data, it is convenient to use eventproxy; when you need to use Use async when you want to queue, need to control the number of concurrency, or if you like functional programming thinking. Most scenarios are the former, so I personally use eventproxy most of the time. The main topic begins.
First, we forge a
fetchUrl(url, callback) function. The function of this function is that when you call it through <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">fetchUrl('http://www.baidu.com', function (err, content) {
// do something with `content`
});</pre><div class="contentsignin">Copy after login</div></div>, it will return http: //The page content of www.baidu.com returns.
Of course, the return content here is false, and the return delay is random. And when it is called, it will tell you how many places it is being called concurrently.
// 并发连接数的计数器
var concurrencyCount = 0;
var fetchUrl = function (url, callback) {
// delay 的值在 2000 以内,是个随机的整数
var delay = parseInt((Math.random() * 10000000) % 2000, 10);
concurrencyCount++;
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', url, ',耗时' + delay + '毫秒');
setTimeout(function () {
concurrencyCount--;
callback(null, url + ' html content');
}, delay);
};Let’s then forge a set of links
var urls = [];
for(var i = 0; i < 30; i++) {
urls.push('http://datasource_' + i);
}This set of links looks like this:
 Next, we use async.mapLimit to concurrently crawl and obtain results.
Next, we use async.mapLimit to concurrently crawl and obtain results.
async.mapLimit(urls, 5, function (url, callback) {
fetchUrl(url, callback);
}, function (err, result) {
console.log('final:');
console.log(result);
});The running output is like this:
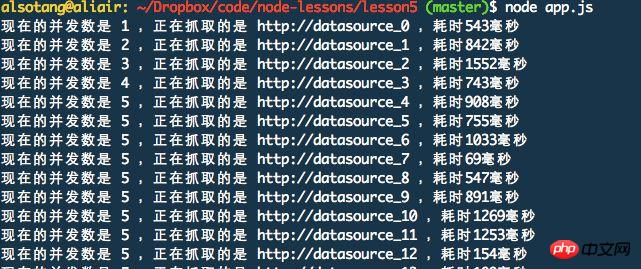 It can be seen that at the beginning, the number of concurrent links starts to grow from 1, and when it grows to 5, It will no longer increase. When one of the tasks is completed, continue fetching. The number of concurrent connections is always limited to 5.
It can be seen that at the beginning, the number of concurrent links starts to grow from 1, and when it grows to 5, It will no longer increase. When one of the tasks is completed, continue fetching. The number of concurrent connections is always limited to 5.
I believe you have mastered the method after reading the case in this article. For more exciting information, please pay attention to other related articles on the php Chinese website!
Recommended reading:
PHP quick implementation of array deduplication methodreact-navigation usage summary (with code)The above is the detailed content of node+async implements concurrency control. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 How to implement dual WeChat login on Huawei mobile phones?
Mar 24, 2024 am 11:27 AM
How to implement dual WeChat login on Huawei mobile phones?
Mar 24, 2024 am 11:27 AM
How to implement dual WeChat login on Huawei mobile phones? With the rise of social media, WeChat has become one of the indispensable communication tools in people's daily lives. However, many people may encounter a problem: logging into multiple WeChat accounts at the same time on the same mobile phone. For Huawei mobile phone users, it is not difficult to achieve dual WeChat login. This article will introduce how to achieve dual WeChat login on Huawei mobile phones. First of all, the EMUI system that comes with Huawei mobile phones provides a very convenient function - dual application opening. Through the application dual opening function, users can simultaneously
 How to implement the WeChat clone function on Huawei mobile phones
Mar 24, 2024 pm 06:03 PM
How to implement the WeChat clone function on Huawei mobile phones
Mar 24, 2024 pm 06:03 PM
How to implement the WeChat clone function on Huawei mobile phones With the popularity of social software and people's increasing emphasis on privacy and security, the WeChat clone function has gradually become the focus of people's attention. The WeChat clone function can help users log in to multiple WeChat accounts on the same mobile phone at the same time, making it easier to manage and use. It is not difficult to implement the WeChat clone function on Huawei mobile phones. You only need to follow the following steps. Step 1: Make sure that the mobile phone system version and WeChat version meet the requirements. First, make sure that your Huawei mobile phone system version has been updated to the latest version, as well as the WeChat App.
 Application of concurrency and coroutines in Golang API design
May 07, 2024 pm 06:51 PM
Application of concurrency and coroutines in Golang API design
May 07, 2024 pm 06:51 PM
Concurrency and coroutines are used in GoAPI design for: High-performance processing: Processing multiple requests simultaneously to improve performance. Asynchronous processing: Use coroutines to process tasks (such as sending emails) asynchronously, releasing the main thread. Stream processing: Use coroutines to efficiently process data streams (such as database reads).
 How can concurrency and multithreading of Java functions improve performance?
Apr 26, 2024 pm 04:15 PM
How can concurrency and multithreading of Java functions improve performance?
Apr 26, 2024 pm 04:15 PM
Concurrency and multithreading techniques using Java functions can improve application performance, including the following steps: Understand concurrency and multithreading concepts. Leverage Java's concurrency and multi-threading libraries such as ExecutorService and Callable. Practice cases such as multi-threaded matrix multiplication to greatly shorten execution time. Enjoy the advantages of increased application response speed and optimized processing efficiency brought by concurrency and multi-threading.
 How does Java database connection handle transactions and concurrency?
Apr 16, 2024 am 11:42 AM
How does Java database connection handle transactions and concurrency?
Apr 16, 2024 am 11:42 AM
Transactions ensure database data integrity, including atomicity, consistency, isolation, and durability. JDBC uses the Connection interface to provide transaction control (setAutoCommit, commit, rollback). Concurrency control mechanisms coordinate concurrent operations, using locks or optimistic/pessimistic concurrency control to achieve transaction isolation to prevent data inconsistencies.
 A guide to unit testing Go concurrent functions
May 03, 2024 am 10:54 AM
A guide to unit testing Go concurrent functions
May 03, 2024 am 10:54 AM
Unit testing concurrent functions is critical as this helps ensure their correct behavior in a concurrent environment. Fundamental principles such as mutual exclusion, synchronization, and isolation must be considered when testing concurrent functions. Concurrent functions can be unit tested by simulating, testing race conditions, and verifying results.
 How to use atomic classes in Java function concurrency and multi-threading?
Apr 28, 2024 pm 04:12 PM
How to use atomic classes in Java function concurrency and multi-threading?
Apr 28, 2024 pm 04:12 PM
Atomic classes are thread-safe classes in Java that provide uninterruptible operations and are crucial for ensuring data integrity in concurrent environments. Java provides the following atomic classes: AtomicIntegerAtomicLongAtomicReferenceAtomicBoolean These classes provide methods for getting, setting, and comparing values to ensure that the operation is atomic and will not be interrupted by threads. Atomic classes are useful when working with shared data and preventing data corruption, such as maintaining concurrent access to a shared counter.
 Golang process scheduling: Optimizing concurrent execution efficiency
Apr 03, 2024 pm 03:03 PM
Golang process scheduling: Optimizing concurrent execution efficiency
Apr 03, 2024 pm 03:03 PM
Go process scheduling uses a cooperative algorithm. Optimization methods include: using lightweight coroutines as much as possible to reasonably allocate coroutines to avoid blocking operations and use locks and synchronization primitives.
