

Introduction to the method of using Jsoup to implement crawler technology

This article brings you an introduction to the method of using Jsoup to implement crawler technology. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to you.
1. Brief description of Jsoup
There are many crawler frameworks supported in Java, such as WebMagic, Spider, Jsoup, etc. Today we use Jsoup to implement a simple crawler program.
Jsoup has a very convenient API to process html documents, such as referring to the document traversal method of DOM objects, referring to the usage of CSS selectors, etc., so we can use Jsoup to quickly master the method of crawling page data. Skill.
2. Quick start
1) Write an HTML page

The product information of the table in the page is ours The data to crawl. Among them, the attributes are the product name of the pname class, and the product pictures belonging to the pimg class.
2) Use HttpClient to read HTML pages
HttpClient is a tool for processing Http protocol data. It can be used to read HTML pages into java programs as input streams. You can download the HttpClient jar package from http://hc.apache.org/.

3) Use Jsoup to parse html string
By introducing the Jsoup tool, directly call the parse method to parse a string describing the content of the html page to obtain A Document object. The Document object obtains the specified content on the html page by operating the DOM tree. For related APIs, please refer to the Jsoup official documentation: https://jsoup.org/cookbook/
Below we use Jsoup to obtain the product name and price information specified in the above html.
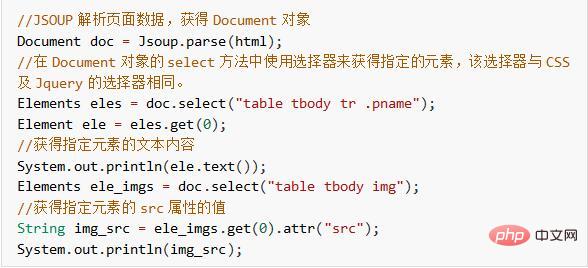
So far, we have implemented the function of using HttpClient Jsoup to crawl HTML page data. Next, we make the effect more intuitive, such as saving the crawled data to the database and saving the images to the server.
3. Save the crawled page data
1) Save ordinary data to the database
Encapsulate the crawled data into entity beans , and stored in the database.
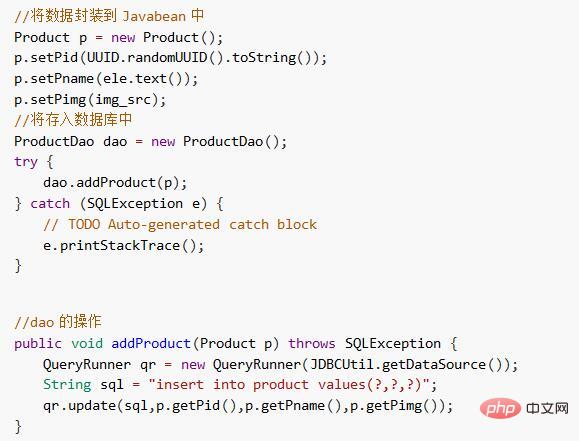
#2) Save the picture to the server
Save the picture to the server locally by downloading the picture directly.

4. Summary
This case simply implements the use of HttpClient Jsoup to crawl network data. There are many other things about the crawler technology itself. The places worth digging into will be explained to you later.
The above is the detailed content of Introduction to the method of using Jsoup to implement crawler technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Top 4 JavaScript Frameworks in 2025: React, Angular, Vue, Svelte
Mar 07, 2025 pm 06:09 PM
Top 4 JavaScript Frameworks in 2025: React, Angular, Vue, Svelte
Mar 07, 2025 pm 06:09 PM
This article analyzes the top four JavaScript frameworks (React, Angular, Vue, Svelte) in 2025, comparing their performance, scalability, and future prospects. While all remain dominant due to strong communities and ecosystems, their relative popul
 Spring Boot SnakeYAML 2.0 CVE-2022-1471 Issue Fixed
Mar 07, 2025 pm 05:52 PM
Spring Boot SnakeYAML 2.0 CVE-2022-1471 Issue Fixed
Mar 07, 2025 pm 05:52 PM
This article addresses the CVE-2022-1471 vulnerability in SnakeYAML, a critical flaw allowing remote code execution. It details how upgrading Spring Boot applications to SnakeYAML 1.33 or later mitigates this risk, emphasizing that dependency updat
 How do I implement multi-level caching in Java applications using libraries like Caffeine or Guava Cache?
Mar 17, 2025 pm 05:44 PM
How do I implement multi-level caching in Java applications using libraries like Caffeine or Guava Cache?
Mar 17, 2025 pm 05:44 PM
The article discusses implementing multi-level caching in Java using Caffeine and Guava Cache to enhance application performance. It covers setup, integration, and performance benefits, along with configuration and eviction policy management best pra
 How does Java's classloading mechanism work, including different classloaders and their delegation models?
Mar 17, 2025 pm 05:35 PM
How does Java's classloading mechanism work, including different classloaders and their delegation models?
Mar 17, 2025 pm 05:35 PM
Java's classloading involves loading, linking, and initializing classes using a hierarchical system with Bootstrap, Extension, and Application classloaders. The parent delegation model ensures core classes are loaded first, affecting custom class loa
 Node.js 20: Key Performance Boosts and New Features
Mar 07, 2025 pm 06:12 PM
Node.js 20: Key Performance Boosts and New Features
Mar 07, 2025 pm 06:12 PM
Node.js 20 significantly enhances performance via V8 engine improvements, notably faster garbage collection and I/O. New features include better WebAssembly support and refined debugging tools, boosting developer productivity and application speed.
 Iceberg: The Future of Data Lake Tables
Mar 07, 2025 pm 06:31 PM
Iceberg: The Future of Data Lake Tables
Mar 07, 2025 pm 06:31 PM
Iceberg, an open table format for large analytical datasets, improves data lake performance and scalability. It addresses limitations of Parquet/ORC through internal metadata management, enabling efficient schema evolution, time travel, concurrent w
 How to Share Data Between Steps in Cucumber
Mar 07, 2025 pm 05:55 PM
How to Share Data Between Steps in Cucumber
Mar 07, 2025 pm 05:55 PM
This article explores methods for sharing data between Cucumber steps, comparing scenario context, global variables, argument passing, and data structures. It emphasizes best practices for maintainability, including concise context use, descriptive
 How can I implement functional programming techniques in Java?
Mar 11, 2025 pm 05:51 PM
How can I implement functional programming techniques in Java?
Mar 11, 2025 pm 05:51 PM
This article explores integrating functional programming into Java using lambda expressions, Streams API, method references, and Optional. It highlights benefits like improved code readability and maintainability through conciseness and immutability
