
 Java
javaTutorial
Summary and compilation of Java interview questions from major companies (all)
Java
javaTutorial
Summary and compilation of Java interview questions from major companies (all)
Summary and compilation of Java interview questions from major companies (all)
ThreadLocal (copy of thread variables)
Synchronized implements memory sharing, and ThreadLocal maintains a local variable for each thread.
Use space for time, which is used for data isolation between threads, providing a copy for each thread that uses the variable. Each thread can independently change its own copy without conflicting with the copies of other threads. .
The ThreadLocal class maintains a Map to store a copy of the variables of each thread. The key of the element in the Map is the thread object, and the value is the variable copy of the corresponding thread.
ThreadLocal plays a huge role in Spring, and it appears in Bean, transaction management, task scheduling, AOP and other modules in the management Request scope.
Most beans in Spring can be declared as Singleton scope and encapsulated using ThreadLocal, so stateful beans can work normally in multi-threads in a singleton manner.
The Java virtual machine specification divides Java runtime data into six types.
1. Program counter: It is a data structure used to save the memory address of the currently executing program. Multi-threading of the Java virtual machine is achieved by switching threads in turn and allocating processor time. In order to return to the correct position after thread switching, each thread needs an independent program counter that does not affect each other. This area is " Thread private".
2.Java virtual machine stack: private to the thread, the same as the thread life cycle, used to store local variable tables, operation stacks, and method return values. The local variable table holds basic data types and object references.
3. Local method stack: It is very similar to the virtual machine stack, but it serves the Native methods used by the virtual machine.
4.Java heap: A memory area shared by all threads, where almost all object instances allocate memory.
5. Method area: An area shared by each thread, which stores class information loaded by the virtual machine, constants, static variables, and compiled code.
6. Runtime constant pool: represents the constant table in each class file at runtime. Includes several types of constants: compile-time numeric constants, method or field references.
"Can you talk about when and what did java GC do?"
When:
1. The new generation has one Eden area and two First, put the object into the Eden area. If there is insufficient space, put it into one of the survivor areas. If it still cannot fit, it will trigger a minor GC that occurs in the new generation and put the surviving objects into another survivor area. area, and then clear the memory of Eden and the previous survivor area. During a certain GC process, if objects are found that cannot be put down, these objects will be put into the old generation memory.
2. Large objects and long-term surviving objects directly enter the old area.
3. Every time minor GC is executed, the objects to be promoted to the old generation should be analyzed. If the size of these old objects that are about to go to the old area exceeds the remaining size of the old area, then perform a Full GC. To obtain as much space as possible in the senior area.
What is it: The object cannot be searched from GC Roots, and there is still no resurrected object after a mark cleanup.
What to do: Young generation: copy and clean; Old generation: mark-sweep and mark-compression algorithms; Permanent generation: stores classes in Java and the class loader itself that loads classes.
What are the GC Roots: 1. Objects referenced in the virtual machine stack 2. Objects referenced by static properties in the method area, objects referenced by constants 3. JNI (generally speaking Native methods) references in the local method stack Object.
Synchronized and Lock are both reentrant locks. When the same thread enters the synchronization code again, it can use the lock it has acquired.
Synchronized is a pessimistic locking mechanism and an exclusive lock. Locks.ReentrantLock does not lock every time but assumes there is no conflict and completes an operation. If it fails due to a conflict, it retries until it succeeds. ReentrantLock applicable scenarios
A thread needs to be interrupted while waiting for control of a lock
Some wait-notify needs to be processed separately , the Condition application in ReentrantLock can control which thread to notify, and the lock can be bound to multiple conditions.
With fair lock function, every incoming thread will wait in line.
StringBuffer is thread-safe. Every time a string is manipulated, String will generate a new object, but StringBuffer will not; StringBuilder is non-thread-safe.
fail- fast: mechanism is an error mechanism in java collection (Collection). When multiple threads operate on the contents of the same collection, a fail-fast event may occur.
For example: When a thread A traverses a collection through an iterator, if the content of the collection is changed by other threads; then when thread A accesses the collection, a ConcurrentModificationException exception will be thrown, resulting in fail-fast event
happens-before: If there is a happens-before relationship between two operations, then the result of the previous operation will be visible to the later operation.
1. Program sequence rules: Each operation in a thread happens-before any subsequent operation in the thread.
2. Monitor lock rules: Unlocking a monitor lock happens-before the subsequent locking of the monitor lock.
3. Volatile variable rules: writing to a volatile field happens-before any subsequent reading of this volatile field.
4. Transitivity: If A happens- before B, and B happens- before C, then A happens- before C.
5. Thread startup rules: The start() method of the Thread object happens- before every action of this thread.
Four differences between Volatile and Synchronized:
1 Different granularity, the former targets variables, the latter locks objects and classes
2 syn blocks, volatile threads do not block
3 syn guarantees three major Characteristics, volatile does not guarantee atomicity
4 syn compiler optimization, volatile does not optimize volatile has two characteristics:
1. Guarantee the visibility of this variable to all threads, refers to modification by one thread If the value of this variable is changed, the new value will be visible to other threads, but it is not multi-thread safe.
2. Disable instruction reordering optimization.
How Volatile ensures memory visibility:
1. When writing a volatile variable, JMM will refresh the shared variable in the local memory corresponding to the thread to the main Memory.
2. When reading a volatile variable, JMM will invalidate the local memory corresponding to the thread. The thread will next read the shared variable from main memory.
Synchronization: The completion of one task depends on another task. The dependent task can only be completed after waiting for the dependent task to complete.
Asynchronous: There is no need to wait for the dependent task to complete, but only to notify the dependent task of what work to complete. As long as the own task is completed, it is completed, and the dependent task will be notified back whether it is completed. (The characteristic of asynchronous is notification). Calling and texting are metaphors for synchronous and asynchronous operations.
Blocking: The CPU stops and waits for a slow operation to complete before completing other work.
Non-blocking: Non-blocking means that during the slow execution, the CPU does other work. After the slow execution is completed, the CPU will complete subsequent operations.
Non-blocking will cause an increase in thread switching. Whether increased CPU usage time can compensate for the switching cost of the system needs to be considered.
CAS (Compare And Swap) lock-free algorithm: CAS is an optimistic locking technology. When multiple threads try to use CAS to update the same variable at the same time, only one of the threads can update the value of the variable, and If other threads fail, the failed thread will not be suspended, but will be informed that the competition failed and can try again. CAS has 3 operands, the memory value V, the old expected value A, and the new value to be modified B. If and only if the expected value A and the memory value V are the same, modify the memory value V to B, otherwise do nothing.
The role of the thread pool: When the program starts, several threads are created to respond to processing. They are called thread pools, and the threads inside are called working threads
First: Reduce resource consumption. Reduce the cost of thread creation and destruction by reusing created threads.
Second: Improve response speed. When a task arrives, the task can be executed immediately without waiting for the thread to be created.
Third: Improve the manageability of threads.
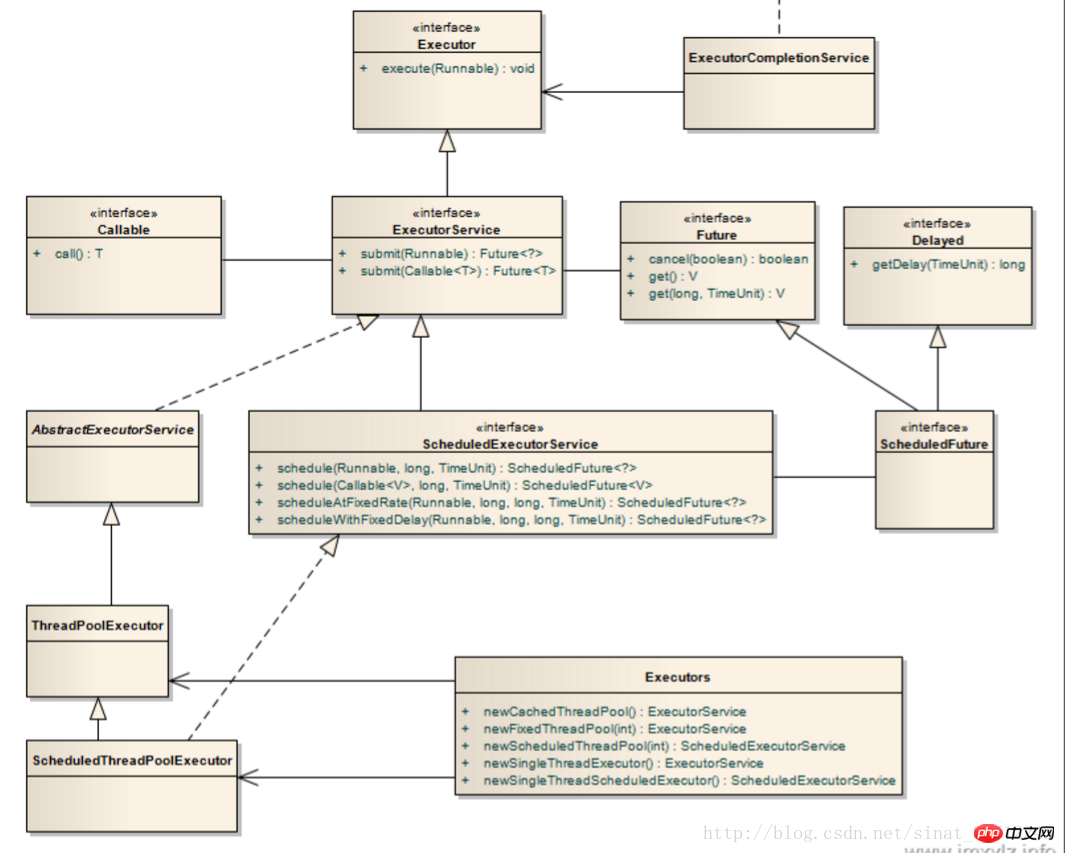
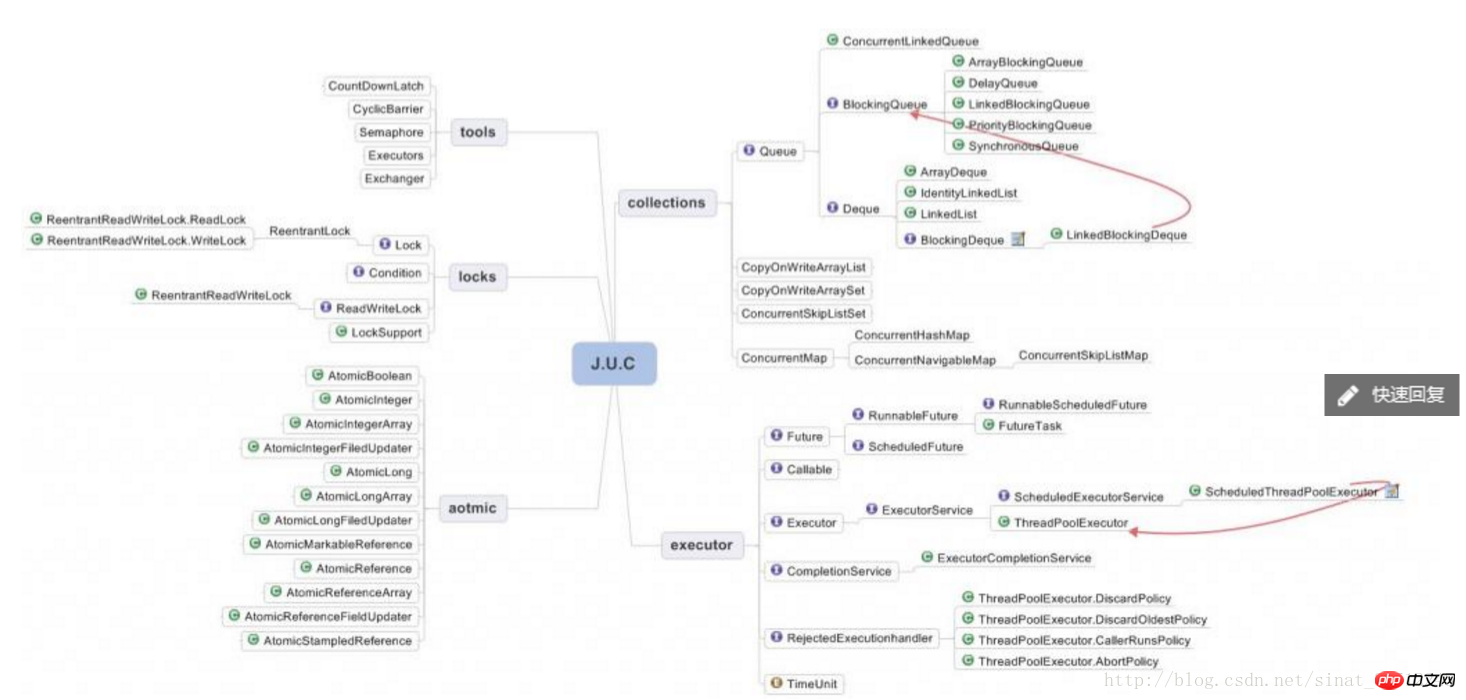
Commonly used thread pools: ExecutorService is the main implementation class, among which the commonly used ones are Executors.newSingleThreadPool(), newFixedThreadPool(), newcachedTheadPool(), newScheduledThreadPool().
Class loader working mechanism:
1. Loading: Import Java binary code into jvm and generate Class file.
2. Connection: a) Verification: Check the correctness of the loaded Class file data b) Preparation: Allocate storage space to the static variables of the class c) Parsing: Convert symbol references into direct references
3: Initialization : Perform initialization work on static variables, static methods and static code blocks of the class.
Parental delegation model: When the class loader receives a class loading request, it first delegates the request to the parent class loader to complete the user-defined loader->Application loader->Extension class loader->Startup class Loader.
Consistent hashing:
Memcahed cache:
Data structure: key, value pair
Usage methods: get, put and other methods
Redis data structure: String - string (key-value type)
Hash - dictionary (hashmap) Redis's hash structure allows you to modify only a certain attribute value just like updating an attribute in the database
List —List implements message queue
Set—Set utilizes uniqueness
Sorted Set—Ordered set can be sorted and data persistence can be achieved
In-depth analysis of java automatic boxing and unboxing
Talk about Java reflection mechanism
How to write an immutable class?
Index: B, B-, full-text index
Mysql's index is a data structure designed to enable the database to find data efficiently.
The commonly used data structure is B Tree. Each leaf node not only stores the relevant information of the index key but also adds pointers to adjacent leaf nodes. This forms a B Tree with sequential access pointers. Do this optimization The purpose is to improve the performance of access in different intervals.
When to use indexes:
Often appear in fields after group by, order by and distinct keywords
Often with other fields Tables to be connected should create indexes on the connection fields
Fields that often appear in the Where clause
often appear as Query the selected field
Spring IOC (Inversion of Control, Dependency Injection)
Spring supports three dependency injection methods, namely attribute (Setter method) injection, constructor injection and interface injection.
In Spring, the objects that make up the application and are managed by the Spring IOC container are called Beans.
Spring's IOC container instantiates beans and establishes dependencies between beans through the reflection mechanism.
Simply put, Bean is an object initialized, assembled and managed by the Spring IOC container.
The process of obtaining the Bean object is to first load the configuration file through Resource and start the IOC container, then obtain the bean object through the getBean method, and then call its method.
Spring Bean scope:
Singleton: There is only one shared Bean instance in the Spring IOC container, which is generally a Singleton scope.
Prototype: Each request will generate a new Bean instance.
Request: Each http request will generate a new Bean instance.
The common advantages of proxies: business classes only need to focus on the business logic itself, ensuring the reusability of business classes.
Java static proxy:
The proxy object and the target object implement the same interface. The target object is an attribute of the proxy object. In the specific interface implementation, the proxy object can add other business processing before and after calling the corresponding method of the target object. logic.
Disadvantages: One proxy class can only proxy one business class. If the business class adds methods, the corresponding proxy class must also add methods.
Java dynamic proxy:
Java dynamic proxy is to write a class to implement the InvocationHandler interface and override the Invoke method. In the Invoke method, enhanced processing logic can be written. Only when this public proxy class is running can it be clear what it wants. The proxy object can also implement the methods of the proxied class, and then perform enhancements when implementing the class methods.
Actually: Method of proxy object = Enhanced method of processing the proxy object
The difference between JDK and CGLIB generating dynamic proxy classes:
JDK dynamic proxy can only generate proxies for classes that implement interfaces (instantiate a class). At this time, the proxy object and the target object implement the same interface, and the target object is used as an attribute of the proxy object. In the specific interface implementation, other business processing logic can be added before and after calling the corresponding method of the target object.
CGLIB implements proxy for classes , mainly to generate a subclass of the specified class (without instantiating a class) and override the methods in it.
Spring AOP application scenarios
Performance testing, access control, log management, transactions, etc.
The default strategy is to use JDK dynamic proxy technology if the target class implements the interface. If the target object does not implement the interface, the CGLIB proxy will be used by default.
SpringMVC operating principle
Client requests are submitted to DispatcherServlet
The DispatcherServlet controller queries HandlerMapping, finds and distributes it to the specified Controller.
After the Controller calls the business logic processing, it returns to ModelAndView
DispatcherServlet queries one or more ViewResoler view parsers to find the view specified by ModelAndView
The view is responsible for displaying the results to the client
An Http request
DNS domain name resolution–> Initiating TCP three-way handshake–> ; Initiate an http request after establishing a TCP connection –> The server responds to the http request, and the browser gets the html code –> The browser parses the html code and requests the resources in the html code (such as javascript, css, pictures, etc.) –> Browse The server renders the page and presents it to the user
Design a storage system to store massive data: Design a logical layer called the "middle layer". In this layer, the massive data from the database is captured and made into a cache. It runs in the memory of the server. In the same way, when new data arrives, it is cached first and then finds a way to persist it in the database. This is a simple idea. The main step is load balancing, which distributes requests from different users to different processing nodes, then stores them in the cache and updates the data to the main database regularly. The reading and writing process uses a mechanism similar to optimistic locking, which can be read all the time (also when writing data), but there will be a version mark every time it is read. If the version read this time is lower than the cached version, it will Read the data again. This situation is rare and can be tolerated.
Session and Cookie: Cookies allow the server to track each client's visit, but these cookies must be returned for each client visit. If there are many cookies, the amount of data transmission between the client and the server will be increased invisibly.
Session solves this problem very well. Every time the same client interacts with the server, it stores the data to the server through Session. It does not need to return all cookie values every time, but Return an ID, a unique ID generated by the server for each client's first visit. The client only needs to return this ID. This ID is usually a cookie whose name is JSESSIONID. In this way, the server can use this ID to retrieve the KV value stored in the server.
Session and Cookie timeout issues, Cookie security issues
Distributed Session Framework
Configuration server, Zookeeper cluster management server can uniformly manage the configuration of all servers File
Shared Sessions are stored in a distributed cache, which can be written and read at any time, and the performance must be very good, such as Memcache and Tair.
Encapsulate a class that inherits from HttpSession, store the Session in this class and then store it in the distributed cache
Because Cookie cannot For cross-domain access, to achieve Session synchronization, Session IDs must be synchronized and written to different domain names.
Adapter mode: Adapt one interface to another interface. InputStreamReader in Java I/O adapts the Reader class to InputStream, thus achieving the accuracy of byte stream to character stream. Change.
Decorator mode: Maintain the original interface and enhance the original functions.
FileInputStream implements all interfaces of InputStream. BufferedInputStreams inherits from FileInputStream and is a specific decorator implementer that saves the content read by InputStream in memory to improve reading performance.
Spring transaction configuration method:
1. Pointcut information, used to locate business class methods that implement transaction aspects
2. Transaction attributes that control transaction behavior, these attributes include transaction isolation level, transaction Propagation behavior, timeout period, rollback rules.
Spring uses the aop/tx Schema namespace and @Transaction annotation technology to configure declarative things.
Mybatis
Every Mybatis application is centered on an instance of the SqlSessionFactory object. First, use a byte stream to read the configuration file through Resource, then create a SqlSessionFactory through the SqlSessionFactoryBuilder().build method, and then create a SqlSession to serve each database transaction through the SqlSessionFactory.openSession() method.
Experienced Mybatis initialization->Create SqlSession->Run SQL statements and return results in three processes
The difference between Servlet and Filter:
The whole process is: Filter pre-processes user requests Processing, then the request is handed over to the Servlet for processing and a response is generated, and finally the Filter post-processes the server response.
Filter has the following uses:
Filter can pre-process and post-process specific url requests and responses.
Intercept the client's HttpServletRequest before the HttpServletRequest reaches the Servlet.
Check HttpServletRequest as needed, and you can also modify the HttpServletRequest header and data.
Intercept HttpServletResponse before it reaches the client.
Check HttpServletResponse as needed, and you can also modify the HttpServletResponse header and data.
In fact, Filter and Servlet are very similar. The only difference is that Filter cannot directly generate a response to the user. In fact, the code in the doFilter() method in Filter is the common code extracted from the service() method of multiple Servlets. Better reuse can be achieved by using Filter.
Life cycle of Filter and Servlet:
1.Filter is initialized when the web server starts
2. If a Servlet is configured with 1, the Servlet is also initialized when Tomcat (Servlet container) starts .
3. If the Servlet is not configured 1, the Servlet will not be initialized when Tomcat starts, but will be initialized when the request comes.
4. Each time a request is made, Request will be initialized. After responding to the request, the request will be destroyed.
5.After Servlet is initialized, it will not be logged out as the request ends.
6. When Tomcat is closed, Servlet and Filter are logged out in turn.
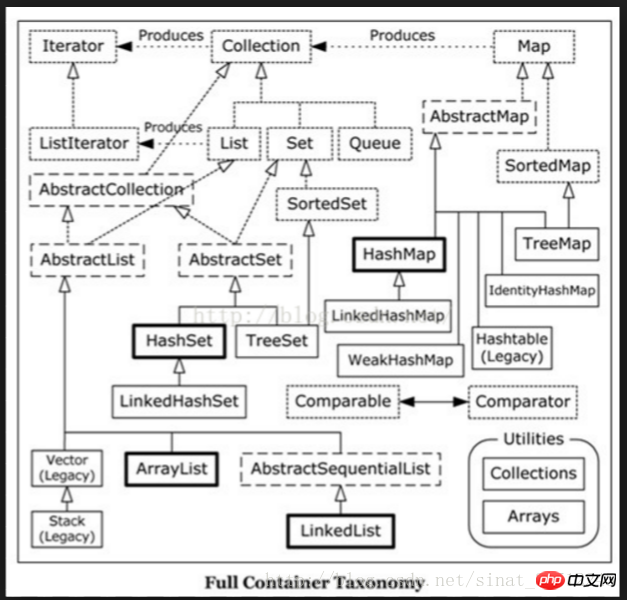
The difference between HashMap and HashTable.
1. HashMap is not thread-safe, and HashTable is thread-safe.
2. Both the keys and values of HashMap allow null values, but HashTable does not.
3. Due to thread safety issues, HashMap is more efficient than HashTable.
HashMap implementation mechanism:
Maintain an array in which each element is a linked list, and each node in the linked list is an Entry[] key-value pair data structure.
Implements the characteristics of array linked list, fast search, fast insertion and deletion.
For each key, its corresponding array index subscript is int i = hash(key.hashcode)&(len-1);
-
Each newly added node is placed at the beginning of the linked list, and then the newly added node points to the beginning of the original linked list
The difference between HashMap and TreeMap
HashMap Conflict
The difference between HashMap, ConcurrentHashMap and LinkedHashMap
ConcurrentHashMap использует технологию сегментации блокировок для обеспечения безопасности потоков.Технология сегментации блокировок: сначала разделите данные на сегменты для хранения, а затем назначьте блокировку каждому сегменту данных.Когда a Когда поток занимает блокировка для доступа к данным в одном сегменте, данные в других сегментах также могут быть доступны другим потокам
ConcurrentHashMap является потокобезопасным в каждом сегменте
LinkedHashMap поддерживает двойной связанный список, и данные в нем можно считывать в том порядке, в котором они записаны.
Сценарий приложения ConcurrentHashMap
1: Сценарий приложения ConcurrentHashMap Это имеет высокий уровень параллелизма, но не гарантирует потокобезопасности. Синхронизированные HashMap и HashMap блокируют весь контейнер. После блокировки ConcurrentHashMap не нужно блокировать весь контейнер. Ему нужно только заблокировать соответствующий сегмент, поэтому это можно гарантировать. Высокий одновременный синхронный доступ повышает эффективность.
2: Может быть записан в несколько потоков.
ConcurrentHashMap делит HashMap на несколько Segmenet
1. При получении блокировка не выполняется. Сначала найдите сегмент, а затем найдите головной узел для операции чтения. Значение является изменчивой переменной, поэтому в случае состояния гонки гарантированно будет прочитано последнее значение. Если прочитанное значение равно нулю, возможно, оно модифицируется, тогда вызывается функция ReadValueUnderLock и применяется блокировка, чтобы обеспечить что считанные данные верны.
2. Он будет заблокирован при Put и будет добавлен в начало хэш-цепочки.
3. Он также будет заблокирован при удалении. Поскольку следующий тип является окончательным и не может быть изменен, все узлы перед удаленным узлом должны быть скопированы.
4.ConcurrentHashMap позволяет одновременно выполнять несколько операций модификации. Ключевым моментом является использование технологии разделения блокировок. Он использует несколько блокировок для управления модификациями различных сегментов хеш-таблицы.
Сценарий приложения ConcurrentHashMap отличается высокой степенью параллелизма, но он не гарантирует потокобезопасности. Синхронизированные HashMap и HashTable блокируют весь контейнер. После блокировки ConcurrentHashMap не требуется блокировать весь контейнер. Ему достаточно только заблокировать Соответствующего сегмента достаточно, поэтому он может обеспечить высокий уровень одновременного синхронного доступа и повысить эффективность.
ConcurrentHashMap может гарантировать, что каждый вызов является атомарной операцией, но не гарантирует, что несколько вызовов также являются атомарными операциями.
Разница между Vector и ArrayList
ExecutorService service = Executors.... ExecutorService service = new ThreadPoolExecutor() Service ExecutorService = new ScheduledThreadPoolExecutor();
Анализ исходного кода ThreadPoolExecutor
Состояние самого пула потоков:
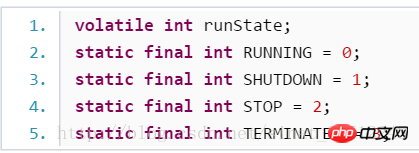



Имея данные, определенные выше, давайте посмотрим, как они реализованы внутри. Вся идея Дуга Ли суммирована в 5 предложениях:
- Если текущий размер пула PoolSize меньше, чем corePoolSize, создайте новый поток для выполнения задачи.
- Если текущий размер пула PoolSize больше, чем corePoolSize и очередь ожидания не заполнена, он войдет в очередь ожидания
Если текущий размер пула PoolSize больше, чем corePoolSize и больше, чем MaximumPoolSize, а очередь ожидания заполнена, для обработки задачи вызывается политика отклонения.
###Каждый поток в пуле потоков не завершается сразу после выполнения задачи. Вместо этого он проверяет, есть ли в очереди ожидания какие-либо задачи потока, которые необходимо выполнить. ожидает в KeepAliveTime. Если новых задач нет, поток завершится. ############Структура пакета Executor#############################CopyOnWriteArrayList: Блокировать при записи. При добавлении элемента скопируйте исходный контейнер, скопируйте его в новый контейнер, а затем запишите в новый контейнер. После записи укажите ссылку исходного контейнера на новый контейнер и прочитайте При чтении данных старый контейнер, можно выполнить одновременное чтение, но это слабая стратегия согласованности. ###Сценарии использования: CopyOnWriteArrayList подходит для использования в сценариях, где операций чтения гораздо больше, чем операций записи, например кэширования. ######Распространенные команды Linux: cd, cp, mv, rm, ps (процесс), tar, cat (просмотр содержимого), chmod, vim, find, ls######Необходимые условия для взаимоблокировки# # #Mutually exclude at least one resource in a non-shared state
Occupied and waiting
Non-preemption
Loop waiting
To solve the deadlock, the first one is deadlock prevention, which is to prevent the above four conditions from being established at the same time. The second is to allocate resources reasonably.
The third is to use the banker's algorithm. If the remaining amount of resources requested by the process can be satisfied by the operating system, then allocate them.
Inter-process communication method
Pipeline (pipe): Pipeline is a half-duplex communication method. Data can only flow in one direction, and it can only flow in one direction. Used between processes that are related. Process affinity usually refers to the parent-child process relationship.
Named pipe: Named pipe is also a half-duplex communication method, but it allows communication between unrelated processes.
Semaphore (semophore): A semaphore is a counter that can be used to control access to shared resources by multiple processes. It is often used as a locking mechanism to prevent other processes from accessing a shared resource when a process is accessing the resource. Therefore, it is mainly used as a means of synchronization between processes and between different threads within the same process.
Message queue (message queue): The message queue is a linked list of messages, which is stored in the kernel and identified by the message queue identifier. Message queues overcome the shortcomings of less signal transmission information, pipes can only carry unformatted byte streams, and limited buffer sizes.
Signal ( sinal ): Signal is a relatively complex communication method used to notify the receiving process that an event has occurred.
Shared memory (shared memory): Shared memory is to map a section of memory that can be accessed by other processes. This shared memory is created by one process, but can be accessed by multiple processes. Shared memory is the fastest IPC method and is specifically designed to address the inefficiencies of other inter-process communication methods. It is often used in conjunction with other communication mechanisms, such as semaphores, to achieve synchronization and communication between processes.
Socket (socket): The socket is also an inter-process communication mechanism. Unlike other communication mechanisms, it can be used for process communication between different machines.
The difference and connection between processes and threads
The process scheduling algorithm of the operating system
Detailed explanation of the hierarchical storage structure of the computer system
A database transaction refers to a single A sequence of operations performed by a logical unit of work.

MySQL database optimization summary
Common methods for MYSQL optimization
MySQL storage engine--The difference between MyISAM and InnoDB
About SQL database Paradigm
Hibernate's first-level cache is provided by Session, so it only exists in the life cycle of Session. When the program calls save(), update(), saveOrUpdate() and other methods and calls queries When interface list, filter, iterate, if the corresponding object does not yet exist in the Session cache, Hibernate will add the object to the first-level cache, and the cache will disappear when the Session is closed.
Hibernate's first-level cache is built-in to the Session. It cannot be uninstalled or configured in any way. The first-level cache is implemented using the key-value Map method. When caching entity objects, the object's The primary key ID is the key of the Map, and the entity object is the corresponding value.
Hibernate second-level cache: Put all obtained data objects into the second-level cache according to ID. Hibernate's second-level cache strategy is a cache strategy for ID queries. When data is deleted, updated, or added, the cache is updated at the same time.
The difference between processes and threads:
Process: Each process has independent code and data space (process context). Switching between processes will have a large overhead. A process contains 1–n threads.
Threads: Threads of the same type share code and data space. Each thread has an independent running stack and program counter (PC), and thread switching overhead is small.
Threads and processes are divided into five stages: creation, ready, running, blocking, and termination.
Multiple processes means that the operating system can run multiple tasks (programs) at the same time.
Multi-threading refers to the execution of multiple sequence flows in the same program.
In order to implement multi-threading in Java, there are three ways. One is to continue the Thread class, the other is to implement the Runable interface, and the other is to implement the Callable interface.
Can Switch use string as parameter?
a. Before Java 7, switch could only support byte, short, char, int or their corresponding encapsulation classes and Enum types. In Java 7, String support was added.
What are the public methods of Object?
a. Method equals tests whether two objects are equal
b. Method clone copies objects
c. Method getClass returns the Class object related to the current object
d. The methods notify, notifyall, and wait are all used for thread synchronization of a given object.
Four kinds of references in Java, strong and weak, and the scenarios used
a. Используйте мягкие и слабые ссылки для решения проблемы OOM: используйте HashMap, чтобы сохранить отношения сопоставления между путем изображения и мягкой ссылкой, связанной с соответствующим объектом изображения. Когда памяти недостаточно, JVM будет автоматически перерабатывать эти кэшированные объекты изображений, занимая занятое пространство, тем самым эффективно избегая проблемы OOM.
b.Реализовать кэширование объектов Java с помощью программно-доступных методов извлечения объектов: например, если мы создаем класс «Сотрудник», если нам нужно каждый раз запрашивать информацию о сотруднике. Даже если запрос был сделан всего несколько секунд назад, ему необходимо перестроить экземпляр, что занимает много времени. Мы можем объединить мягкие ссылки и HashMap. Сначала сохраните ссылку: укажите экземпляр объекта «Сотрудник» в форме мягкой ссылки и сохраните ссылку на HashMap. Ключ — это идентификатор сотрудника, а значение — мягкая ссылка этот объект., с другой стороны, состоит в том, чтобы извлечь ссылку и посмотреть, есть ли в кеше мягкая ссылка на экземпляр Сотрудника. Если да, получить ее из мягкой ссылки. Если мягкая ссылка отсутствует или экземпляр, полученный из мягкой ссылки, имеет значение NULL, перестройте экземпляр и сохраните мягкую ссылку во вновь созданном экземпляре.
c.Сильная ссылка: если объект имеет сильную ссылку, он не будет переработан сборщиком мусора. Даже если текущего объема памяти недостаточно, JVM не освободит его, а выдаст ошибку OutOfMemoryError, что приведет к аварийному завершению программы. Если вы хотите разорвать связь между строгой ссылкой и объектом, вы можете явно присвоить ссылке значение null, чтобы JVM переработала объект в подходящее время.
d.Мягкая ссылка: при использовании мягкой ссылки, если имеется достаточно места в памяти, мягкая ссылка может продолжать использоваться без повторного использования сборщиком мусора.Только когда памяти недостаточно, мягкая ссылка будет Переработано сборщиком мусора.
e.Слабая ссылка: объекты со слабыми ссылками имеют более короткий жизненный цикл. Потому что, когда JVM выполняет сбор мусора, как только будет найден объект слабой ссылки, слабая ссылка будет переработана независимо от того, достаточно ли текущего пространства памяти. Однако, поскольку сборщик мусора является потоком с низким приоритетом, он может оказаться не в состоянии быстро найти слабые ссылочные объекты.
f. Виртуальная ссылка: Как следует из названия, это только имя. Если объект содержит только виртуальную ссылку, то это эквивалентно отсутствию ссылки и может быть переработано сборщиком мусора в любое время. .
В чем разница между функцией Hashcode и равной?
a. Он также используется для определения равенства двух объектов. Существует два типа коллекций Java: список и набор. Среди них set не допускает повторной реализации элементов. Этот метод не позволяет повторять Если вы используете «равно» Для сравнения, если имеется 1000 элементов и вы создаете новый элемент, вам нужно вызвать «равно» 1000 раз, чтобы сравнить их один за другим, чтобы увидеть, являются ли они одним и тем же объектом, что значительно снизит эффективность. Хэш-код фактически возвращает адрес хранения объекта. Если в этой позиции нет элемента, элемент сохраняется непосредственно над ним. Если элемент уже существует в этой позиции, в это время вызывается метод равенства для сравнения с новым Если они одинаковы, они не будут сохранены и хешированы по другому адресу.
Смысл и разница между Override и Overload
a.Overload, как следует из названия, - это перезагрузка. Она может выражать полиморфизм класса. Возможно, функция может иметь одно и то же имя функции, но имена параметров, возвращаемые значения и типы не могут быть одинаковыми; другими словами, параметры, типы и возвращаемые значения могут быть изменены, но имя функции остается неизменным.
b. Это означает поездку (перезапись). Когда подкласс наследует родительский класс, подкласс может определить метод с тем же именем и параметрами, что и его родительский класс. Когда подкласс вызывает эту функцию, она будет вызвана автоматически. Методы подклассов, тогда как родительские классы эквивалентны переопределению (переопределению).
За подробностями можно перейти к примеру разбора разницы между перегрузкой и перезаписью (перезаписью) в C
Разница между абстрактными классами и интерфейсами
а Класс может только наследовать один класс, но может быть реализовано несколько интерфейсов
b. В абстрактных классах могут быть конструкторы, но не может быть конструкторов в интерфейсах
c. Все методы в абстрактных классах не обязательно должны быть быть абстрактным, вы можете реализовать некоторые базовые методы в абстрактных классах. Интерфейс требует, чтобы все методы были абстрактными
d. Абстрактные классы могут содержать статические методы, но интерфейсы не могут
e. Абстрактные классы могут иметь обычные переменные-члены, а интерфейсы могут. Не разрешено
Принципы и характеристики нескольких методов анализа XML: DOM, SAX, PULL
a.DOM: потребление памяти: сначала считываем все XML-документы в память, а затем используем DOM API для доступа к дереву структуру и получить данные. Это очень просто написать, но это потребляет много памяти. Если данные слишком велики, а телефон недостаточно мощный, телефон может напрямую выйти из строя
b.SAX: высокая эффективность анализа, небольшое использование памяти, управление событиями: проще говоря, он последовательно сканирует документ При сканировании Уведомляйте функцию обработки событий при достижении начала и конца документа (документа), начала и конца элемента (элемента), конца документа (документа) и т. д., и функция обработки событий будет выполните соответствующие действия, а затем продолжите такое же сканирование до конца документа.
c.PULL: Подобно SAX, он также управляем событиями. Мы можем вызвать его метод next(), чтобы получить следующее событие синтаксического анализа (то есть начальный документ, конечный документ, начальный тег, конечный тег). в определенный момент. Когда есть элемент, вы можете вызвать метод getAttributte() класса XmlPullParser, чтобы получить значение атрибута, или вы можете вызвать его nextText(), чтобы получить значение этого узла.
Разница между wait() и Sleep()
sleep исходит из класса Thread, а wait — из класса Object
В процессе вызова сна( ) метод, поток не будет освобожден от блокировки объекта. Поток, вызывающий метод ожидания, снимет блокировку объекта.
Sleep не отдает системные ресурсы после сна. Wait отдает системные ресурсы, и другие потоки могут занимать процессор.
sleep( миллисекунды) необходимо указать время сна. Он автоматически проснется, как только прибудет
Разница между кучей и стеком в JAVA, давайте поговорим о механизме памяти Java
a.Основные данные типы, переменные и ссылки на объекты размещаются в стеке
b. Память кучи используется для хранения объектов и массивов, созданных новыми
c. Переменные класса (статически модифицированные переменные), программа выделяет память для переменных класса в куче при загрузке. , адрес памяти в куче сохраняется в стеке
d. Переменные экземпляра: когда вы используете ключевое слово java new, система выделяет пространство для переменных Адрес памяти кучи преобразуется в длинную строку чисел с помощью хеш-алгоритма, чтобы представить «физическое расположение» этой переменной в куче. переменной экземпляра – при потере ссылки на переменную экземпляра она будет GC (сборщик мусора) Включена в перерабатываемый «список», но память в куче не освобождается сразу
e.Local переменные: от объявления в определенном методе или определенном сегменте кода (например, в цикле for) до его выполнения. Когда память выделяется в стеке, когда локальная переменная выходит за пределы области видимости, память немедленно освобождается
Принцип реализации полиморфизма JAVA
a.Абстрактно говоря, полиморфизм означает, что одни и те же сообщения могут вести себя по-разному в зависимости от того, кому они отправлены. (Отправка сообщения - это вызов функции)
b. Принцип реализации - динамическое связывание. Метод, вызываемый программой, динамически связывается во время выполнения. Отслеживая исходный код, можно обнаружить, что JVM находит подходящий параметр посредством автоматического преобразования.Метод.
Рекомендации по теме:
Краткий обзор вопросов и ответов на собеседовании по коллекции Java
Анализ порядка загрузки классов в Java (обычно используется в вопросы на собеседовании)
The above is the detailed content of Summary and compilation of Java interview questions from major companies (all). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Summary of front-end React interview questions in 2023 (Collection)
Aug 04, 2020 pm 05:33 PM
Summary of front-end React interview questions in 2023 (Collection)
Aug 04, 2020 pm 05:33 PM
As a well-known programming learning website, php Chinese website has compiled some React interview questions for you to help front-end developers prepare and clear React interview obstacles.
 A complete collection of selected Web front-end interview questions and answers in 2023 (Collection)
Apr 08, 2021 am 10:11 AM
A complete collection of selected Web front-end interview questions and answers in 2023 (Collection)
Apr 08, 2021 am 10:11 AM
This article summarizes some selected Web front-end interview questions worth collecting (with answers). It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.
 Five common Go language interview questions and answers
Jun 01, 2023 pm 08:10 PM
Five common Go language interview questions and answers
Jun 01, 2023 pm 08:10 PM
As a programming language that has become very popular in recent years, Go language has become a hot spot for interviews in many companies and enterprises. For beginners of the Go language, how to answer relevant questions during the interview process is a question worth exploring. Here are five common Go language interview questions and answers for beginners’ reference. Please introduce how the garbage collection mechanism of Go language works? The garbage collection mechanism of the Go language is based on the mark-sweep algorithm and the three-color marking algorithm. When the memory space in the Go program is not enough, the Go garbage collector
 Alibaba terminal: 1 million login requests per day, 8G memory, how to set JVM parameters?
Aug 15, 2023 pm 04:31 PM
Alibaba terminal: 1 million login requests per day, 8G memory, how to set JVM parameters?
Aug 15, 2023 pm 04:31 PM
Just last week, a classmate was asked this question during a technical interview with Alibaba Cloud: Assume a platform with 1 million login requests per day and a service node with 8G memory, how to set the JVM parameters? If you feel the answer is not ideal, come and ask me for review.
 50 Angular interview questions you must master (Collection)
Jul 23, 2021 am 10:12 AM
50 Angular interview questions you must master (Collection)
Jul 23, 2021 am 10:12 AM
This article will share with you 50 Angular interview questions that you must master. It will analyze these 50 interview questions from three parts: beginner, intermediate and advanced, and help you understand them thoroughly!
 Interviewer: How much do you know about high concurrency? Me: emmm...
Jul 26, 2023 pm 04:07 PM
Interviewer: How much do you know about high concurrency? Me: emmm...
Jul 26, 2023 pm 04:07 PM
High concurrency is an experience that almost every programmer wants to have. The reason is simple: as traffic increases, various technical problems will be encountered, such as interface response timeout, increased CPU load, frequent GC, deadlock, large data storage, etc. These problems can promote our Continuous improvement in technical depth.
 Sharing of Vue high-frequency interview questions in 2023 (with answer analysis)
Aug 01, 2022 pm 08:08 PM
Sharing of Vue high-frequency interview questions in 2023 (with answer analysis)
Aug 01, 2022 pm 08:08 PM
This article summarizes for you some selected vue high-frequency interview questions in 2023 (with answers) worth collecting. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.
 Summarize some common front-end interview questions (with answers) to help you consolidate your knowledge!
Jul 29, 2022 am 09:49 AM
Summarize some common front-end interview questions (with answers) to help you consolidate your knowledge!
Jul 29, 2022 am 09:49 AM
The main purpose of publishing articles is to consolidate my knowledge and become more proficient. It is all based on my own understanding and the information I searched online. If there is something wrong, I hope you can give me some advice. Below are some common interview questions that I have summarized. I will continue to update them in order to supervise myself.
