
mysql query uses the select command, combined with the limit and offset parameters to read records in the specified range. This article will introduce the reasons and optimization methods for excessive offset affecting performance during mysql queries.
1. Create the table
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT '姓名', `gender` tinyint(3) unsigned NOT NULL COMMENT '性别', PRIMARY KEY (`id`), KEY `gender` (`gender`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.Insert 1000000 records
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+| count(*) |
+----------+| 1000000 |
+----------+1 row in set (0.23 sec)
3. Current database version
mysql> select version(); +-----------+| version() | +-----------+| 5.6.24 | +-----------+1 row in set (0.01 sec)
1. When the offset is small
mysql> select * from member where gender=1 limit 10,1; +----+------------+--------+| id | name | gender | +----+------------+--------+| 26 | 509e279687 | 1 | +----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1; +-----+------------+--------+| id | name | gender | +-----+------------+--------+| 211 | 07c4cbca3a | 1 | +-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1; +------+------------+--------+| id | name | gender | +------+------------+--------+| 1975 | e95b8b6ca1 | 1 | +------+------------+--------+1 row in set (0.00 sec)
When the offset is small, the query speed is very slow Fast and efficient.
2. When the offset is large
mysql> select * from member where gender=1 limit 100000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 199798 | 540db8c5bc | 1 | +--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 399649 | 0b21fec4c6 | 1 | +--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.31 sec)
When the offset is large, efficiency problems will occur. As the offset increases, Execution efficiency decreases.
select * from member where gender=1 limit 300000,1;
Because the data table is InnoDB, according to the structure of the InnoDB index, The query process is:
Find the primary key value through the secondary index (find all ids with gender=1).
Then find the corresponding data block through the primary key index based on the found primary key value (find the corresponding data block content based on the id).
According to the value of offset, query the data of the primary key index 300001 times, and finally discard the previous 300000 entries and take out the last one.
But since the secondary index has found the primary key value, why do we need to use the primary key index to find the data block first, and then perform offset processing based on the offset value?
If after finding the primary key index, first perform offset offset processing, skip 300000 records, and then read the data block through the primary key index of the 300001th record, this can improve Efficiency.
If we only query the primary key, see what the difference is.
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.09 sec)
Obviously, if we query only the primary key, the execution efficiency is greatly improved compared to querying all fields.
Only querying the primary key
Because the secondary index has already found the primary key value, and the query only needs to read the primary key, so mysql will first perform the offset operation, and then read the data block based on the subsequent primary key index.
Need to query all fields
Because the secondary index only finds the primary key value, but the values of other fields need to be read from the data block to obtain. Therefore, mysql will first read the data block content, then perform the offset operation, and finally discard the previous data that needs to be skipped and return the subsequent data.
There is a buffer pool in InnoDB, which stores recently accessed data pages, including data pages and index pages.
In order to test, restart mysql first, and then check the contents of the buffer pool.
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; Empty set (0.04 sec)
You can see that after restarting, no data pages have been accessed.
Query all fields, and then check the contents of the buffer pool
mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 261 || PRIMARY | 1385 | +------------+----------+2 rows in set (0.06 sec)
It can be seen that there are ## in the member table in the buffer pool at this time #1385 data pages, 261 index pages.
Restart mysql to clear the buffer pool, and continue testing to query only the primary key
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.08 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 263 || PRIMARY | 13 | +------------+----------+2 rows in set (0.04 sec)
data pages, 263 index pages. Therefore, multiple I/O operations for accessing data blocks through the primary key index are reduced and execution efficiency is improved. Therefore, it can be confirmed that
The reason why excessive offset affects performance during mysql query is due to multiple I/O operations of accessing the data block through the primary key index. (Note that only InnoDB has this problem, and the MYISAM index structure is different from InnoDB. The secondary indexes point directly to data blocks, so there is no such problem).
InnoDB and MyISAM engine index structure comparison chart
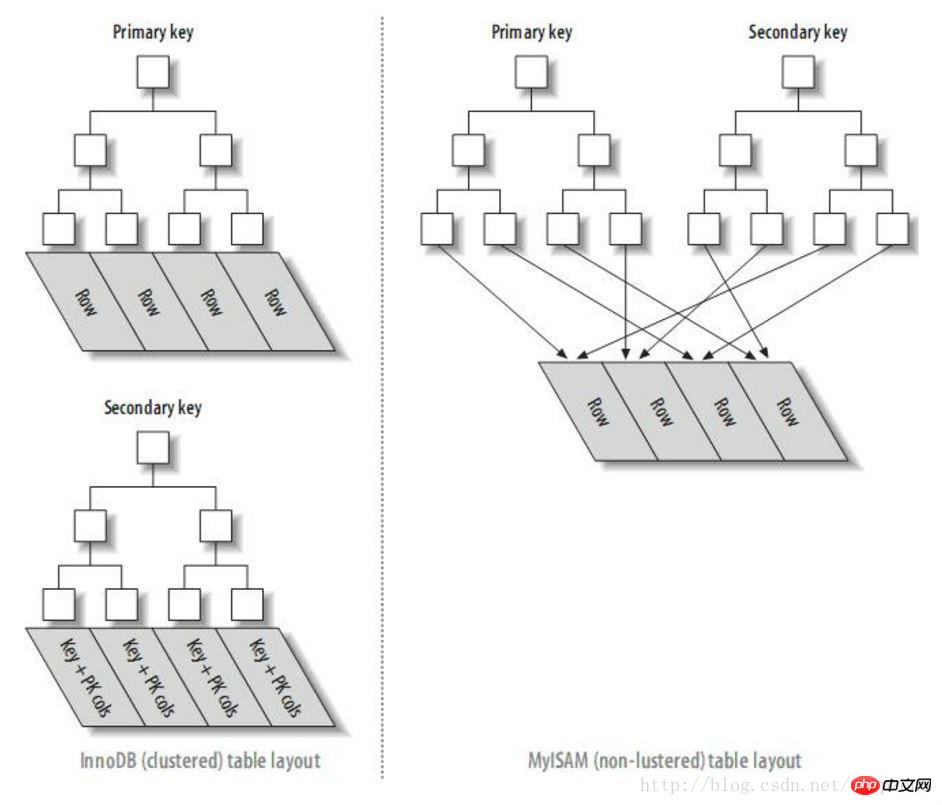
##Optimization method
Therefore, we first find out the offset primary key, and then query all the contents of the data block based on the primary key index to optimize.
mysql> select a.* from member as a inner join (select id from member where gender=1 limit 300000,1) as b on a.id=b.id; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.08 sec)
About the method of using regular PHP to remove width and height styles
Detailed explanation of file content deduplication and sorting
Interpretation of mysql case-sensitive configuration issues
The above is the detailed content of Detailed explanation of the reasons and optimization methods for excessive offset affecting performance during mysql query. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



