

Programmers should be familiar with hashing algorithms, such as the industry-famous MD5, SHA, CRC, etc.; in daily development, we often use a Map to load some data with a (key, value) structure, and use the time complexity of the hash algorithm O(1) to improve program processing efficiency. In addition, you also Do you know other application scenarios of hashing algorithms?
Before understanding the application scenarios of the hash algorithm, let's first look at the hash (hash) idea. Hashing is to transform input of any length into Fixed-length output, the input is called Key, the output is a Hash value, that is, the hash value hash(key), and the hash algorithm is the hash() function (Hash and hash are different translations of hash ); Actually, these hash values are stored in an array, called a hash table. The hash table uses the feature of the array to support random access to data according to the subscript. The data value and the array subscript are used as a hash function. One-to-one mapping, thereby achieving O(1) time complexity query;
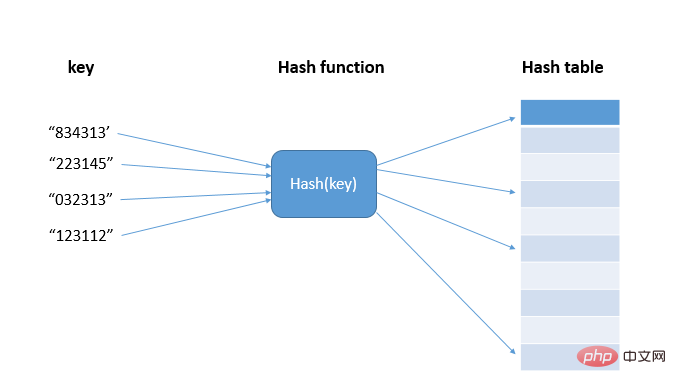
Current Hash algorithms MD5, SHA, CRC, etc. cannot achieve a hash function with different hash values corresponding to different keys, that is, it is impossible to avoid the situation where different keys are mapped to the same value, that is, Hash conflict, and because the storage space of the array is limited, the probability of hash conflict will also increase. How to resolve hash collision? There are two types of hash conflict resolution methods we commonly use: open addressing and chaining.
Find the free position in the hash table through linear detection and write the hash value:
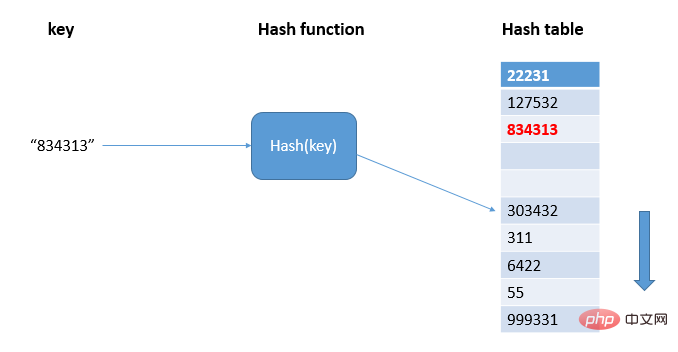
As shown in the figure, 834313 hashes to the position 303432 in the hash table, and a conflict occurs. The hash table is traversed sequentially until a free position is found and 834313 is written; when there are not many free positions in the hash table , the probability of hash conflict will be greatly increased. Under normal circumstances, we will try our best to ensure that there is a certain proportion of free slots in the hash table. At this time, we use Loading Factor to represent the number of free slots. , the calculation formula is: the loading factor of the hash table = the number of elements filled in the table/the length of the hash table. The larger the load factor, the fewer free locations and more conflicts, and the performance of the hash table will decrease.
When the amount of data is relatively small and the load factor is small, it is suitable to use the open addressing method. This is why ThreadLocalMap in java uses the open addressing method to resolve hash conflicts.
The linked list method is a more commonly used hash conflict resolution method and is simpler. As shown in the figure:
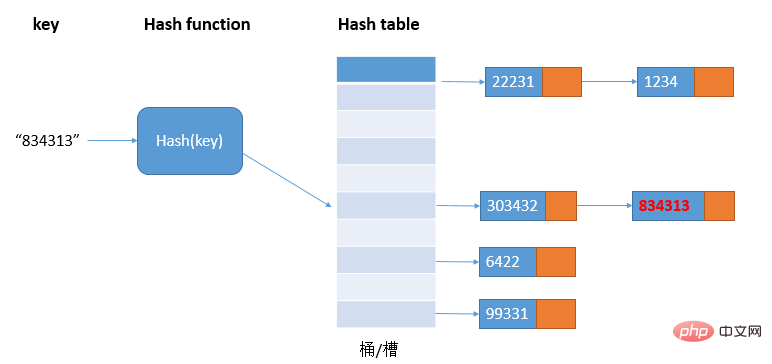
In the hash table, each bucket/slot corresponds to a linked list. All elements with the same hash value are placed in the linked list corresponding to the same slot. Medium; when there are many hash conflicts, the length of the linked list will also become longer, and querying the hash value requires traversing the linked list, and then the query efficiency will degrade from O(1) to O(n).
This method of resolving hash conflicts is more suitable for hash tables with large objects and large amounts of data, and supports more optimization strategies, such as using red-black trees instead of linked lists; jdk1.8 is designed to support HashMap For further optimization, a red-black tree is introduced. When the length of the linked list is too long (default exceeds 8), the linked list will be converted into a red-black tree. At this time, the red-black tree can be used to quickly add, delete, check, and modify to improve the performance of HashMap. When the number of red-black tree nodes is less than 8, the red-black tree is converted into a linked list. Because when the amount of data is relatively small, the red-black tree needs to maintain balance. Compared with the linked list, the performance advantage is not obvious.
The hash algorithm most commonly used for encryption is MD5 (MD5 Message-Digest Algorithm) and SHA (Secure Hash Algorithm) use the characteristics of hash to calculate a hash value that makes it difficult to reversely deduce the original data, thereby achieving the purpose of encryption.
Taking MD5 as an example, the hash value is a fixed 128-bit binary string, which can represent up to 2^128 data. This data is already an astronomical number, and the probability of hash conflict is less than 1/2^ 128. If you want to find another data that is the same as this MD5 through the exhaustive method, the time spent should be astronomical. Therefore, the hash algorithm is still difficult to crack within a limited time, which means that Encryption effect is achieved.
Using the Hash function’s data sensitivity feature, it can be used to verify whether the data during network transmission is correct. , to prevent malicious tampering.
Using the relative uniform distribution characteristics of the hash function, the hash value is used as the location value of data storage, so that the data is evenly distributed in the container in.
Use the hash algorithm to calculate the hash value of the client id address or session id, and compare the obtained hash value with the size of the server list After taking the modulo operation, the final value is the server number that should be routed to.
If we have a 1T log file, which records the user’s search keywords, we want toquickly count each The number of times the keyword has been searched , what should I do? The amount of data is relatively large and it is difficult to put it into the memory of one machine. Even if it is placed on one machine, the processing time will be very long. To solve this problem, we can first fragment the data and then use multiple machines to process it. method to increase processing speed.
The specific idea is: In order to improve the processing speed, we use n machines for parallel processing. From the log file of the search record, each search keyword is analyzed in turn, and the hash value is calculated through the hash function, and then modulo n. The final value is the machine number that should be assigned; in this way, the hash value Search keywords with the same value are assigned to the same machine. Each machine will count the number of occurrences of the keyword separately, and finally combine them to get the final result. In fact, the processing process here is also the basic design idea of MapReduce.
For situations where massive data needs to be cached, one cache machine is definitely not enough, so we need to distribute the data across multiple on a machine. At this time, we can use the previous sharding idea, that is, use the hash algorithm to obtain the hash value of the data, and then take the modulo of the number of machines to obtain the cache machine number that should be stored.
However, if the data increases, the original 10 machines can no longer bear it and need to be expanded. At this time, if all the data hash values are recalculated and then moved to the correct machine, it will be quite Since all the cached data becomes invalid at once, it will penetrate the cache and return to the source, which may cause an avalanche effect and overwhelm the database. In order to add a new cache machine without moving all the data, Consistent Hash Algorithm is a better choice. The main idea is: assuming we have a kge machine, the hash value range of the data is [0, Max], we divide the entire range into m small intervals (m is much greater than k). Each machine is responsible for m/k small intervals. When a new machine joins, we divide the data of certain small intervals from The original machine is moved to the new machine. In this way, there is no need to re-hash and move all the data, and the balance of the data volume on each machine is maintained.
In fact, the hash algorithm has many other applications, such as git commit id, etc. Many applications come from the algorithm The understanding and expansion are also the embodiment of the value of basic data structures and algorithms, which we need to slowly understand and experience in our work.
Recommended tutorial: "Java Tutorial"
The above is the detailed content of Commonly used algorithms: Hash algorithm. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



