

BP neural network algorithm

The BP (Back Propagation) network was proposed in 1986 by a group of scientists headed by Rumelhart and McCelland. It is a multi-layer feedforward network trained according to the error back propagation algorithm. It is currently the most widely used neural network model. one.
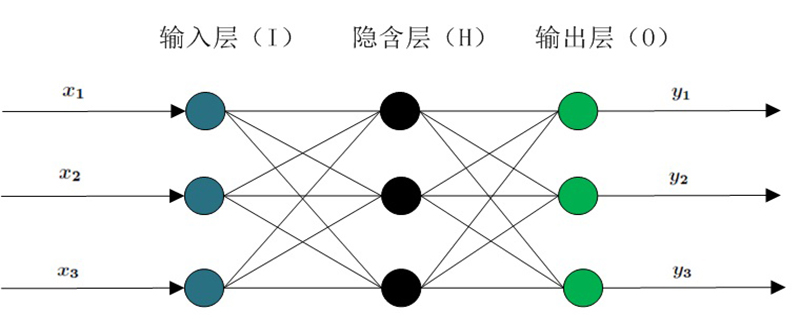
BP network can learn and store a large number of input-output pattern mapping relationships without revealing in advance the mathematical equations describing this mapping relationship.
Its learning rule is to use the steepest descent method and continuously adjust the weights and thresholds of the network through backpropagation to minimize the sum of square errors of the network. The topology structure of BP neural network model includes input layer, hidden layer and output layer. (Recommended learning: web front-end video tutorial)
BP neural network algorithm is proposed based on the existing algorithm of BP neural network, through arbitrary selection With a set of weights, the given target output is directly used as the algebraic sum of linear equations to establish a system of linear equations. The solution requires weighting. There is no local minimum and slow convergence problems of traditional methods, and it is easier to understand.
BP algorithm
The artificial neural network (ANN) system appeared after the 1940s. It is adjustable by numerous neurons. It is connected by connection weights and has the characteristics of large-scale parallel processing, distributed information storage, and good self-organization and self-learning capabilities. It is increasingly widely used in the fields of information processing, pattern recognition, intelligent control, and system modeling. .
In particular, the error back-propagation training (BP network) can approximate any continuous function, has strong nonlinear mapping capabilities, and the number of intermediate layers of the network and the processing units of each layer Parameters such as the number and the learning coefficient of the network can be set according to the specific situation, and the flexibility is great, so it plays an important role in many application fields.
In order to solve the shortcomings of BP neural network such as slow convergence speed, inability to guarantee convergence to the global maximum point, lack of theoretical guidance in selecting the middle layer of the network and the number of its units, and instability of network learning and memory, this method was proposed Many improved algorithms.
The above is the detailed content of BP neural network algorithm. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
Today's deep learning methods focus on designing the most suitable objective function so that the model's prediction results are closest to the actual situation. At the same time, a suitable architecture must be designed to obtain sufficient information for prediction. Existing methods ignore the fact that when the input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost. This article will delve into important issues when transmitting data through deep networks, namely information bottlenecks and reversible functions. Based on this, the concept of programmable gradient information (PGI) is proposed to cope with the various changes required by deep networks to achieve multi-objectives. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights. In addition, a new lightweight network framework is designed
 The foundation, frontier and application of GNN
Apr 11, 2023 pm 11:40 PM
The foundation, frontier and application of GNN
Apr 11, 2023 pm 11:40 PM
Graph neural networks (GNN) have made rapid and incredible progress in recent years. Graph neural network, also known as graph deep learning, graph representation learning (graph representation learning) or geometric deep learning, is the fastest growing research topic in the field of machine learning, especially deep learning. The title of this sharing is "Basics, Frontiers and Applications of GNN", which mainly introduces the general content of the comprehensive book "Basics, Frontiers and Applications of Graph Neural Networks" compiled by scholars Wu Lingfei, Cui Peng, Pei Jian and Zhao Liang. . 1. Introduction to graph neural networks 1. Why study graphs? Graphs are a universal language for describing and modeling complex systems. The graph itself is not complicated, it mainly consists of edges and nodes. We can use nodes to represent any object we want to model, and edges to represent two
 An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
The current mainstream AI chips are mainly divided into three categories: GPU, FPGA, and ASIC. Both GPU and FPGA are relatively mature chip architectures in the early stage and are general-purpose chips. ASIC is a chip customized for specific AI scenarios. The industry has confirmed that CPUs are not suitable for AI computing, but they are also essential in AI applications. GPU Solution Architecture Comparison between GPU and CPU The CPU follows the von Neumann architecture, the core of which is the storage of programs/data and serial sequential execution. Therefore, the CPU architecture requires a large amount of space to place the storage unit (Cache) and the control unit (Control). In contrast, the computing unit (ALU) only occupies a small part, so the CPU is performing large-scale parallel computing.
 'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
In Minecraft, redstone is a very important item. It is a unique material in the game. Switches, redstone torches, and redstone blocks can provide electricity-like energy to wires or objects. Redstone circuits can be used to build structures for you to control or activate other machinery. They themselves can be designed to respond to manual activation by players, or they can repeatedly output signals or respond to changes caused by non-players, such as creature movement and items. Falling, plant growth, day and night, and more. Therefore, in my world, redstone can control extremely many types of machinery, ranging from simple machinery such as automatic doors, light switches and strobe power supplies, to huge elevators, automatic farms, small game platforms and even in-game machines. built computer. Recently, B station UP main @
 A drone that can withstand strong winds? Caltech uses 12 minutes of flight data to teach drones to fly in the wind
Apr 09, 2023 pm 11:51 PM
A drone that can withstand strong winds? Caltech uses 12 minutes of flight data to teach drones to fly in the wind
Apr 09, 2023 pm 11:51 PM
When the wind is strong enough to blow the umbrella, the drone is stable, just like this: Flying with the wind is a part of flying in the air. From a large level, when the pilot lands the aircraft, the wind speed may be Bringing challenges to them; on a smaller level, gusty winds can also affect drone flight. Currently, drones either fly under controlled conditions, without wind, or are operated by humans using remote controls. Drones are controlled by researchers to fly in formations in the open sky, but these flights are usually conducted under ideal conditions and environments. However, for drones to autonomously perform necessary but routine tasks, such as delivering packages, they must be able to adapt to wind conditions in real time. To make drones more maneuverable when flying in the wind, a team of engineers from Caltech
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
"ComputerWorld" magazine once wrote an article saying that "programming will disappear by 1960" because IBM developed a new language FORTRAN, which allows engineers to write the mathematical formulas they need and then submit them. Give the computer a run, so programming ends. A few years later, we heard a new saying: any business person can use business terms to describe their problems and tell the computer what to do. Using this programming language called COBOL, companies no longer need programmers. . Later, it is said that IBM developed a new programming language called RPG that allows employees to fill in forms and generate reports, so most of the company's programming needs can be completed through it.