

How to use java to implement a p2p seed search function

The content of this article is about how to use java to implement a p2p seed search function. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to you.
I had a lot of interest in p2p many years ago, but it stayed in theory and never had the opportunity to practice it. I have recently implemented this thing. From the beginning to now, I think there are some things that I can share. Let’s get to the point.
Basic concepts
Before talking about p2p, I want to talk about how we download files. Let me list several ways to download files
1. Use the http protocol to download. The most commonly used method is probably to download files through a browser.
2. Use ftp to download. There are two modes for ftp. One is port (active) mode. In this mode, the client will open a port N (>1023) locally to establish an ftp connection and then send Give the ftp server N 1 listening port for data transmission. When there is a firewall or the client is NAT, it cannot be downloaded. Another way is passive mode. In this mode, in addition to port 21, the ftp server will open a port greater than 1023. That is to say, the client will actively initiate ftp connections and data transmission connections, as long as the ftp server is open. There will be no problem with this port.
The above two methods can be collectively referred to as cs architecture. Under this architecture, resources are concentrated on the server. When the amount of data reaches a certain level, problems will occur. In order to solve this problem, we may think of distributed decentralization, so p2p came into being. p2p stands for peer to peer. This is a peer-to-peer architecture. Each node is both a client and a server.
p2p architecture
When storing resources on each node, we may think, when I download a resource, how do I know which machines this file is on? Can it be downloaded?
There was a tracker role in the early p2p architecture. This tracker was responsible for storing metadata information of files. So now the file will be saved on each peer, and the file information will be obtained through the tracker.
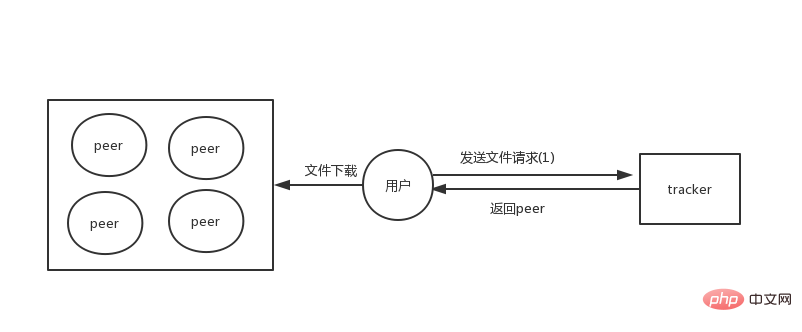
Under this architecture, all our files are distributed, but the tracker will be responsible for storing the metadata information of all files, so the tracker only needs to store a small amount of data, compared to Existing files will be relatively easy.
But once the tracker server hangs or the service is unavailable, all files will not be downloaded because it is not fully distributed. In order to be completely decentralized, a trackerless architecture will be developed later. ,
At this time, the tracker no longer exists, and all files, including the metadata information of the files, are stored in a distributed manner.
DHT
DHT (Distributed Hash Table) distributed hash table, which is used to replace tracker. There are many algorithms to implement dht, such as Kademlia algorithm and so on.
Several concepts:
1.nodeid Each nodeid in the dht network is 160bit
2.XOR The distance between two nodes is calculated using XOR
3.routing table routing table
The main focus here is implementation, so there is a lot of information on the Internet for the principle part. You can refer to it to see
How to implement it
There are two steps to implement seed search. The first step is a crawler, which is used to crawl seed information on the Internet. The second step is to join the search.
Requires the following knowledge: seeds, bittorrent dht protocol, bencoded
When it comes to p2p, we have to mention seeds, which are the kind of files that are the result of .torrent. Everyone may have used bt Torrents have downloaded files, and the downloaded files use the bittorrent protocol. So how to collect seeds on the Internet?
The main fields included in bt seeds: https://segmentfault.com/a/1190000000681331
The seeds obtained in dht are called trackerless torrent. There is no announce attribute, but there is nodes attribute instead. The official recommendation is not to add router.bittorrent.com to the seed or add it to the routing table.
1.How to get the seed from dht
If you want to get the seed information, you must have an in-depth understanding of the DHT Protocol. bep_0005 describes the DHT Protocol
For details, you can click here http://www.bittorrent.org/beps/bep_0005.html
How to implement a routing table:
The routing table is covered All Node IDs, from 0 to 2 raised to the 160th power. The routing table can be composed of buckets, and each bucket covers part of all nodes.
At the beginning, there is only one bucket in the routing table, covering all nodeids. Each bucket can only hold up to K nodes. The current K value is 8. If the bucket is full, and all the nodes in it are good, and the own nodeid is not in this bucket, then the original bucket is divided into two new buckets, covering 0..2159 respectively. and 2159..2160.
When a bucket is full, the new node is easily discarded. If the node in it goes offline, it will be replaced. If a node has not been pinged in the past 15 minutes, then ping the node. If no response is returned, the node will also be replaced.
Each bucket should have a last changed attribute to indicate the activity of this bucket. This field will be updated in these situations:
1. The node in the bucket is pinged and has a response
2. A node is added to the bucket
3. The node in the bucket has been replaced
If the bucket does not update this field within 15 minutes, an id within the bucket range will be randomly selected to perform the find_node operation.
KRPC Protocol
Messages are transmitted through the KRPC Protocol in the dht network.
1.ping
ping query is mainly used for heartbeat check
2.find_node
Find For a node, the other party will query the nearest N nodes from its own routing table and return them, usually 8
3.get_peers
Find the owner of the infohash based on the infohash If peers are found, return nodes
#4.announce_peer
tells other peers that they also have infohash.
Note that the above four will refresh the routing table
There are no nodes in the routing table at the beginning, so you need to start from the super node ( For example dht.transmissionbt.com, etc.) find and add nodes through find_node requests, and the returned nodes are used for find_node.
The routing table I implemented myself is slightly different from the one described above.
DHT network uses udp for data transmission, so I only need to open an upd port and continuously send find_node requests to establish a routing table, and then obtain the infohash of the seed through get_peers and announce_peer.
When we join the dht network, we can only get the infohash of the seed file through the four methods introduced above, so we also need to download the seed through infohash. For details, please refer to bep_009http:/ /www.bittorrent.org/beps/bep_0009.html
We mainly use bep_009 to obtain the name field of the seed. After obtaining the file name field, we can create an index based on the name and infohash to provide search. (Here we mainly build magnet links. With magnet links, you can go to Thunder, Baidu Netdisk, etc. to download resources)
Most magnet link formats: magnet:?xt=urn: btih:infohash
The method introduced above is to build a magnet link by obtaining infohash, and then download it with the help of third-party software. Of course, you can also download it yourself through BitTorrent Protocol. If you are interested, you can study it yourself.
Okay, the above just briefly introduces some implementation steps. Many details and specific implementations are not mentioned. In my own words, I referred to some github dht projects and then implemented it myself. The specific address is as follows :https://github.com/mistletoe9527/dht-spider
The above is the detailed content of How to use java to implement a p2p seed search function. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 How to Run Your First Spring Boot Application in Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
How to Run Your First Spring Boot Application in Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifies the creation of robust, scalable, and production-ready Java applications, revolutionizing Java development. Its "convention over configuration" approach, inherent to the Spring ecosystem, minimizes manual setup, allo
