
 Database
Mysql Tutorial
Why does MySQL choose B+ tree as the index structure? (detailed explanation)
Database
Mysql Tutorial
Why does MySQL choose B+ tree as the index structure? (detailed explanation)
Why does MySQL choose B+ tree as the index structure? (detailed explanation)

In MySQL, both Innodb and MyIsam use B-tree as the index structure (other indexes such as hash are not considered here). This article will start with the most common binary search tree, and gradually explain the problems solved by various trees and the new problems faced, thereby explaining why MySQL chooses B-tree as the index structure.

##1. Binary Search Tree (BST): Unbalanced
Binary Search Tree (BST, Binary Search Tree), also called binary sorting tree, needs to satisfy on the basis of binary tree: the value of all nodes on the left subtree of any node is not greater than the value of the root node, any node The value of all nodes in the right subtree is not less than the value of the root node. The following is a BST (picture source).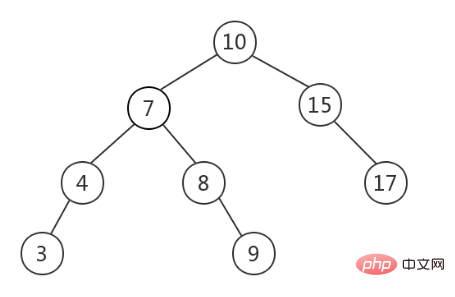
BST may grow skewed and become unbalanced, as shown in the figure below (picture source). At this time, BST degenerates into a linked list, and the time complexity degenerates into O(n).
In order to solve this problem, balanced binary trees are introduced.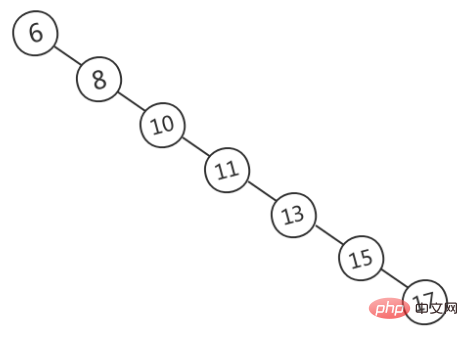
2. Balanced Binary Tree (AVL): Rotation takes time
AVL tree is strictly balanced For binary trees, the height difference between the left and right subtrees of all nodes cannot exceed 1; AVL tree search, insertion and deletion are O(lgn) in both the average and worst cases. The key to achieving balance in AVL lies in the rotation operation: insertion and deletion may destroy the balance of the binary tree, and the tree needs to be rebalanced through one or more tree rotations. When inserting data, only one rotation (single rotation or double rotation) is required at most; but when data is deleted, it will cause the tree to become unbalanced. AVL needs to maintain the balance of all nodes on the path from the deleted node to the root node. Rotation The magnitude of is O(lgn).Due to the time-consuming rotation, the AVL tree is very inefficient when deleting data; when there are many deletion operations, the cost of maintaining balance may be higher than benefits, so AVL is not widely used in practice.
3. Red-black tree: The tree is too tall
Compared with AVL trees, red-black trees do not pursue strict balance, but is a rough balance: just make sure that the longest possible path from root to leaf is no more than twice as long as the shortest possible path. From an implementation point of view, the biggest feature of the red-black tree is that each node belongs to one of two colors (red or black), and the division of node colors needs to meet specific rules (the specific rules are omitted). An example of a red-black tree is as follows (picture source): 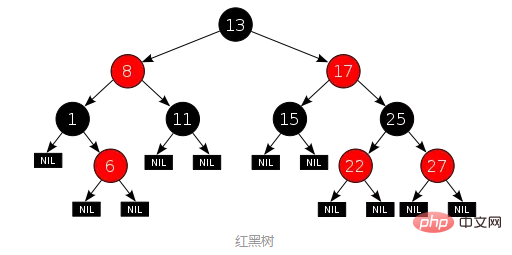
for the situation where the data is in auxiliary storage devices such as disks (such as MySQL and other databases), the red-black tree is not good at it, because the red-black tree still grows too high. . When the data is on the disk, disk IO will become the biggest performance bottleneck, and the design goal should be to minimize the number of IOs; the higher the height of the tree, the more IO times required for additions, deletions, modifications, and searches, which will seriously affect performance.
4. B-tree: Born for disk
BThe tree is also called B- tree (where - is not a minus sign) is a multi-path balanced search tree designed for auxiliary storage devices such as disks. Compared with binary trees, Each non-leaf node of the B tree can have multiple subtrees. Therefore, when the total number of nodes is the same, the height of the B-tree is much smaller than the AVL tree and the red-black tree (the B-tree is a "dumpty"), and the number of disk IOs is greatly reduced.
The most important concept in defining a B-tree is the order. For an m-order B-tree, the following conditions need to be met:
- Each node contains at most m child nodes.
- If the root node contains child nodes, it must contain at least 2 child nodes; except for the root node, each non-leaf node must contain at least m/2 child nodes.
- A non-leaf node with k child nodes will contain k - 1 records.
- All leaf nodes are in the same layer.
It can be seen that the definition of B-tree mainly limits the number of child nodes and records of non-leaf nodes.
The following picture is an example of a 3-order B-tree (picture source):
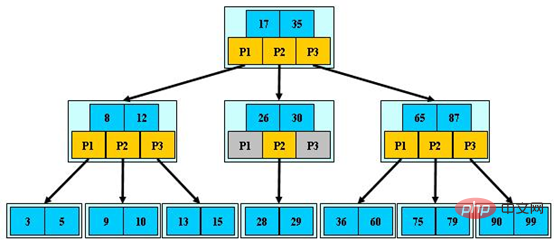
The advantages of the B-tree are not only the small tree height, but also the ability to access local areas. Utilization of sexual principles. The so-called locality principle means that when a piece of data is used, the data nearby has a higher probability of being used in a short time. B-tree stores data with similar keys in the same node. When one of the data is accessed, the database will read the entire node into the cache; when its adjacent data is accessed immediately, it can be read directly from the cache. , no disk IO is required; in other words, the cache hit rate of B-tree is higher.
B-tree has some applications in databases. For example, mongodb's index uses B-tree structure. However, in many database applications, B-tree, a variant of B-tree, is used.
5. B-tree
B-tree is also a multi-path balanced search tree. Its main difference from B-tree is:
- Each node in the B-tree (including leaf nodes and non-leaf nodes) stores real data. Only leaf nodes in the B-tree store real data, and non-leaf nodes only store keys. In MySQL, the real data mentioned here may be all the data of the row (such as Innodb's clustered index), or it may be just the primary key of the row (such as Innodb's auxiliary index), or the address of the row (such as MyIsam's non-clustered index).
- A record in the B-tree will only appear once and will not appear repeatedly, while the key of the B-tree may appear repeatedly - it will definitely appear in a leaf node, or it may appear repeatedly in a non-leaf node.
- The leaf nodes of the B tree are linked through a doubly linked list.
- For non-leaf nodes in the B-tree, the number of records is 1 less than the number of child nodes; while the number of records in the B-tree is the same as the number of child nodes.
Thus, B-tree has the following advantages compared to B-tree:
- Fewer IO times: The non-leaf nodes of the B tree only contain keys, not real data, so the number of records stored in each node is much more than the number of B (that is, the order m is larger), so the height of the B tree is lower, and the access time is Fewer IO times are required. In addition, since each node stores more records, the access locality principle is better utilized and the cache hit rate is higher.
- More suitable for range queries: When performing a range query in a B-tree, first find the lower limit to be found, and then perform an in-order traversal of the B-tree until Find the upper limit of the search; and the range query of the B-tree only needs to traverse the linked list.
- More stable query efficiency: The query time complexity of B-tree is between 1 and the tree height (corresponding to the root node and leaf node respectively), The query complexity of the B-tree is stable at the tree height, because all data is in the leaf nodes.
B trees also have disadvantages: they take up more space because keys are repeated. However, compared with the performance advantages, the space disadvantage is often acceptable, so B-trees are more widely used in databases than B-trees.
6. Feel the power of B-tree
As mentioned earlier, compared with binary trees such as red-black trees, B-tree/B-tree has the largest The advantage is that the tree height is smaller. In fact, for Innodb's B index, the height of the tree is generally 2-4 levels. Let’s make some specific estimates below.
The height of the tree is determined by the order. The larger the order, the shorter the tree; and the size of the order depends on how many records each node can store. Each node in Innodb uses a page (page), the page size is 16KB, of which metadata only accounts for about 128 bytes (including file management header information, page header information, etc.), most of the space is used to store data .
For non-leaf nodes, the record only contains the key of the index and a pointer to the next level node. Assuming that each non-leaf page stores 1000 records, each record takes up approximately 16 bytes; this assumption is reasonable when the index is an integer or a shorter string. By extension, we often hear suggestions that the length of the index column should not be too large. Here is the reason: if the index column is too long and each node contains too few records, the tree will be too tall and the indexing effect will be greatly reduced. And the index will waste more space.
- For leaf nodes, the record contains the key and value of the index (the value may be the primary key of the row, a complete row of data, etc., see the previous article for details), and the amount of data is larger. It is assumed here that each leaf node page stores 100 records (actually, when the index is a clustered index, this number may be less than 100; when the index is a auxiliary index, this number may be much greater than 100; it can be estimated based on the actual situation) .
For a 3-layer B-tree, the first layer (root node) has 1 page and can store 1000 records; the second layer has 1000 pages and can store 1000*1000 records. ;The third layer (leaf node) has 1000*1000 pages, and each page can store 100 records, so it can store 1000*1000*100 records, or 100 million records. For a binary tree, about 26 layers are needed to store 100 million records.
7. Summary
Finally, summarize the problems solved by various trees and the new problems faced:
1 ), Binary Search Tree (BST): solves the basic problem of sorting, but because balance cannot be guaranteed, it may degenerate into a linked list;
2), Balanced Binary Tree (AVL): solves the problem of balance through rotation , but the rotation operation efficiency is too low;
3), red-black tree: By abandoning strict balance and introducing red-black nodes, the problem of AVL rotation efficiency being too low is solved. However, in scenarios such as disks, the tree Still too high, too many IO times;
4), B-tree: By changing the binary tree to a multi-path balanced search tree, the problem of the tree being too high is solved;
5), B Tree: Based on the B-tree, non-leaf nodes are transformed into pure index nodes that do not store data, further reducing the height of the tree; in addition, the leaf nodes are connected into a linked list using pointers, making range queries more efficient.
Recommended learning: MySQL tutorial
The above is the detailed content of Why does MySQL choose B+ tree as the index structure? (detailed explanation). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL is suitable for beginners because it is simple to install, powerful and easy to manage data. 1. Simple installation and configuration, suitable for a variety of operating systems. 2. Support basic operations such as creating databases and tables, inserting, querying, updating and deleting data. 3. Provide advanced functions such as JOIN operations and subqueries. 4. Performance can be improved through indexing, query optimization and table partitioning. 5. Support backup, recovery and security measures to ensure data security and consistency.
 Can I retrieve the database password in Navicat?
Apr 08, 2025 pm 09:51 PM
Can I retrieve the database password in Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat itself does not store the database password, and can only retrieve the encrypted password. Solution: 1. Check the password manager; 2. Check Navicat's "Remember Password" function; 3. Reset the database password; 4. Contact the database administrator.
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
Steps to perform SQL in Navicat: Connect to the database. Create a SQL Editor window. Write SQL queries or scripts. Click the Run button to execute a query or script. View the results (if the query is executed).
