
The so-called redis data consistency means that after modification, saving, or deletion, the data in redis should also change accordingly. Otherwise, when the user queries again, it is likely to find dirty data that has been deleted.
1. The necessity of cache consistency
Continuing from the previous article, we have solved the problem of redis cache penetration (simple solution, can be optimized again), but when using redis we also need to consider the issue of cache consistency. For example: after saving a new user, the data should also be inserted into the redis cache at the same time, and a certain piece of data should be updated in the cache. should also be updated synchronously, and the default method of redis is: when you do not set it, the value stored in redis is the data you previously stored. The data will only be synchronized when the server is restarted. Obviously this is very undesirable. Yes, if this is the case, wouldn’t the server have to be restarted all the time? What a disaster it would be!
2. Business Scenario
I will only talk about one scenario here. The other scenarios are handled in the same way. The scenario is: Suppose we put user data into redis. At this time, there are When a new user registers, a new piece of data will be inserted into the database. At the same time, the piece of data must also be inserted into redis so that the latest data can be displayed during the next query.
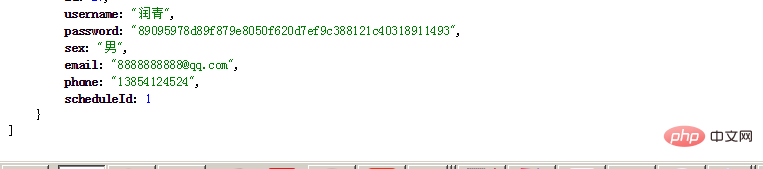
Let’s first take a look at whether redis will do consistency operations for us without using any processing by default. Now there are 18 pieces of user data in my test database. At this time, after we start the system, we register and insert the first After 19 pieces of data, check whether there are 19 pieces in redis.
After registration, I have now inserted the 19th piece of data into the database
Then we still use the previous article The mentioned query cache method is used to obtain all the information. Let's look directly at the last one. We can see that the last one is Runqing instead of Nineteen, so redis does not perform cache consistency operations for us by default.
3. Cache consistency implementation (Option 1)
In fact, it is very simple to achieve consistency. After we perform the insertion operation, we Take out the data and save it to the redis cache at the same time, so that when we query the cache again, we can also see the new data. The code is as follows:

Things to note Yes: I directly call JPA's findAll() here. In fact, a better way is to update the one just inserted based on the id. This is more efficient. Here is just a demonstration of how to implement it, and then register a new data to see if it works. You can also see in the cache: the newly inserted data id is 29. Let’s see if the new data exists in the cache
4. Redis cache consistency implementation (Option 2)
Clear the data in redis regularly, for example, set a scheduled task, and the data in redis will be cleared every hour, that is, let redis The data becomes invalid, and when you save or delete it again, the previous data in redis no longer exists, so it is equivalent to resetting the data to redis, so the consistency of the data can be guaranteed.
For more redis knowledge, please pay attention to the redis introductory tutorial column.
The above is the detailed content of Introduction to redis data consistency. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis












![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



