

In fact, you can understand the index as a special directory. The following article mainly introduces you to the relevant information about the SQL Server index principle. The article introduces it in detail through sample code. It will be helpful for your study or The work has a certain reference and learning value. Friends who need it, please follow the editor to learn together
Preface
This article is I compiled my previous notes and used the index as an entry point to discuss relevant database knowledge (and modified it to make it easier for people to digest). Friends who have not been exposed to SQL Server for a long time can just read the following blue font, which is simple and useful to save time; if you are a friend with a good database foundation, you can read it all and welcome to discuss.
The concept of index
The purpose of index: Our data query and processing speed has become the standard for measuring the success or failure of application systems, and indexes are used to speed up data Processing speed is often the most commonly used optimization method.
What is an index: The index in the database is similar to the table of contents of a book. Using the table of contents in a book can quickly find the information you want without reading the entire book. In a database, database programs use indexes to retrieve data in a table without having to scan the entire table. The table of contents in the book is a list of words and the page numbers where each word is located, and the index in the database is a list of values in the table and the storage location of each value.
Pros and cons of indexes: Most of the overhead of query execution is I/O. One of the main goals of using indexes to improve performance is to avoid full table scans, because full table scans require reading every data of the table from disk. Page, if there is an index pointing to the data value, the query only needs to read the disk a few times. Therefore, reasonable use of indexes can speed up data queries. However, indexes do not always improve system performance. Indexed tables require more storage space in the database. The same commands used to add and delete data take longer to run and the processing time required to maintain the index will be longer. Therefore, we must use indexes rationally and update them in a timely manner to remove suboptimal indexes.
Indices are divided into clustered index and non-clustered index
The data of the table is stored in the data page (the PageType mark of the data page is 1). The SqlServer page is 8k. If the page is full, it will be opened. One page of storage. If the table has a clustered index, then the physical data one by one is stored in the page in ascending/descending order according to the size of the clustered index field. When the clustered index field is updated or data is inserted/deleted in the middle, the table data will be moved (causing a certain impact on performance) because it needs to maintain ascending/descending sorting.
Note that the primary key is only a clustered index by default. It can also be set to a non-clustered index or a clustered index on a non-primary key field. The entire table can only have one clustered index. .
An excellent clustered index field generally contains the following 4 characteristics:
(A). Auto-increment
is always at the end Increase records and reduce paging and index fragmentation.
(B). Not changed
Reduce data movement.
(C). Uniqueness
Uniqueness is the most ideal characteristic of any index, which can clarify the position of the index key value in the sorting.
More importantly, if the index key is unique, it can correctly point to the source data row RID in each record. If the clustered index key value is not unique, SqlServer needs to internally generate a uniquifier column combination as a clustered key to ensure the uniqueness of the "key value"; if the non-clustered index key value is not unique, a RID column (clustered index key or heap table) will be added. row pointer) to ensure the uniqueness of the "key value".
Thinking (can be skipped): The index "key value" is also guaranteed to be unique in non-leaf nodes. The reason should be to clarify the position of the index record in the non-leaf nodes. For example, there is a non-clustered index field Name2. There are many records of Name2='a' in the table, resulting in Name2='a' having multiple index records (nodes) on non-leaf nodes. At this time, insert Name2=' a' record, you can quickly determine which index record (node) to insert based on the RID of the non-leaf node and the RID of the new record. If there is no RID of the non-leaf node, you have to traverse all Name2=' Only the leaf nodes of a' can determine the position. In addition, when we select * from Table1 where Name2<='a', the returned data is sorted by the non-clustered index Name2 and RID. It is easy to understand that the returned data is sorted by the order of index storage here. This is the result of using the Name2 index in this SQL query. If the database query plan chooses to scan the table data directly due to the "critical point" problem, the returned data will be sorted by the order of the table data by default.
For "key value" uniqueness, for clustered indexes, the uniquifier column is only incremented when the index value is repeated. For non-clustered indexes, if uniqueness is not defined when creating the index, RID will be incremented in all records, even if the index value is unique; if uniqueness is defined when creating the index, RID will only be incremented at the leaf level, which is used to find source data rows, that is, bookmarks. Find operation.
(D). Small field length
The smaller the clustered index key length, one index page can accommodate more index records, thereby reducing the depth of the index B-tree structure. For example, a table with millions of records has an int clustered index and may only require a 3-level B-tree structure. If the clustered index is defined on a wider column (for example, the uniqueidentifier column requires 16 bytes), the depth of the index will increase to 4 levels. Any clustered index lookup requires 4 I/O operations (4 logical reads to be exact), instead of only 3 I/O operations.
Similarly, the non-clustered index will contain the clustered index key value. The smaller the clustered index key length, the smaller the non-clustered index record will be. One index page can accommodate more index records.
is also stored in pages (pages marked with PageType 2 are called index pages). For example, table T has established a non-clustered index Index_A. If table T has 100 pieces of data, then index Index_A will also have 100 pieces of data (100 pieces of leaf node data to be precise, and the index is a B-tree structure. If If the height of the tree is greater than 0, then there is root node page or intermediate node page data, and then the index data exceeds 100). If table T also has a non-clustered index Index_B, then Index_B also has at least 100 data, so the index is built more The more, the greater the cost.
Updating index fields, inserting a piece of data, and deleting a piece of data will all cause index maintenance and have a certain impact on performance. In different situations, the performance impact is different. For example, when you have a clustered index, the inserted data is all at the end, which will almost never cause data movement and has a small impact; if the inserted data is in the middle, it will generally cause data movement, and may cause paging and paging. Fragmentation, the impact will be slightly larger (if the inserted middle page has enough remaining space to accommodate the inserted data, and the position is at the end of the page, it will not cause data movement)
It is said that the index of SqlServer is a B-tree structure (it is assumed that you have a certain understanding of the B-tree structure), so what exactly is it? What does it look like? You can use Sql statements to view its logical presentation.
New query execution syntax: DBCC IND(Test,OrderBo,-1) --The OrderBo table of the Test library has 10,000 pieces of data and has a clustered index Id primary key field
(You might as well build a table yourself, with a clustered index field, insert 10,000 table data, and then execute this syntax to see. You will gain a lot. Seeing it is better than hearing it a hundred times)
Execution results :
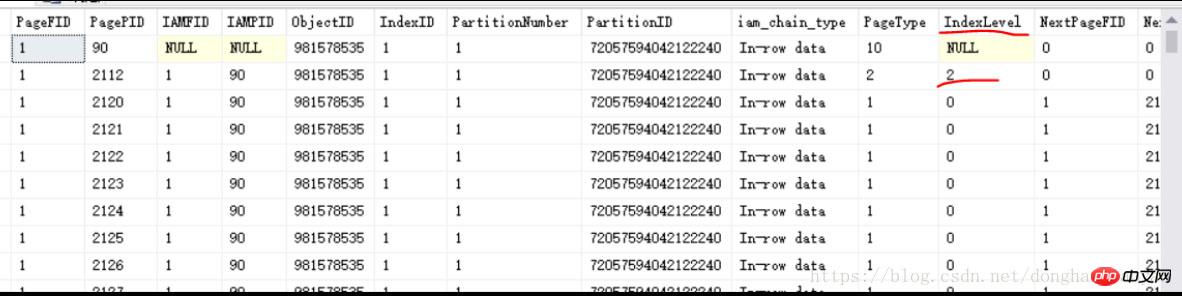
As shown in the picture above, you can see an index page 2112 with IndexLevel=2 (here it is the root node of the B-tree, and the largest IndexLevel is the root node, and downwards Children, sub-children...there is only one root page as the access entry point of the B-tree structure), indicating that there must be an index page with IndexLevel=1 and a leaf page with IndexLevel=0. Since this is a clustered index, the leaf page when IndexLevel=0 is the data page, which stores physical data one by one. As you can see in the figure above, the PageType of the row with IndexLevel=0 is equal to 1, which represents the data page. When talking about the clustered index in Chapter 1.1 above, PageType=1 is also mentioned; and if it is a non-clustered index, the leaf page with IndexLevel=0 , PageType is equal to 2, it is still an index page.
Similarly, we use the Sql command DBCC PAGE to take a look
-- DBCC TRACEON(3604,-1) DBCC PAGE(Test,1,2112,3) --根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询 DBCC PAGE(Test,1,2280,3) DBCC PAGE(Test,1,2448,3)

As shown in the figure above, page 2112 with IndexLevel=2 has two sub-nodes 2280 and 2448 with IndexLevel=1. There are sub-nodes under the sub-nodes. Each node is responsible for a different index key value range (i.e. In the "Id(key)" field in the above figure, the value in the first row is Null, which means the minimum value or the maximum value in reverse order). Is such a hierarchical relationship a B-tree structure, where IndexLevel is actually the height in the B-tree structure.
When SqlServer searches for a certain record in the index, it finds the leaf nodes from the root node downwards, because all data addresses have leaf nodes. This is actually one of the characteristics of the B-tree ( The characteristic of B-tree is that if the value you are looking for is found in a non-leaf node, it can be returned directly. Obviously SqlServer does not do this. To verify this, you can set statistics io on to turn on statistics, and then select to see the number of logical reads. ).
Since the leaf nodes will definitely be found, the index containing columns only need to be recorded at the leaf nodes, that is, there are no recorded containing columns for non-leaf nodes. See Chapter 3 below for "index containing columns".
The characteristics of the B tree (all data addresses have leaf nodes) are also conducive to interval query between value1 and value2. As long as you find value1 and value2 (at the leaf nodes), then string them together. The result was.
The SqlServer index structure is more like a B-tree. It is ultimately a hybrid version of a B-tree and a B-tree. The data structure is determined by people and is not necessarily a pure B-tree or a pure B-tree. B-Tree.
Talking about indexes, here is another "Index Contains Column" added since SqlServer2005 Functional, very practical.
For example, when querying data in a large report, the where condition uses the index field Name2, but the field to be selected is Name1. At this time, you can use "index included column" to include Name1 in In the index field Name2, query performance is greatly improved.
Syntax: Create [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) Include(Name1);
Next analyze why the index contains Columns can greatly improve performance. Still use the DBCC PAGE command to view a non-clustered index with index data containing columns:

As can be seen from the above figure, the containing column Name1 is also stored in the index in the data. Therefore, when the database uses the index field Name2 to locate a certain row to be searched, it can directly return the value of Name1 without having to locate it in the data page based on the RID (the picture above is the [HEAP RID (Key)] column) To get the value, it reduces the bookmark search. Of course, it doesn't matter when the query only returns one piece of data and only one bookmark search. If the data returned by the query is very large, you have to go to the data page to find the data and retrieve it. 1,000 records means 1,000 bookmark searches. You can imagine the performance consumption. Very large, at this time the value of "index contains columns" is greatly reflected.
Regarding a bookmark search, when the table has a clustered index (such as Id), it is similar to executing a select Name1 from Table1 where Id=1, using the clustered index key Id to search (the search method is the index Id B-tree structure search), and if the table does not have a clustered index, it is searched based on the data row pointer (composed of "file number 2byte: page number 4byte: slot number 2byte"). Clustered index keys and row pointers are generally referred to as RID (Row ID) pointers. From here we can think, If your table does not have a good clustered index field, it is recommended that the self-growing Id field be used as the primary key of the clustered index (redundant Id fields are also acceptable), which is consistent with self-growing and will not be changed. The uniqueness and small length make it a good choice for clustered indexes.
#Self-increasing ID is applicable in most cases. In special cases, it depends on the specific needs. There is also a flaw to consider in the self-increasing ID. When concurrently inserting records with a large amount of data in the table, it is conceivable that each thread has to insert to the last page, and competition and waiting will occur. To solve this situation, you can use uniqueidentifier type fields (16 bytes, I do not recommend using it) or hash partitioning (that is, one table is divided into multiple tables, it is normal to divide databases and tables in big data processing), etc. But I recommend optimizing your insert efficiency first (insert performance itself is very fast), and testing whether the number of concurrent inserts per second meets the production environment, so as to retain the simple, stable and efficient self-increasing ID method.
Self-increasing Id does not necessarily mean using the self-increasing one provided by the database. You can also write your own algorithm to generate an Id that is unique in concurrent situations (the general length at this time is bitint, 8 Byte shaping), this situation is suitable for the scenario where the Id field is required to be error-free during master-slave replication in a distributed database (in the general mode of master-slave replication, the Id of the master database increases according to the master database, and the slave database The Id also grows according to the slave library itself. If the master-slave replication is out of sync due to deadlock and other reasons, the Id of the slave library will not match the Id of the master library.) If the self-increasing Id is a redundant primary key, then there will be no impact if the master-slave database ID does not match the number.
In addition, the last column [Row Size] in the above picture also tells us that the size of the index column or the index containing column should not be too long, otherwise one page will not be able to accommodate several records. This greatly increases the number of index pages, and the space occupied by the index data is also greatly increased.
The above is the detailed content of The editor takes you through an in-depth analysis of the principles of SQL Server indexes. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



