

Detailed introduction of distributed system core log (picture and text)

This article brings you a detailed introduction (pictures and text) about the distributed system core log. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to you.
What is a log?
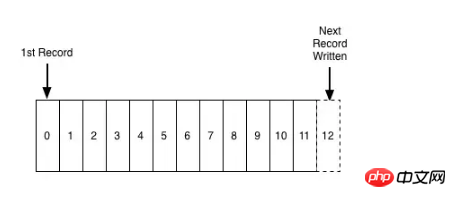
A log is a completely ordered sequence of records appended in chronological order. In fact, it is a special file format. The file is a word Section array, and the log here is a record data, but compared to the file, each record here is arranged in the relative order of time. It can be said that the log is the simplest storage model, and the reading is generally from From left to right, such as a message queue, the log file is generally written linearly, and the consumer reads sequentially starting from offset.
Due to the inherent characteristics of the log itself, records are inserted sequentially from left to right, which means that the records on the left are "older" than the records on the right, which means that we do not need to rely on the system clock. , this feature is very important for distributed systems.
Application of log
Application of log in database
The log is It is impossible to know when it will appear. It may be that the concept is too simple. In the database field, logs are more used to synchronize data and indexes when the system crashes, such as redo log in MySQL. Redo log is a disk-based data structure used to ensure data when the system hangs. The correctness and completeness of the system are also called write-ahead logs. For example, during the execution of a thing, the redo log will be written first, and then the actual changes will be applied. In this way, when the system recovers after a crash, it can be recreated based on the redo log. Put it back to restore the data (during the initialization process, there will be no client connection at this time). The log can also be used for synchronization between the database master and slave, because essentially, all operation records of the database have been written to the log. We only need to synchronize the log to the slave and replay it on the slave to achieve master-slave synchronization. Many other required components can also be implemented here. We can obtain all changes in the database by subscribing to the redo log, thereby implementing personalized business logic, such as auditing, cache synchronization, etc.
The application of logs in distributed systems
Distributed system services are essentially about state Changes here can be understood as state machines. Two independent processes (not dependent on the external environment, such as system clocks, external interfaces, etc.) given consistent inputs will produce consistent outputs and ultimately maintain a consistent state, and the log Because its inherent sequentiality does not depend on the system clock, it can be used to solve the problem of change orderliness.
We use this feature to solve many problems encountered in distributed systems. For example, in the standby node in RocketMQ, the main broker receives the client's request and records the log, and then synchronizes it to the slave in real time. The slave replays it locally. When the master hangs up, the slave can continue to process the request, such as rejecting the write request and continuing. Handle read requests. The log can not only record data, but also directly record operations, such as SQL statements.
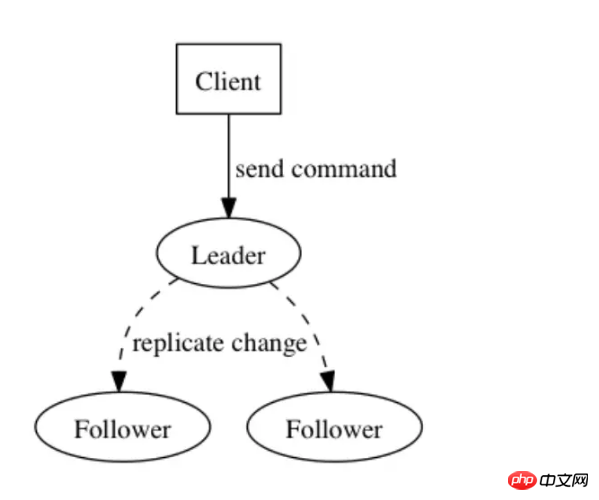
The log is a key data structure to solve the consistency problem. The log is like a sequence of operations. Each record represents an instruction. For example, the widely used Paxos and Raft protocols are It is a consistency protocol built based on logs.
Application of logs in Message Queue
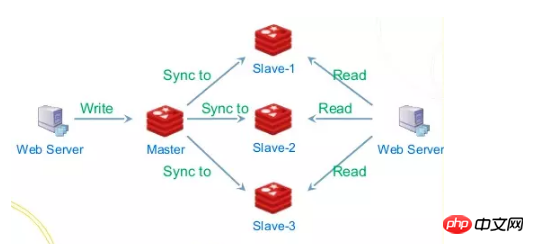
Logs can be easily used to process the inflow and outflow of data, and each data source can generate Your own log. The data sources here can come from various aspects, such as a certain event stream (page click, cache refresh reminder, database binlog change). We can centrally store the logs in a cluster, and subscribers can read the logs based on offset. For each record, apply your own changes based on the data and operations in each record.
The log here can be understood as a message queue, and the message queue can play the role of asynchronous decoupling and current limiting. Why do we say decoupling? Because for consumers and producers, the responsibilities of the two roles are very clear, they are responsible for producing messages and consuming messages, without caring about who is downstream or upstream, whether it is the change log of the database or a certain event. I don't need to care about a certain party at all. I only need to pay attention to the logs that interest me and each record in the logs.
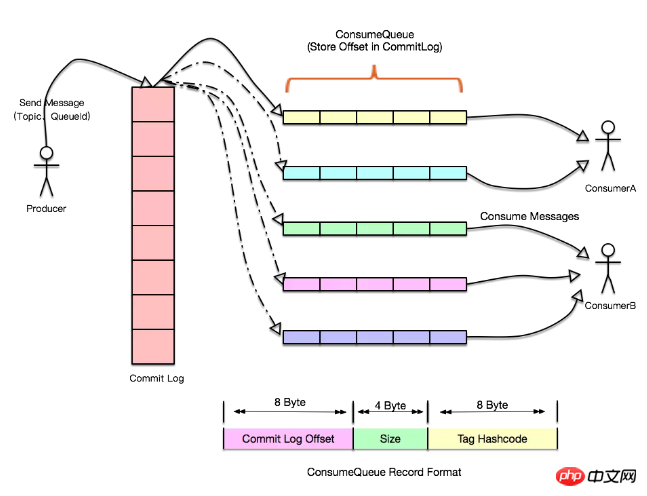
We know that the QPS of the database is certain, and upper-layer applications can generally expand horizontally. At this time, if there is a sudden request scenario like Double 11, the database will be overwhelmed, then we can introduce message queues and add each team database The operations are written to the log, and another application is responsible for consuming these log records and applying them to the database. Even if the database hangs, you can continue processing from the position of the last message when recovering (both RocketMQ and Kafka support Exactly Once semantics), even if the speed of the producer is different from the speed of the consumer, there will be no impact. The log plays the role of a buffer here. It can store all records in the log and synchronize to the slave node regularly, so that The backlog capacity of messages can be greatly improved because writing logs is processed by the master node. Read requests are divided into two types, one is tail-read, which means that the consumption speed can keep up with the writing speed. One type of read can go directly to the cache, and the other type is a consumer that lags behind the write request. This type can be read from the slave node, so that through IO isolation and some file policies that come with the operating system, such as pagecache, cache pre- Reading, etc., performance can be greatly improved.
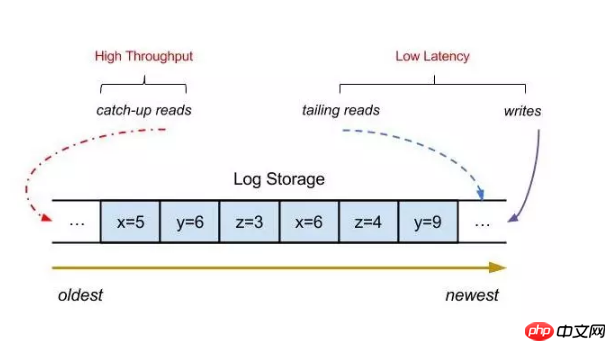
# Horizontal scalability is a very important feature in a distributed system. Problems that can be solved by adding machines are not a problem. So how to implement a message queue that can achieve horizontal expansion? If we have a stand-alone message queue, as the number of topics increases, IO, CPU, bandwidth, etc. will gradually become bottlenecks, and performance will slowly decrease. So how to proceed here? What about performance optimization?
1.topic/log sharding. Essentially, the messages written by topic are log records. As the number of writes increases, a single machine will slowly become a bottleneck. At this time We can divide a single topic into multiple sub-topics and assign each topic to a different machine. In this way, topics with a large amount of messages can be solved by adding machines, while some topics with a small amount of messages can be solved by adding machines. can be assigned to the same machine or not partitioned
2.group commit, for example, Kafka's producer client, when writing a message, first writes it to a local memory queue, and then writes the message according to each Partitions and nodes are summarized and submitted in batches. For the server side or broker side, this method can also be used, first writing to the pagecache, and then flushing the disk regularly. The flushing method can be determined according to the business. For example, financial services may adopt synchronization. The way to brush the disk.
3. Avoid useless data copies
4.IO isolation
The above is the detailed content of Detailed introduction of distributed system core log (picture and text). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What is event ID 6013 in win10?
Jan 09, 2024 am 10:09 AM
What is event ID 6013 in win10?
Jan 09, 2024 am 10:09 AM
The logs of win10 can help users understand the system usage in detail. Many users must have encountered log 6013 when looking for their own management logs. So what does this code mean? Let’s introduce it below. What is win10 log 6013: 1. This is a normal log. The information in this log does not mean that your computer has been restarted, but it indicates how long the system has been running since the last startup. This log will appear once every day at 12 o'clock sharp. How to check how long the system has been running? You can enter systeminfo in cmd. There is one line in it.
 Logger buffer size what is log used for
Mar 13, 2023 pm 04:27 PM
Logger buffer size what is log used for
Mar 13, 2023 pm 04:27 PM
The function is to provide engineers with feedback on usage information and records to facilitate problem analysis (used during development); because users themselves do not often generate upload logs, they are useless to users. The logging buffer is a small, temporary area used for short-term storage of change vectors for redo logs to be written to disk. A log buffer write to disk is a batch of change vectors from multiple transactions. Even so, the change vector in the log buffer is written to disk in near real-time, and when the session issues a COMMIT statement, the log buffer write operation is performed in real time.
 Troubleshooting Event 7034 Error Log Issues in Win10
Jan 11, 2024 pm 02:06 PM
Troubleshooting Event 7034 Error Log Issues in Win10
Jan 11, 2024 pm 02:06 PM
The logs of win10 can help users understand the system usage in detail. Many users must have seen a lot of error logs when looking for their own management logs. So how to solve them? Let’s take a look below. . How to solve win10 log event 7034: 1. Click "Start" to open "Control Panel" 2. Find "Administrative Tools" 3. Click "Services" 4. Find HDZBCommServiceForV2.0, right-click "Stop Service" and change it to "Manual Start "
 How to use logging in ThinkPHP6
Jun 20, 2023 am 08:37 AM
How to use logging in ThinkPHP6
Jun 20, 2023 am 08:37 AM
With the rapid development of the Internet and Web applications, log management is becoming more and more important. When developing web applications, how to find and locate problems is a very critical issue. A logging system is a very effective tool that can help us achieve these tasks. ThinkPHP6 provides a powerful logging system that can help application developers better manage and track events that occur in applications. This article will introduce how to use the logging system in ThinkPHP6 and how to utilize the logging system
 Detailed explanation of log viewing command in Linux system!
Mar 06, 2024 pm 03:55 PM
Detailed explanation of log viewing command in Linux system!
Mar 06, 2024 pm 03:55 PM
In Linux systems, you can use the following command to view the contents of the log file: tail command: The tail command is used to display the content at the end of the log file. It is a common command to view the latest log information. tail [option] [file name] Commonly used options include: -n: Specify the number of lines to be displayed, the default is 10 lines. -f: Monitor the file content in real time and automatically display the new content when the file is updated. Example: tail-n20logfile.txt#Display the last 20 lines of the logfile.txt file tail-flogfile.txt#Monitor the updated content of the logfile.txt file in real time head command: The head command is used to display the beginning of the log file
 Three commands to view logs in Linux
Jan 04, 2023 pm 02:00 PM
Three commands to view logs in Linux
Jan 04, 2023 pm 02:00 PM
The three commands for viewing logs in Linux are: 1. tail command, which can view changes in file content and log files in real time; 2. multitail command, which can monitor multiple log files at the same time; 3. less command, which can Changes to the log can be viewed quickly without cluttering the screen.
 Understand the meaning of event ID455 in win10 logs
Jan 12, 2024 pm 09:45 PM
Understand the meaning of event ID455 in win10 logs
Jan 12, 2024 pm 09:45 PM
The logs of win10 have a lot of rich content. Many users must have seen the event ID455 display error when looking for their own management logs. So what does it mean? Let’s take a look below. What is event ID455 in the win10 log: 1. ID455 is the error <error> that occurred in <file> when the information store opened the log file.
 How to view your medication log history in the Health app on iPhone
Nov 29, 2023 pm 08:46 PM
How to view your medication log history in the Health app on iPhone
Nov 29, 2023 pm 08:46 PM
iPhone lets you add medications to the Health app to track and manage the medications, vitamins and supplements you take every day. You can then log medications you've taken or skipped when you receive a notification on your device. After you log your medications, you can see how often you took or skipped them to help you track your health. In this post, we will guide you to view the log history of selected medications in the Health app on iPhone. A short guide on how to view your medication log history in the Health App: Go to the Health App>Browse>Medications>Medications>Select a Medication>Options&a
