

How to write dedecms collection rules

As a commonly used article system, the Dreamweaver system is relatively easy to operate. Among the many functions, the collection system may be a headache for some novices, such as incorrect collection area settings, incorrect editing of collection rules, and blank spaces after collection. Today we will explain in detail some of the problems that are easier to encounter.
First of all, we log in to the background, click Collection--Collection Node Management, and enter the collection management setting interface
There are two options here, one is To modify the original nodes (mainly due to previous setting errors that led to the inability to collect or other settings), one is to directly add nodes, most of which are new nodes, click, and then next step, select "Ordinary Article" to confirm.
Then fill in the node name (it is recommended to be a name related to the column to avoid errors during import). Just fill in the actual name. Then the first key point: target page encoding. You must fill in the code of the target web page, not your own web page. Viewing method: Open any page of the target website, right-click on the blank space - View source code (the encoding is usually in the first few lines)
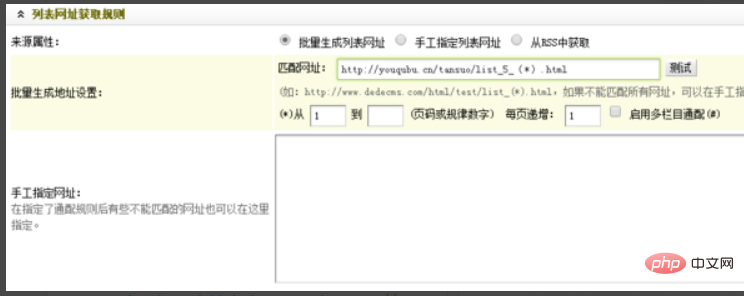
Then fill in the list rules, one is batch Generating URLs is generally suitable for those with strong rules or that need to be collected from top to bottom. For example, we target this column:
First page list: http://youqubu.cn/tansuo/list_5_1.html
Second page list: http://youqubu. cn/tansuo/list_5_2.html.
The most important thing about this list rule is to find similarities and differences. Fill in the similarities and supplement the differences with matching symbols, which are variables. In fact, from this comparison, we can know that http://youqubu.cn/tansuo/list_5_ .html are all the same, so the variable is 1.2.3.4. . So the matching URL is:
http://youqubu.cn/tansuo/list_5_(*).html.
#The other list rule is to manually specify the list URL, which is more common. Just fill in the list page of all the items you need to collect. (More suitable for collecting only certain pages or pages with more variables)
Note: The column homepages of many websites are displayed in the form of http://xxx.xx/xxx/. You can compare them with the above. It was found that the following variable items were missing. So the way to find the variable items is: click on the next page of the list. If you are still unclear, click on the next page. Comparing the second and third pages of the list, we can also find the variable items in step 4.

This step is to get all the addresses of the articles under the list. We need to get all the article page addresses from the list page. Let’s take the list at http://youqubu.cn/tansuo/list_5_1.html as an example. Copy the title of the first article under the list, then right-click on the blank space of the list page - View source code, press ctrl F to find, paste the title you just copied, and locate the position in the source code of the text. In fact, there are certain rules for this. Then we find which part of the source code is unique and can contain the addresses of all articles in the list (note: the starting code search should start from the title of the first article in the list and go up, and the end code search should start from the title of the first article in the list Start looking down). It can be seen from this source code. Start code:
- and end code:
下一步的缩略图我们可以选择不采集,因为织梦本身是会把第一张图片默认为缩略图的,这个看实际情况。下面是对网址的筛选:包含的意思是:这个步骤六选择的代码区间的文章网址只有包含了这部分才会被采集(这里有两种情况:1。譬如上面演示的地址,它是以超链接的形式,不是完整的网址,所以这种情况千万不要填写包含。2.就是列表涉及到多个链接的,比如标签这样的,最好填写包含,填写你想要的网址有的,不想要的网址没有的部分)。然后下一步。这边会列出因为上面填写的规则所采集到的列表页中文章的网址。如果是空白:我们可以先删除必须包含和不能包含,点击下一步测试,如果能采集到连接但是很乱,那就是你这步包含相关填错了;如果这样操作还是没有采集到东西,那就是“包含文章网址区域”这步填写错了。
分页规则也主要分两种:一种是直接填写默认代码:{path}{file}_{p}{ext} 然后选择分页列表规则(如下图)。 另一种是打开目标文章页,找到有上下几页的文章,右键查看源码,找到这部分代码,填写方式和文章页网址区域的方法一样,然后右边选择:全部列出的分页列表。(第二种方法要注意,因为涉及到多页,填写首尾代码的时候一定要多翻几张,然后查看源代码,把你认为共同的代码在多个页面查找下,因为可能出现你选择的代码在首页是可以找到的,在2.3四页后面就没有了,那就说明这个不是公用代码,你填上去也会导致采集不到分页的)
分页设置好后,我们主要设置标题规则和内容规则。时间规则和作者、来源规则这里不细说,这个不是所有人都需要的,这步谈到的规则都可以获取区间的方式得到内容或者填入固定的词语。首先是标题规则:我们以:http://youqubu.cn/tansuo/362.html。这个文章页来做说明。我们先复制标题名字,然后在源代码中查找。示例中查找我们可以发现这里有五个相同的部分,而且冲对比中发现,这个其实是有两种写法的。1.完全包含这个文字的代码区间,不带其他文字:
The following content is the same. What should be noted here is that the advertising code or To block unnecessary things, "filter rules" are used here. Under normal circumstances, except for IMG, everything else can be filtered. If you don’t even want pictures, just select them all.
Finally click Save to start collecting web pages. After the collection is completed, we click Collection-Collection Node Management. After we enter, check the box in front of the node we just collected, then click "Export Data", select the column you want to import, and confirm. (It is best to set the repeating title in the last step of setting)

For more DedeCMS related technical articles, please visit the DedeCMS Tutorial column to learn!
The above is the detailed content of How to write dedecms collection rules. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52