


Judge the problem SQL
When you judge whether there is a problem with SQL, you can judge it through two appearances:
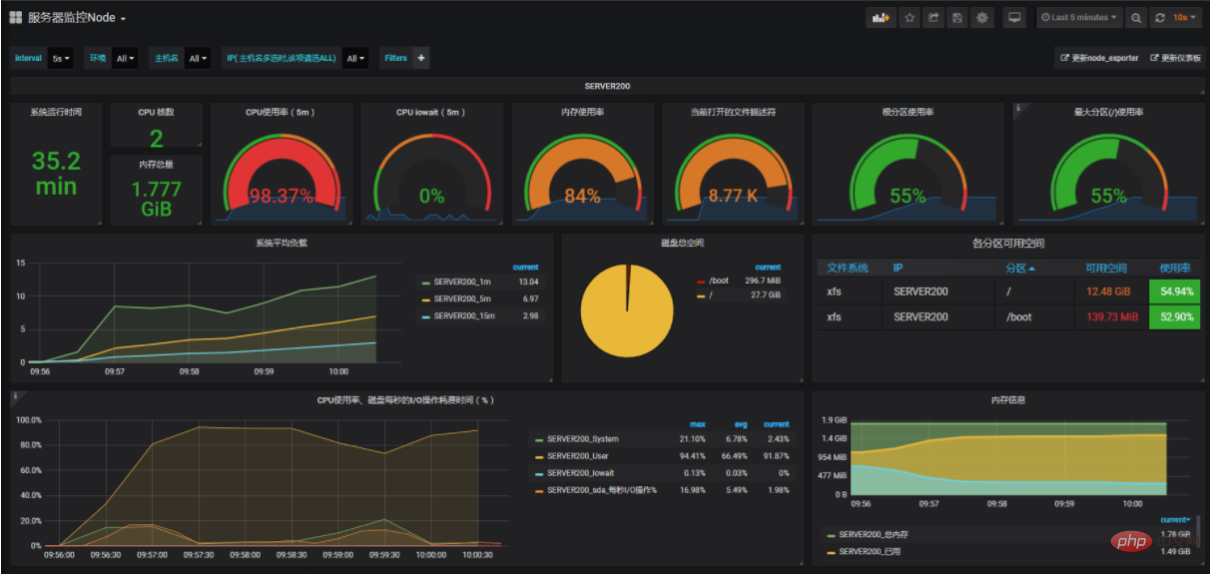
, you can use the sar command and the top command to view the current system status.

You can also observe the system status through Prometheus, Grafana and other monitoring tools.
Long SQL is easy to understand. If a SQL is too long, the readability will definitely be poor, and problems will occur. The frequency will definitely be higher. To further determine the SQL problem, we have to start with the execution plan, as shown below:

The execution plan tells us that this query went through a full table scanType=ALL, the rows are very large (9950400) and it can be basically judged that this is a "flavorful" SQL.
Getting problem SQL
Different databases have different ways to get it. The following is the slow query SQL acquisition tool for the current mainstream databases
SQL writing skills
There are several general skills for SQL writing:
• Reasonable use of indexes
Fewer indexes will slow down queries; too many indexes will take up a lot of space, and the indexes need to be dynamically maintained when executing additions, deletions and modifications, affecting performance
High selection rate (fewer duplicate values) And it is frequently referenced by where and B-tree indexes need to be established; general join columns need to be indexed; complex document type queries are more efficient with full-text indexes; the establishment of indexes must strike a balance between query and DML performance; when creating composite indexes, attention should be paid to based on In the case of non-leading column query
• Use UNION ALL instead of UNION
UNION ALL has higher execution efficiency than UNION. UNION needs to be deduplicated when executing; UNION needs to Sort
• Avoid select * writing method
When executing SQL, the optimizer needs to convert * into specific columns; each query must return to the table and cannot be overwritten. index.
• It is recommended to create an index for JOIN fields
Generally, JOIN fields are indexed in advance
• Avoid complex SQL statements
Improve readability; avoid the probability of slow queries; can be converted into multiple short queries and processed by the business end
• Avoid where 1=1 writing
• Avoid order by rand() similar writing
RAND() causing the data column to be scanned multiple times
SQL optimization Execution plan
Be sure to read the execution plan before completing SQL optimization. The execution plan will tell you where the efficiency is low and where optimization is needed. Let's take MYSQL as an example to see what the execution plan is. (The execution plan of each database is different and you need to understand it yourself)

| Field | Explanation |
|---|---|
| id | Each is executed independently The operation identifier identifies the order in which the object is operated. The larger the id value, the first to be executed. If they are the same, the execution order is from top to bottom |
| select_type | In query The type of each select clause |
| table | The name of the object being operated on, usually the table name, but there are other formats |
| partitions | Matching partition information (value is NULL for non-partitioned tables) |
| type | Type of join operation |
| possible_keys | Possibly used indexes |
| key | The index actually used by the optimizer (The most important The join types from best to worst are const, eq_reg, ref, range, index and ALL. When ALL appears, it means that the current SQL has a "bad smell"
|
| The length of the index key selected by the optimizer, the unit is The byte | |
| represents the reference object of the operated object in this row. No reference object is NULL | |
| The number of tuples scanned by query execution (for innodb, this value is an estimate) | |
| The data on the conditional table is filtered Percentage of number of tuples | |
| Important supplementary information of the execution plan, when this column appears | Using MySQL database SQL statement optimizationsort, Using temporary# Be careful when using the word ##, it is very likely that the SQL statement needs to be optimized |
CREATE TABLE `a` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_id` bigint(20) DEFAULT NULL, `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `b` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_name` varchar(100) DEFAULT NULL, `user_id` varchar(50) DEFAULT NULL, `user_name` varchar(100) DEFAULT NULL, `sales` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `c` ( `id` int(11) NOT NULLAUTO_INCREMENT, `user_id` varchar(50) DEFAULT NULL, `order_id` varchar(100) DEFAULT NULL, `state` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) );
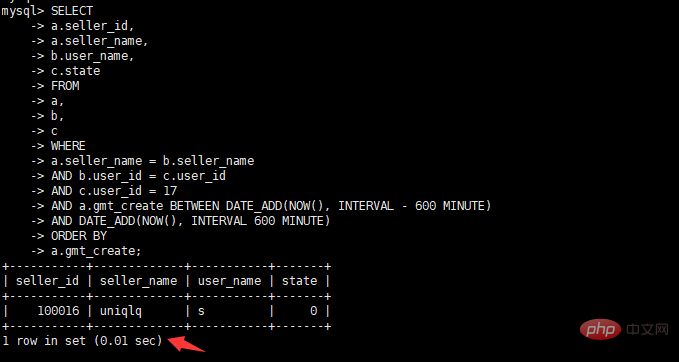
select a.seller_id, a.seller_name, b.user_name, c.state from a, b, c where a.seller_name = b.seller_name and b.user_id = c.user_id and c.user_id = 17 and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE) AND DATE_ADD(NOW(), INTERVAL 600 MINUTE) order by a.gmt_create
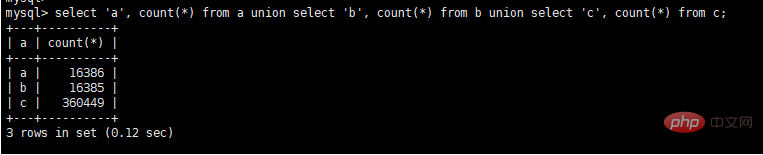
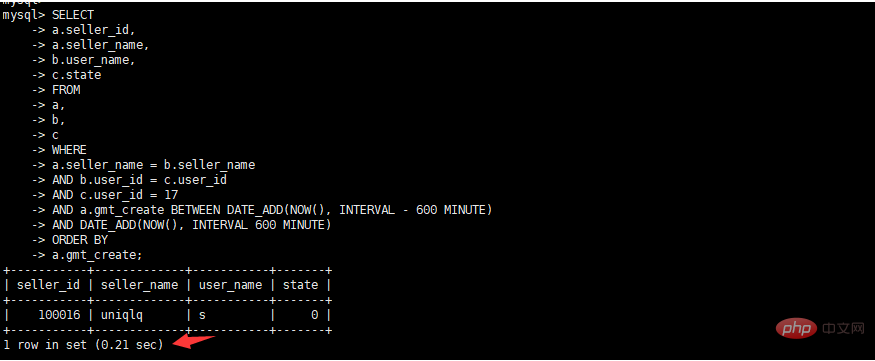
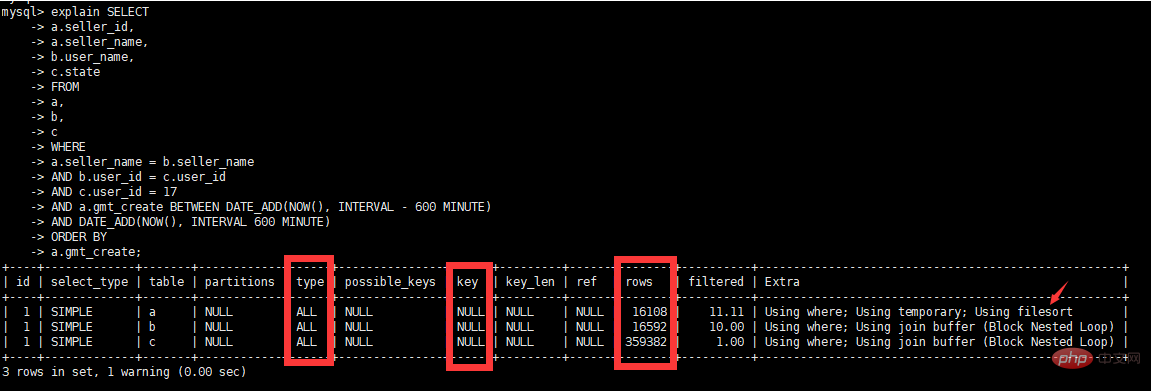
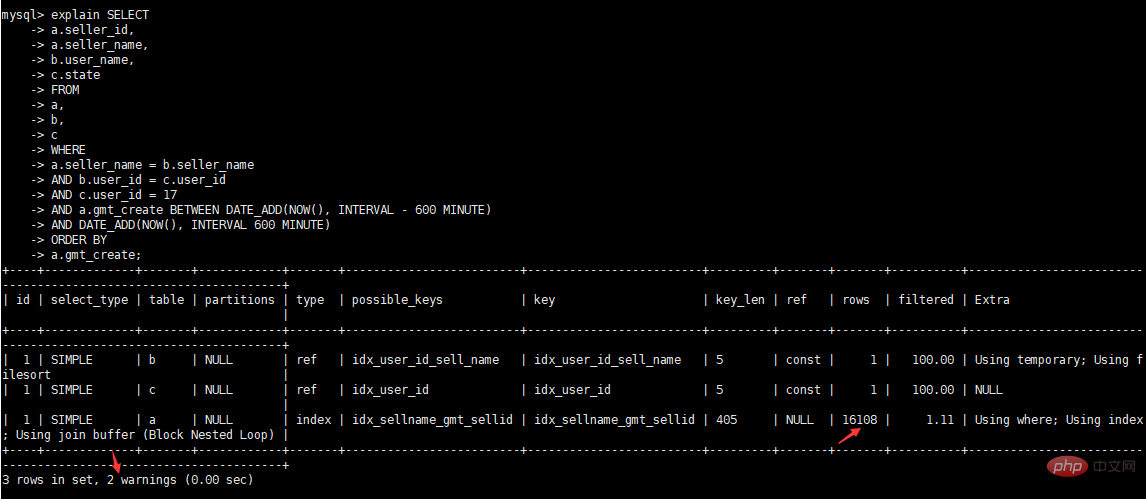
is of varchar(50) type. The actual int type used in SQL has implicit conversion and no index is added. Change the user_id fields in tables b and c to int type.
fields of the a and b tables are indexed.
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
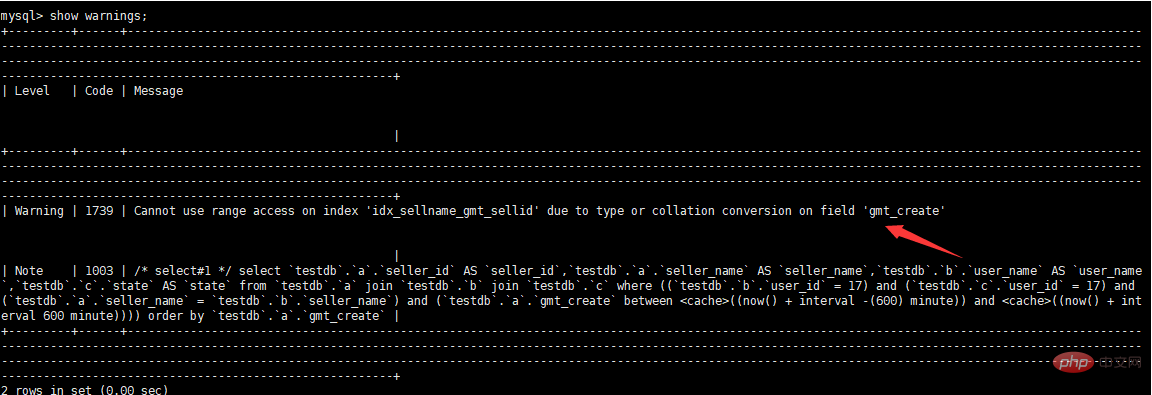
alter table a modify "gmt_create" datetime DEFAULT NULL
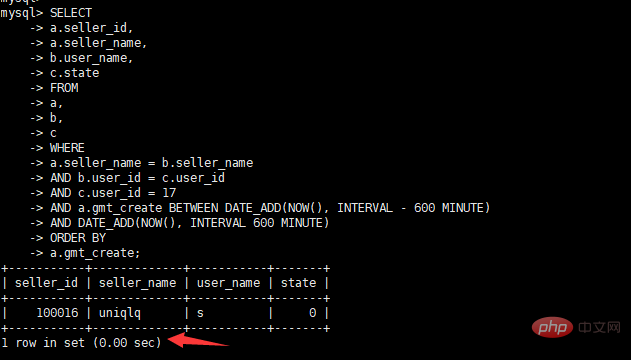
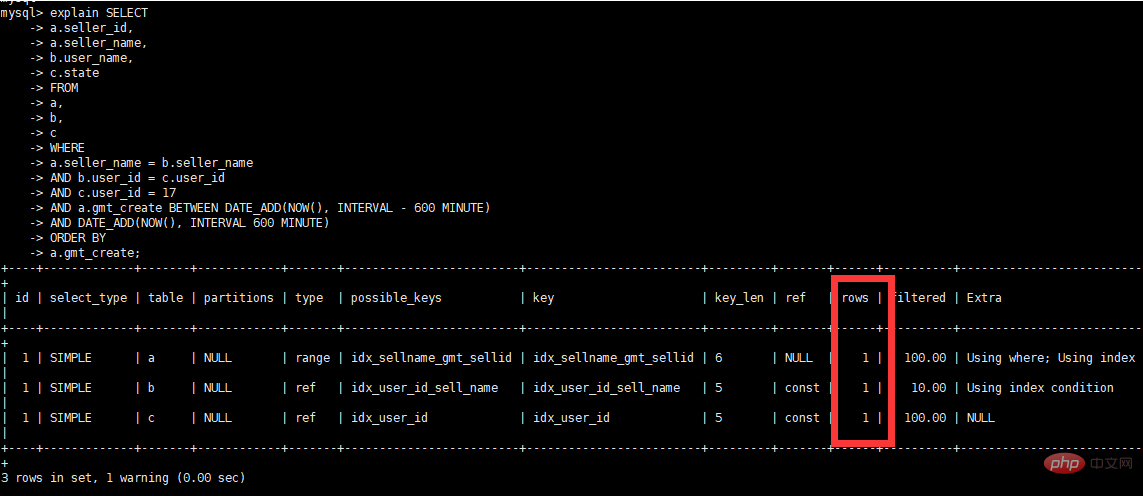
View Execution plan explain
Recommended "
mysql video tutorialThe above is the detailed content of MySQL database SQL statement optimization. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



