

How to understand data structures and algorithms (Python)

Understanding of data structures and algorithms in Python: Data structures in Python refer to the static description of the relationship between data elements, and algorithms refer to methods or steps to solve problems. In other words, algorithms are designed to solve practical problems. Designed, the data structure is the carrier of the problem that the algorithm needs to deal with.
Data structures and algorithms are essential basic skills for a program developer, so we need to take the initiative to learn and accumulate them. Next, I will introduce these two knowledge points to you in detail in this article. I hope it will be helpful to you. Everyone helps.

[Recommended course: Python Tutorial]
Introducing concepts
Let’s look at a question first:
If a b c=1000, and a2 b2=c^2 (a, b, c are Natural numbers), how to find all possible combinations of a, b, c?
First try
import time
start_time = time.time()
# 注意是三重循环
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")Running result:
a, b, c: 0, 500, 500 a, b, c: 200, 375, 425 a, b, c: 375, 200, 425 a, b, c: 500, 0, 500 elapsed: 1066.117884 complete!
Run The time was as long as 17.8 minutes
Proposal of algorithm
Concept of algorithm
Algorithm is a computer processing information The essence of a computer program is that it is essentially an algorithm that tells the computer the exact steps to perform a specified task. Generally, when an algorithm is processing information, it will read data from an input device or a storage address of the data, and write the results to an output device or a storage address for later recall.
Algorithms are independent methods and ideas for solving problems.
For algorithms, the language of implementation is not important, what is important is the idea.
Algorithms can have different language description implementation versions (such as C description, C description, Python description, etc.). We are now using Python language to describe and implement it.
Five characteristics of algorithms
Input: The algorithm has 0 or more inputs
Output: The algorithm has at least 1 or more outputs
Finiteness: The algorithm will automatically end after a limited number of steps without looping infinitely, and each step can be completed within an acceptable time
Deterministic: Each step in the algorithm All have definite meanings and there will be no ambiguity
Feasibility: Every step of the algorithm is feasible, which means that each step can be executed a limited number of times
Second attempt
import time
start_time = time.time()
# 注意是两重循环
for a in range(0, 1001):
for b in range(0, 1001-a):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()print("elapsed: %f" % (end_time - start_time))print("complete!")Running results:
a, b, c: 0, 500, 500 a, b, c: 200, 375, 425 a, b, c: 375, 200, 425 a, b, c: 500, 0, 500 elapsed: 0.632128
Note that the running time is 0.632128 seconds
Algorithm efficiency measurement
Execution Time Response Algorithm Efficiency
For the same problem, we gave two solving algorithms. In the implementation of the two algorithms, we measured the program execution time. It is found that the execution time of the two programs is very different. From this, we can draw a conclusion: the execution time of the algorithm program can reflect the efficiency of the algorithm, that is, the quality of the algorithm.
Is the time value alone absolutely reliable?
What if we ran our second attempt at the algorithm on a computer with an ancient configuration and poor performance? Most likely the running time will not be much faster than running Algorithm 1 on our computers.
It is not necessarily objective and accurate to compare the advantages and disadvantages of algorithms based solely on running time!
The running of a program cannot be separated from the computer environment (including hardware and operating system). These objective reasons will affect the speed of program running and be reflected in the execution time of the program. So how can we objectively judge the quality of an algorithm?
Time complexity and "Big O notation"
We assume that the time it takes for the computer to perform each basic operation of the algorithm is a fixed time unit, then how many Basic operations represent how many units of time it will take. Since the exact unit time is different for different machine environments, but the number of basic operations performed by the algorithm (that is, how many time units it takes) is the same in the order of magnitude, so the influence of the machine environment can be ignored and objective The time efficiency of the reaction algorithm.
For the time efficiency of the algorithm, we can use "Big O notation" to express it.
"Big O notation": For a monotonic integer function f, if there is an integer function g and a real constant c>0, such that for a sufficiently large n there is always f(n)<=c* g(n), it is said that the function g is an asymptotic function of f (ignoring the constant), recorded as f(n)=O(g(n)). That is to say, in the extreme sense of tending to infinity, the growth rate of function f is constrained by function g, that is, the characteristics of function f and function g are similar.
Time complexity: Assume that there is a function g such that the time it takes for algorithm A to process a problem example of size n is T(n)=O(g(n)), then it is called O(g(n)) is the asymptotic time complexity of algorithm A, referred to as time complexity, denoted as T(n)
How to understand the "Big O notation"
对于算法进行特别具体的细致分析虽然很好,但在实践中的实际价值有限。对于算法的时间性质和空间性质,最重要的是其数量级和趋势,这些是分析算法效率的主要部分。而计量算法基本操作数量的规模函数中那些常量因子可以忽略不计。例如,可以认为3n2和100n2属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为它们的效率“差不多”,都为n2级。
最坏时间复杂度
分析算法时,存在几种可能的考虑:
算法完成工作最少需要多少基本操作,即最优时间复杂度
算法完成工作最多需要多少基本操作,即最坏时间复杂度
算法完成工作平均需要多少基本操作,即平均时间复杂度
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
时间复杂度的几条基本计算规则
基本操作,即只有常数项,认为其时间复杂度为O(1)
顺序结构,时间复杂度按加法进行计算
循环结构,时间复杂度按乘法进行计算
分支结构,时间复杂度取最大值
判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
算法分析
第一次尝试的算法核心部分
or a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))时间复杂度:
T(n) = O(n * n * n) = O(n³)
第二次尝试的算法核心部分
for a in range(0, 1001):
for b in range(0, 1001-a):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c: %d, %d, %d" % (a, b, c))时间复杂度:
T(n) = O(n * n * (1+1)) = O(n * n) = O(n²)
由此可见,我们尝试的第二种算法要比第一种算法的时间复杂度好多的。
常见时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n + 3 | O(n) | 线性阶 |
| 3n² +2n + 1 | O(n²) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn阶 |
| 6n³ +2n² +3n + 1 | O(n³) | 立方阶 |
| 2n | O(2n) | 指数阶 |
注意,经常将log2n(以2为底的对数)简写成logn
常见时间复杂度之间的关系
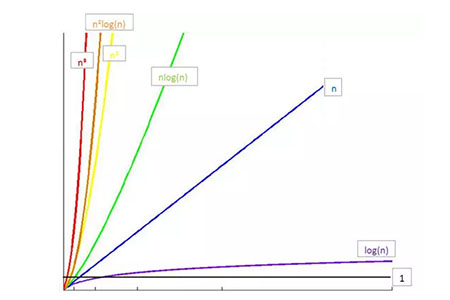
所消耗的时间从小到大
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
Python内置类型性能分析
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment)
setup参数是运行代码时需要的设置
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
list的操作测试
def test1():
l = [] for i in range(1000):
l = l + [i]def test2():
l = [] for i in range(1000):
l.append(i)def test3():
l = [i for i in range(1000)]def test4():
l = list(range(1000))from timeit import Timer
t1 = Timer("test1()", "from __main__ import test1")
print("concat ",t1.timeit(number=1000), "seconds")
t2 = Timer("test2()", "from __main__ import test2")
print("append ",t2.timeit(number=1000), "seconds")
t3 = Timer("test3()", "from __main__ import test3")
print("comprehension ",t3.timeit(number=1000), "seconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list range ",t4.timeit(number=1000), "seconds")
# ('concat ', 1.7890608310699463, 'seconds')
# ('append ', 0.13796091079711914, 'seconds')
# ('comprehension ', 0.05671119689941406, 'seconds')
# ('list range ', 0.014147043228149414, 'seconds')pop操作测试
x = range(2000000)
pop_zero = Timer("x.pop(0)","from __main__ import x")
print("pop_zero ",pop_zero.timeit(number=1000), "seconds")
x = range(2000000)
pop_end = Timer("x.pop()","from __main__ import x")
print("pop_end ",pop_end.timeit(number=1000), "seconds")
# ('pop_zero ', 1.9101738929748535, 'seconds')
# ('pop_end ', 0.00023603439331054688, 'seconds')测试pop操作:从结果可以看出,pop最后一个元素的效率远远高于pop第一个元素
可以自行尝试下list的append(value)和insert(0,value),即一个后面插入和一个前面插入???
list内置操作的时间复杂度

dict内置操作的时间复杂度

数据结构
概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
算法与数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
抽象数据类型(Abstract Data Type)
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种
插入
删除
修改
查找
排序
The above is the detailed content of How to understand data structures and algorithms (Python). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Compare complex data structures using Java function comparison
Apr 19, 2024 pm 10:24 PM
Compare complex data structures using Java function comparison
Apr 19, 2024 pm 10:24 PM
When using complex data structures in Java, Comparator is used to provide a flexible comparison mechanism. Specific steps include: defining the comparator class, rewriting the compare method to define the comparison logic. Create a comparator instance. Use the Collections.sort method, passing in the collection and comparator instances.
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Java data structures and algorithms: in-depth explanation
May 08, 2024 pm 10:12 PM
Java data structures and algorithms: in-depth explanation
May 08, 2024 pm 10:12 PM
Data structures and algorithms are the basis of Java development. This article deeply explores the key data structures (such as arrays, linked lists, trees, etc.) and algorithms (such as sorting, search, graph algorithms, etc.) in Java. These structures are illustrated through practical examples, including using arrays to store scores, linked lists to manage shopping lists, stacks to implement recursion, queues to synchronize threads, and trees and hash tables for fast search and authentication. Understanding these concepts allows you to write efficient and maintainable Java code.
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
