

This article brings you an introduction to methods for optimizing and improving SQL performance. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to you.
Ø Simple performance optimization
Sql performance optimization is one of the important topics that database engineers must face in actual work. For some database engineers, it's almost the only proposition. In fact, in application scenarios that require fast response like WEB services, the performance of SQL directly determines whether the system can be used. Here we mainly introduce some optimization techniques that use SQL to execute faster and consume less memory. Today’s article only introduces one of them, and we will continue to update some other optimization methods in the future.
When strictly optimizing query performance, you must understand the functional characteristics of the database used. In addition, slow query speed is not only due to the SQL statement itself, but also due to poor memory allocation, unreasonable file structure and other reasons. Therefore, the method of optimizing SQL introduced here may not solve all performance problems, but it is true that many times the reason for poor query performance is the unreasonable way of writing SQL.
Ø Use efficient queries
In SQL, many times different codes can get the same results. In theory, different codes that produce the same results should have the same performance, but unfortunately, the execution plan generated by the query optimizer is greatly affected by the external structure of the code. Therefore, if you want to optimize query performance, you must know how to write code to make the optimizer perform more efficiently.
When the parameter is a subquery, it is very convenient to use EXISTS instead of IN
IN predicate, and the code is easy to understand, so it is used frequently. However, while being convenient, the IN predicate is in danger of becoming a bottleneck in performance optimization. If the code uses a lot of IN predicates, then generally just optimizing them can greatly improve performance.
If the parameter of IN is a numerical list such as "1, 2, 3", generally no special attention is needed. But if the parameter is a subquery, then you need to pay attention.
In most cases, the results returned by [NOT]IN and [NOT]EXISTS are the same. But when both are used for subqueries, EXISTS will be faster.
Let’s look at an example:
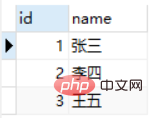
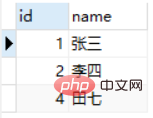
We try to find out from the Class_A table employees who also exist in the Class_B table. The following two SQL statements return the same results, but the SQL statement using EXISTS is faster.
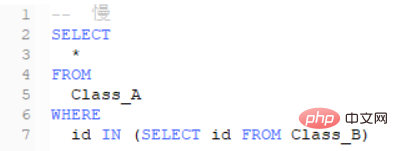

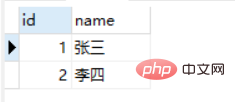
Both results are as follows:
There are two reasons why it is faster when using EXISTS.
a) If an index is established on the connection column (id), then there is no need to query the actual table when querying Class_B, only the index.
b) If EXISTS is used, the query will be terminated as long as a row of data meets the conditions, and there is no need to scan the entire table like when using IN. Same goes for NOT EXISTS at this point.
When the parameter of IN is a subquery, the database will first execute the subquery, then store the results in a temporary work table (inline view), and then scan the entire view. In many cases this approach is very resource intensive. Using EXISTS, the database will not generate temporary work tables.
But from the perspective of code readability, IN is better than EXISTS. The code looks more clear and easy to understand when using IN. Therefore, if you are sure that you can get results quickly using IN, there is no need to change it to EXISTS.
Moreover, many databases have recently tried to improve the performance of IN. Maybe one day in the future, IN can achieve the same performance as EXISTS no matter which database it is on.
When the parameter is a subquery, use connection instead of IN
To improve the performance of IN, in addition to using EXISTS, you can also use connection. The previous query statement can be "flattened" as follows.

This writing method can at least use the index on the "id" column of a table. Moreover, because there is no subquery, the database will not generate an intermediate table. It's hard to say which one is better than EXISTS, but if there are no indexes, then maybe EXISTS will be slightly better than joins. And it can be seen from many queries that in some cases using EXISTS is more appropriate than using connections.
The above is the detailed content of Introduction to methods for optimizing and improving SQL performance. For more information, please follow other related articles on the PHP Chinese website!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



