
1 |
|
1 |
|

Explore Redis persistence principles


In-depth exploration of the persistence principle of Redis
Redis is an in-memory database. In order to ensure the persistence of data, Redis provides two persistence methods: RDB and AOF.

Redis is an in-memory database. In order to ensure the persistence of data, redis provides two persistence methods: RDB and AOF. AOF, let's take a look at the implementation principles of these two persistence methods separately.
RDB (default)
RDB is completed through snapshots. When certain conditions are met, redis will automatically persist the data in the memory to the disk.
The timing of triggering the snapshot
- Conforms to the custom configured snapshot rules. (Configured in redis.conf, detailed below)
- Execute the save or bgsave command
- Execute the flushall command
Perform the master-slave replication operation (first times)
(Free learning video tutorial recommendation: mysql video tutorial)
Schematic diagram
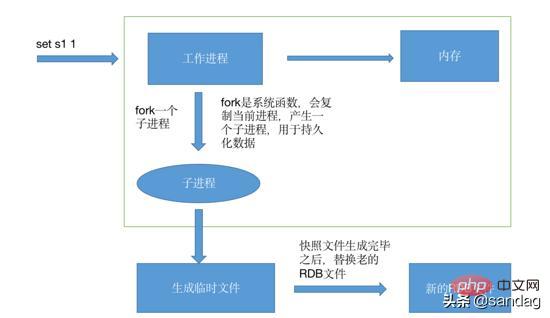
- During the snapshot process, that is, the process of generating files, the original rdb file will not be modified until the snapshot is generated, and the old one will be directly replaced with the new one to ensure that the rdb file Every moment is complete.
- We can back up redis data by regularly backing up rdb files. RDB is a compressed binary file that takes up small space and is conducive to transmission.
- Disadvantages: Using RDB for persistence, when redis suddenly exits abnormally, the data after the last snapshot will be lost. However, you can set up automatic snapshots based on the combination to reduce data loss and ensure it is within the acceptable range. If the data is more important, you can use the AOF method
- Advantages: Using the RDB method can maximize redis performance. During the snapshot process, we can see that the main process only needs to fork out a child process, and the rest All work is completed by the child process, and the parent process does not need to perform any disk I/O operations. However, if the data set is large, it will be time-consuming to fork the child process, which will cause redis to stop processing requests for a period of time.
1
# 开启appendonly参数appendonly true# 设置AOF文件位置dir ./# 设置AOF文件名称,默认是appendonly.aofappendfilename appendonly.aof<br/>
Copy after login
Principle Figure1 |
|
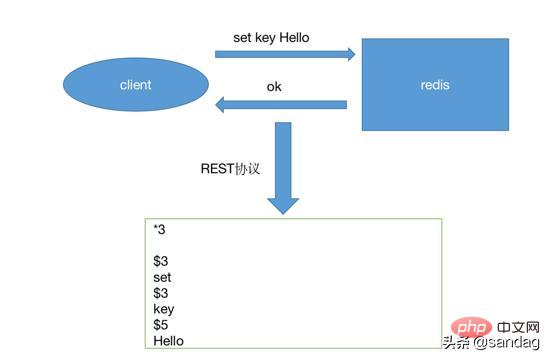
- Spacing symbol: \r\n in linux, \n in windowsSimple string starts with ' 'Errors, starts with '-' starts Integer type Integer, starts with ':'Large string starts with '$'Array type Arrays, starts with '*'
- Command propagationCache appendFile writing and saving
缓存追加
AOF程序接收到命令参数之后,会将其从字符串对象转换成协议内容,再将协议内容追加到AOF缓存中。AOF缓存是在redisServer结构的aof_buf中,新的内容会被追加到aof_buf末尾。aof_buf保持着所有未被写入到AOF文件的协议文本。
文件写入和保存
将AOF缓存内容写入到AOF文件,并保持到磁盘。 当服务器的常规函数被执行,或者事件处理器被执行的时候,flushAppendOnlyFile函数将会被执行。会有以下两个过程。
- WRITE:将AOF缓存中的内容写入到AOF文件
- SAVE:调用fsync或者fdatasync函数,将AOF文件保存到磁盘中
AOF一共有三种保存模式
- AOF_FSYNC_NO:不保存。在这种模式下,每次调用flushAppendOnlyFile函数,write会被执行,而save会被忽略。而save只有在以下三种条件下会触发,redis关闭,aof功能关闭,系统的写缓存被刷新(可能是缓存满了,或者定期执行保持操作)。这三种情况下执行save操作会引起redis主线程的阻塞。
- AOF_FSYNC_EVERYSEC(默认):每秒保存一次。save每秒被执行一次,但是save由后台子线程完成,不会导致redis主线程阻塞。
- AOF_FSYNC_ALWAYS:每执行一个命令保存一次。这种情况下,每执行一个命令write和save都会被执行,而且save操作由主线程完成,会导致redis的阻塞。安全性较高,性能较差,因此不推荐使用。
AOF的文件优化
Redis可以在AOF文件过大的时候,在后台(子进程)对AOF文件进行重写。重写之后的新文件,包含恢复当前数据集所需的最小命令集合。重写,并不会对AOF文件进行读取和写入,针对的是数据库中的当前键。
1 |
|
AOF文件优化原理
AOF的重写是通过子进程实现的,因此,主线程是继续工作的,有可能对新的数据进行修改,有可能会导致数据库的数据和重写之后的数据不一致。redis通过增加一个AOF重写缓存来解决这个问题,当fork出子进程之后,新的命令不仅会追加到现有的AOF文件中,还会添加一份数据到这个缓存当中。
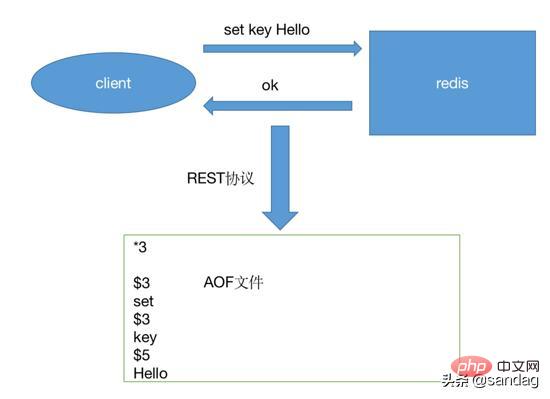
重写过程分析(需要保证从写的操作是绝对安全的)
Redis创建新的AOF文件之后,会继续将命令添加到原有的AOF文件中,即使数据库突然宕机了,原有的AOF文件和文件内容也不会有损失。而当新的AOF文件创建完毕之后,会直接把旧的替换掉,往新的AOF文件中添加命令。
当子进程在进行重写时,主进程会完成下列工作
- 处理请求,将新的命令继续添加到AOF文件中,同时将命令添加到AOF重写缓存中。保证数据的一致行,避免出现数据丢失。
- 当子进程重写完毕之后会向主进程发送一个完成信号,这时主进程会把重写缓存中的内容添加到新的AOF文件中,这样新的AOF文件,数据库,旧的AOF文件的内容就完全一致了。然后对新的AOF文件改名,覆盖原有的AOF文件。
这样程序就完成了新旧AOF文件的替换工作。而当处理完成之后,主进程就会继续接受请求。整个重写过程中只有最后的缓存写入和改名替换的操作会导致主进程阻塞,其他时候不会影响redis的正常工作,把AOF重写对redis的性能影响降到最低。
优化触发条件
1 |
|
本文转载自:https://database.51cto.com/art/202002/610825.htm
更多redis知识请关注redis数据库教程栏目。
The above is the detailed content of Explore Redis persistence principles. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
37
110
52
37
110

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
