

pytorch + visdom handles simple classification problems

This article mainly introduces how pytorch visdom handles simple classification problems. It has certain reference value. Now I share it with you. Friends in need can refer to it
##Environment
System: win 10Graphics card: gtx965m
cpu: i7-6700HQ
python 3.61
pytorch 0.3
Package reference
import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim
Data preparation
use_gpu = True ones = np.ones((500,2)) x1 = torch.normal(6*torch.from_numpy(ones),2) y1 = torch.zeros(500) x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2) y2 = y1 +1 x3 = torch.normal(-6*torch.from_numpy(ones),2) y3 = y1 +2 x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2) y4 = y1 +3 x = torch.cat((x1, x2, x3 ,x4), 0).float() y = torch.cat((y1, y2, y3, y4), ).long()
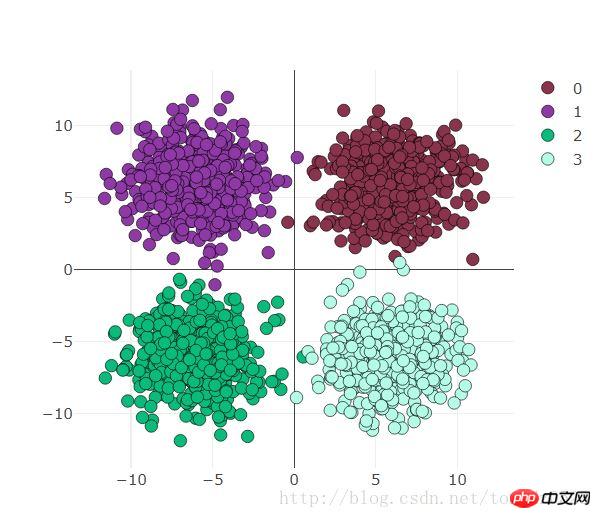
##visdom visualization preparationFirst create the windows that need to be observed
viz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
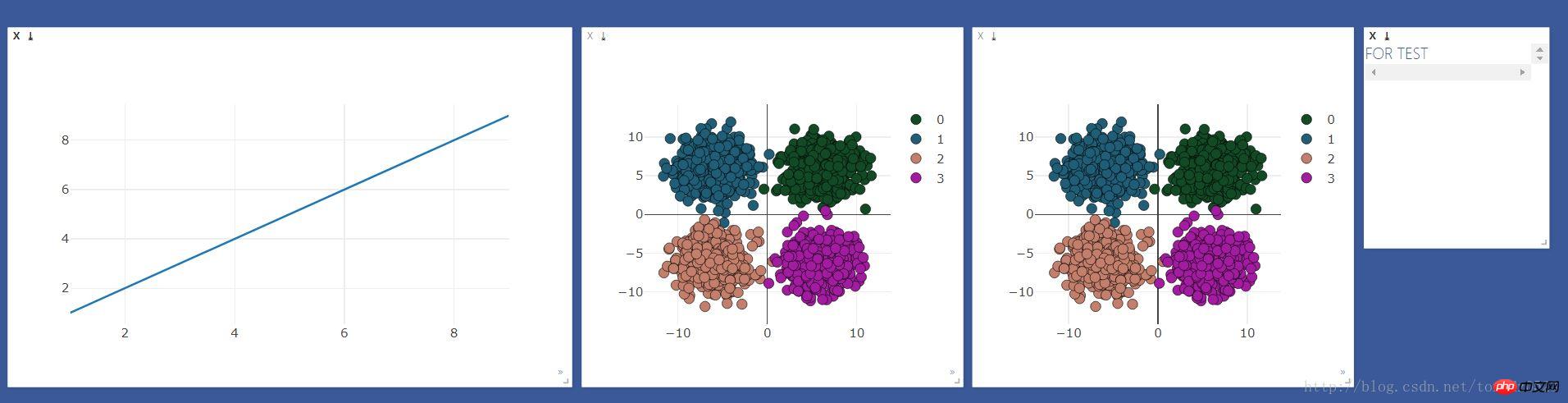
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)The effect is as follows:
Logistic regression processingInput 2, output 4
logstic = nn.Sequential( nn.Linear(2,4) )
Gpu or CPU selection:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")Optimizer and loss function:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
Training 2000 times:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()After training, observation and visualization:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
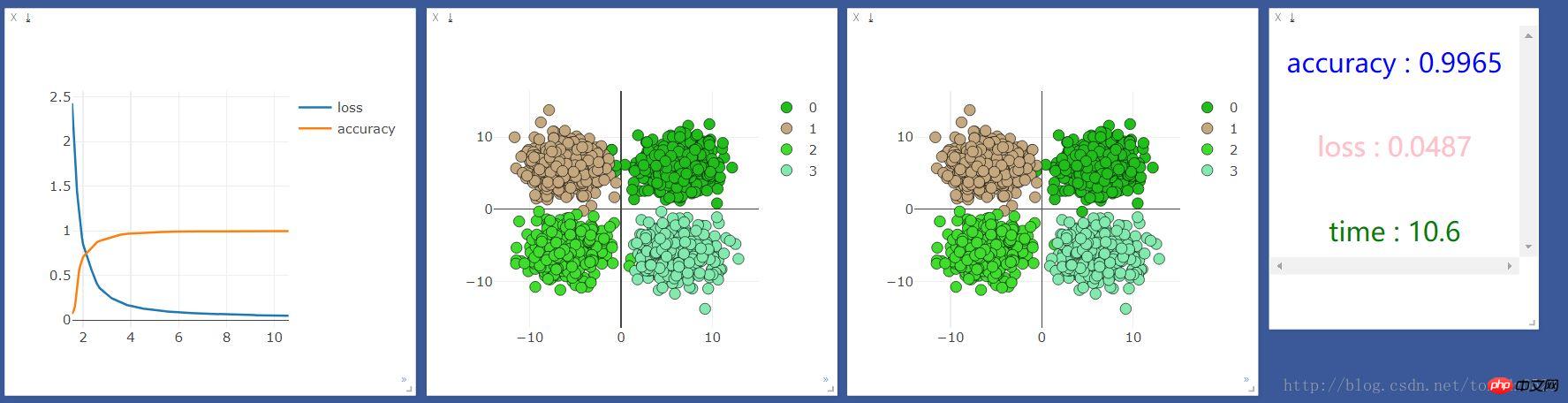
.format(accuracy,loss.data[0],time.time()-start_time),win =text)We first run it on the CPU once, and the results are as follows:
 Then run it with gpu, the results are as follows:
Then run it with gpu, the results are as follows:
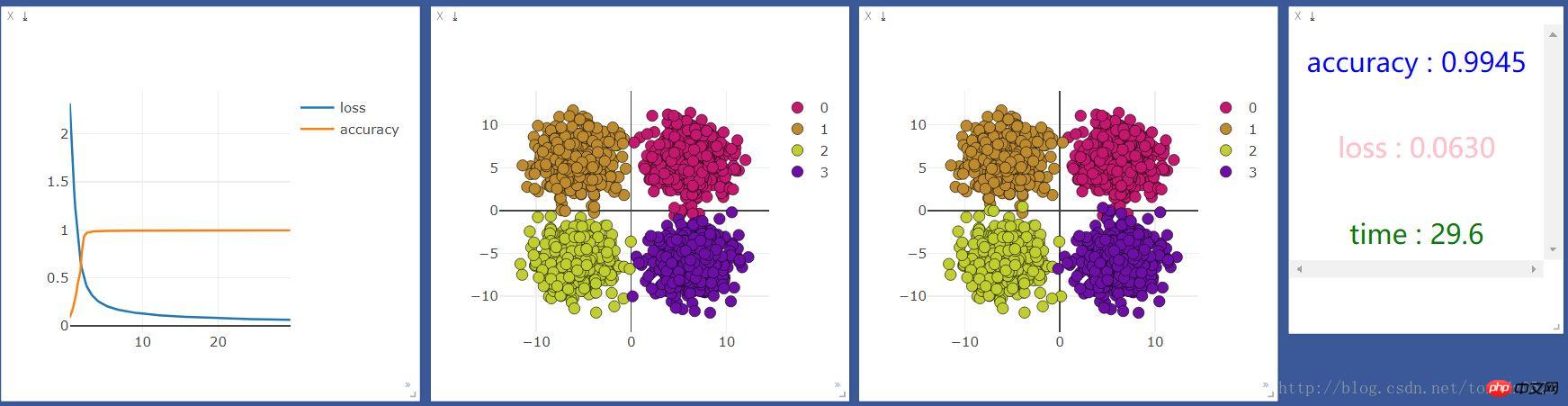 I found that cpu is much faster than gpu, but I I heard that machine learning should be faster with GPUs. I searched on Baidu and found the answer on Zhihu:
I found that cpu is much faster than gpu, but I I heard that machine learning should be faster with GPUs. I searched on Baidu and found the answer on Zhihu:
 My understanding is that GPUs are processing a lot of image recognition. The computing power of matrix operations and other aspects is much higher than that of the CPU. When processing some inputs and outputs with very few inputs and outputs, the CPU has the advantage.
My understanding is that GPUs are processing a lot of image recognition. The computing power of matrix operations and other aspects is much higher than that of the CPU. When processing some inputs and outputs with very few inputs and outputs, the CPU has the advantage.
net = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), #激活函数 nn.Linear(10, 4) )
Add a 10-unit neural layer and see if there will be any effect Improvement:
Use cpu:
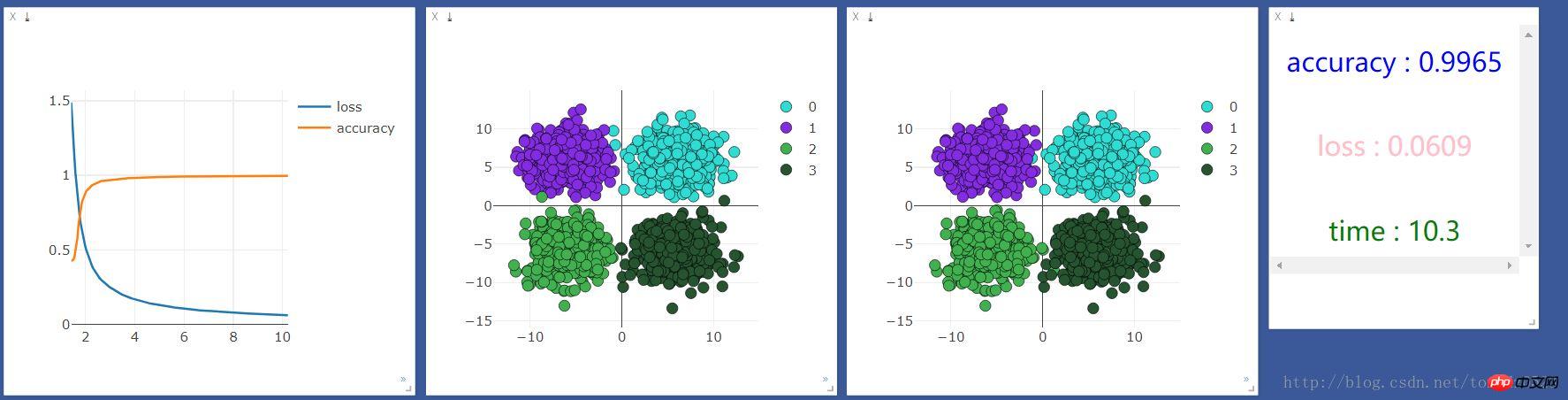
Use gpu:
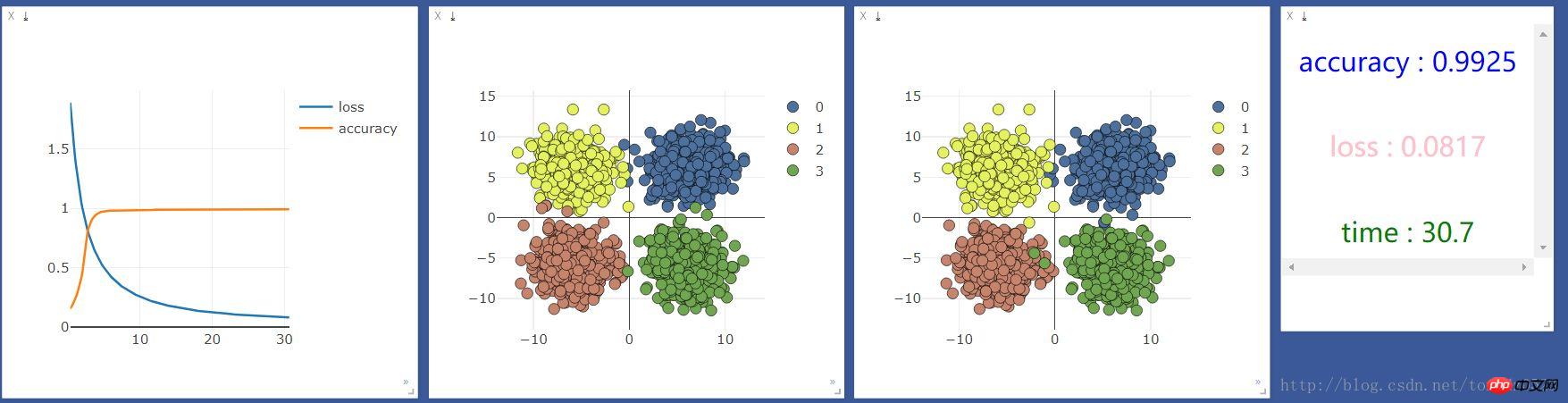 Comparative observation does not seem to make any difference. It seems that when dealing with simple classification problems (small input and output), neural layers and GPUs will not support machine learning.
Comparative observation does not seem to make any difference. It seems that when dealing with simple classification problems (small input and output), neural layers and GPUs will not support machine learning.
Related recommendations:
The above is the detailed content of pytorch + visdom handles simple classification problems. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 iFlytek: Huawei's Ascend 910B's capabilities are basically comparable to Nvidia's A100, and they are working together to create a new base for my country's general artificial intelligence
Oct 22, 2023 pm 06:13 PM
iFlytek: Huawei's Ascend 910B's capabilities are basically comparable to Nvidia's A100, and they are working together to create a new base for my country's general artificial intelligence
Oct 22, 2023 pm 06:13 PM
This site reported on October 22 that in the third quarter of this year, iFlytek achieved a net profit of 25.79 million yuan, a year-on-year decrease of 81.86%; the net profit in the first three quarters was 99.36 million yuan, a year-on-year decrease of 76.36%. Jiang Tao, Vice President of iFlytek, revealed at the Q3 performance briefing that iFlytek has launched a special research project with Huawei Shengteng in early 2023, and jointly developed a high-performance operator library with Huawei to jointly create a new base for China's general artificial intelligence, allowing domestic large-scale models to be used. The architecture is based on independently innovative software and hardware. He pointed out that the current capabilities of Huawei’s Ascend 910B are basically comparable to Nvidia’s A100. At the upcoming iFlytek 1024 Global Developer Festival, iFlytek and Huawei will make further joint announcements on the artificial intelligence computing power base. He also mentioned,
 Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
In natural language generation tasks, sampling method is a technique to obtain text output from a generative model. This article will discuss 5 common methods and implement them using PyTorch. 1. GreedyDecoding In greedy decoding, the generative model predicts the words of the output sequence based on the input sequence time step by time. At each time step, the model calculates the conditional probability distribution of each word, and then selects the word with the highest conditional probability as the output of the current time step. This word becomes the input to the next time step, and the generation process continues until some termination condition is met, such as a sequence of a specified length or a special end marker. The characteristic of GreedyDecoding is that each time the current conditional probability is the best
 The perfect combination of PyCharm and PyTorch: detailed installation and configuration steps
Feb 21, 2024 pm 12:00 PM
The perfect combination of PyCharm and PyTorch: detailed installation and configuration steps
Feb 21, 2024 pm 12:00 PM
PyCharm is a powerful integrated development environment (IDE), and PyTorch is a popular open source framework in the field of deep learning. In the field of machine learning and deep learning, using PyCharm and PyTorch for development can greatly improve development efficiency and code quality. This article will introduce in detail how to install and configure PyTorch in PyCharm, and attach specific code examples to help readers better utilize the powerful functions of these two. Step 1: Install PyCharm and Python
 Implementing noise removal diffusion model using PyTorch
Jan 14, 2024 pm 10:33 PM
Implementing noise removal diffusion model using PyTorch
Jan 14, 2024 pm 10:33 PM
Before we understand the working principle of the Denoising Diffusion Probabilistic Model (DDPM) in detail, let us first understand some of the development of generative artificial intelligence, which is also one of the basic research of DDPM. VAEVAE uses an encoder, a probabilistic latent space, and a decoder. During training, the encoder predicts the mean and variance of each image and samples these values from a Gaussian distribution. The result of the sampling is passed to the decoder, which converts the input image into a form similar to the output image. KL divergence is used to calculate the loss. A significant advantage of VAE is its ability to generate diverse images. In the sampling stage, one can directly sample from the Gaussian distribution and generate new images through the decoder. GAN has made great progress in variational autoencoders (VAEs) in just one year.
 Tutorial on installing PyCharm with PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial on installing PyCharm with PyTorch
Feb 24, 2024 am 10:09 AM
As a powerful deep learning framework, PyTorch is widely used in various machine learning projects. As a powerful Python integrated development environment, PyCharm can also provide good support when implementing deep learning tasks. This article will introduce in detail how to install PyTorch in PyCharm and provide specific code examples to help readers quickly get started using PyTorch for deep learning tasks. Step 1: Install PyCharm First, we need to make sure we have
 Deep Learning with PHP and PyTorch
Jun 19, 2023 pm 02:43 PM
Deep Learning with PHP and PyTorch
Jun 19, 2023 pm 02:43 PM
Deep learning is an important branch in the field of artificial intelligence and has received more and more attention in recent years. In order to be able to conduct deep learning research and applications, it is often necessary to use some deep learning frameworks to help achieve it. In this article, we will introduce how to use PHP and PyTorch for deep learning. 1. What is PyTorch? PyTorch is an open source machine learning framework developed by Facebook. It can help us quickly create and train deep learning models. PyTorc
 so fast! Recognize video speech into text in just a few minutes with less than 10 lines of code
Feb 27, 2024 pm 01:55 PM
so fast! Recognize video speech into text in just a few minutes with less than 10 lines of code
Feb 27, 2024 pm 01:55 PM
Hello everyone, I am Kite. Two years ago, the need to convert audio and video files into text content was difficult to achieve, but now it can be easily solved in just a few minutes. It is said that in order to obtain training data, some companies have fully crawled videos on short video platforms such as Douyin and Kuaishou, and then extracted the audio from the videos and converted them into text form to be used as training corpus for big data models. If you need to convert a video or audio file to text, you can try this open source solution available today. For example, you can search for the specific time points when dialogues in film and television programs appear. Without further ado, let’s get to the point. Whisper is OpenAI’s open source Whisper. Of course it is written in Python. It only requires a few simple installation packages.
 How to install pytorch in pycharm
Dec 08, 2023 pm 03:05 PM
How to install pytorch in pycharm
Dec 08, 2023 pm 03:05 PM
Installation steps: 1. Open PyCharm and create a new Python project; 2. In the bottom status bar of PyCharm, click the "Terminal" icon to open the terminal window; 3. In the terminal window, use the pip command to install PyTorch, according to the system and requirements, you can choose different installation methods; 4. After the installation is completed, you can write code in PyCharm and import the PyTorch library to use it.
