

NetEase Cloud music review crawling
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
https://music.163.com /#/song?id=", "28815250"
3. The HTML text obtained by the requests module needs to be converted into Python readable using the json.loads() method text, otherwise an error will be reported. This does not happen in jupyter notebook. 4. The replace() function can remove elements from the string. In this example, the newline character is changed to empty. The final display result is as follows: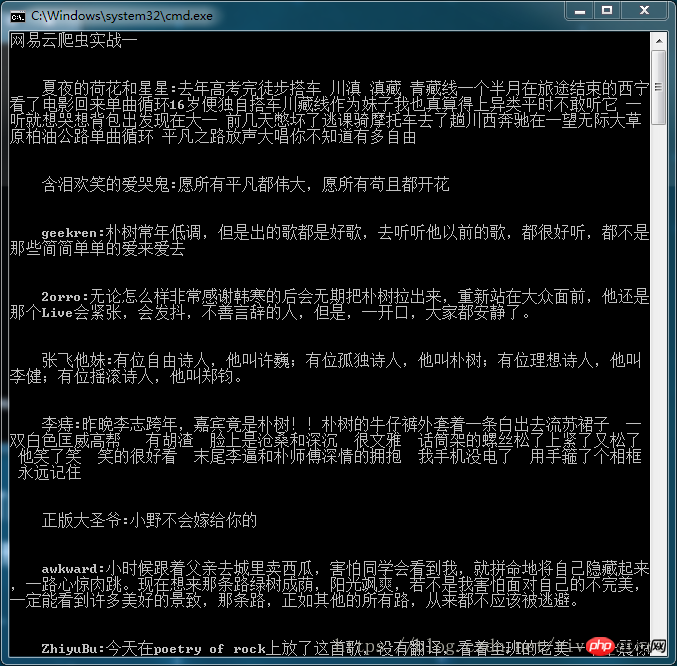
##This article introduces the relevant content of NetEase Cloud music review crawling, please Follow php Chinese website.
Related recommendations:
Simple PHP MySQL paging classTwo tree array constructors without recursionConvert HTML to Excel, and realize printing and downloading functionsThe above is the detailed content of NetEase Cloud music review crawling. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Metadata scraping using the New York Times API
Sep 02, 2023 pm 10:13 PM
Metadata scraping using the New York Times API
Sep 02, 2023 pm 10:13 PM
Introduction Last week, I wrote an introduction about scraping web pages to collect metadata, and mentioned that it was impossible to scrape the New York Times website. The New York Times paywall blocks your attempts to collect basic metadata. But there is a way to solve this problem using New York Times API. Recently I started building a community website on the Yii platform, which I will publish in a future tutorial. I want to be able to easily add links that are relevant to the content on my site. While people can easily paste URLs into forms, providing title and source information is time-consuming. So in today's tutorial I'm going to extend the scraping code I recently wrote to leverage the New York Times API to collect headlines when adding a New York Times link. Remember, I'm involved
 How to crawl and process data by calling API interface in PHP project?
Sep 05, 2023 am 08:41 AM
How to crawl and process data by calling API interface in PHP project?
Sep 05, 2023 am 08:41 AM
How to crawl and process data by calling API interface in PHP project? 1. Introduction In PHP projects, we often need to crawl data from other websites and process these data. Many websites provide API interfaces, and we can obtain data by calling these interfaces. This article will introduce how to use PHP to call the API interface to crawl and process data. 2. Obtain the URL and parameters of the API interface. Before starting, we need to obtain the URL of the target API interface and the required parameters.
 Vue development experience summary: tips for optimizing SEO and search engine crawling
Nov 22, 2023 am 10:56 AM
Vue development experience summary: tips for optimizing SEO and search engine crawling
Nov 22, 2023 am 10:56 AM
Summary of Vue development experience: Tips for optimizing SEO and search engine crawling. With the rapid development of the Internet, website SEO (SearchEngineOptimization, search engine optimization) has become more and more important. For websites developed using Vue, optimizing for SEO and search engine crawling is crucial. This article will summarize some Vue development experience and share some tips for optimizing SEO and search engine crawling. Using prerendering technology Vue
 How to use Scrapy to crawl Douban books and their ratings and comments?
Jun 22, 2023 am 10:21 AM
How to use Scrapy to crawl Douban books and their ratings and comments?
Jun 22, 2023 am 10:21 AM
With the development of the Internet, people increasingly rely on the Internet to obtain information. For book lovers, Douban Books has become an indispensable platform. In addition, Douban Books also provides a wealth of book ratings and reviews, allowing readers to understand a book more comprehensively. However, manually obtaining this information is tantamount to finding a needle in a haystack. At this time, we can use the Scrapy tool to crawl data. Scrapy is an open source web crawler framework based on Python, which can help us efficiently
 Scrapy in action: crawling Baidu news data
Jun 23, 2023 am 08:50 AM
Scrapy in action: crawling Baidu news data
Jun 23, 2023 am 08:50 AM
Scrapy in action: Crawling Baidu news data With the development of the Internet, the main way people obtain information has shifted from traditional media to the Internet, and people increasingly rely on the Internet to obtain news information. For researchers or analysts, a large amount of data is needed for analysis and research. Therefore, this article will introduce how to use Scrapy to crawl Baidu news data. Scrapy is an open source Python crawler framework that can crawl website data quickly and efficiently. Scrapy provides powerful web page parsing and crawling functions
 How to use PHP Goutte class library for web crawling and data extraction?
Aug 09, 2023 pm 02:16 PM
How to use PHP Goutte class library for web crawling and data extraction?
Aug 09, 2023 pm 02:16 PM
How to use the PHPGoutte class library for web crawling and data extraction? Overview: In the daily development process, we often need to obtain various data from the Internet, such as movie rankings, weather forecasts, etc. Web crawling is one of the common methods to obtain this data. In PHP development, we can use the Goutte class library to implement web crawling and data extraction functions. This article will introduce how to use the PHPGoutte class library to crawl web pages and extract data, and attach code examples. What is Gout
 Scrapy in action: crawling Douban movie data and rating popularity rankings
Jun 22, 2023 pm 01:49 PM
Scrapy in action: crawling Douban movie data and rating popularity rankings
Jun 22, 2023 pm 01:49 PM
Scrapy is an open source Python framework for scraping data quickly and efficiently. In this article, we will use Scrapy to crawl the data and rating popularity of Douban movies. Preparation First, we need to install Scrapy. You can install Scrapy by typing the following command on the command line: pipinstallscrapy Next, we will create a Scrapy project. At the command line, enter the following command: scrapystartproject
 How to use Scrapy to crawl Kugou Music songs?
Jun 22, 2023 pm 10:59 PM
How to use Scrapy to crawl Kugou Music songs?
Jun 22, 2023 pm 10:59 PM
With the development of the Internet, the amount of information on the Internet is increasing, and people need to crawl information from different websites to perform various analyzes and mining. Scrapy is a fully functional Python crawler framework that can automatically crawl website data and output it in a structured form. Kugou Music is one of the most popular online music platforms. Below I will introduce how to use Scrapy to crawl the song information of Kugou Music. 1. Install ScrapyScrapy is a framework based on the Python language, so
