

What are the characteristics of Kafka?
The characteristics of Kafka are: 1. Provide high throughput for both publishing and subscription; 2. Can perform persistence operations and persist messages to disk, so it can be used for batch consumption; 3. Distributed system, Easy to expand outward; 4. Supports online and offline scenarios.

Kafka’s characteristics and usage scenarios
Kafka is a distributed publish-subscribe messaging system. It was originally developed by LinkedIn Corporation and later became part of the Apache project. Kafka is a distributed, partitionable, redundant and persistent log service.
It is mainly used to process active streaming data. In big data systems, we often encounter a problem. The entire big data is composed of various subsystems. Data needs to be continuously circulated in each subsystem with high performance and low latency.
Traditional enterprise messaging systems are not very suitable for large-scale data processing. In order to handle online applications (messages) and offline applications (data files, logs) at the same time, Kafka appeared. Kafka can play two roles:
Reduce the complexity of system networking.
Reduces programming complexity. Each subsystem no longer negotiates interfaces with each other. Each subsystem is plugged into a socket like a socket. Kafka assumes the role of a high-speed data bus
Kafka main features:
Provides high throughput for both publishing and subscription. It is understood that Kafka can produce about 250,000 messages (50 MB) per second and process 550,000 messages (110 MB) per second.
Persistence operations can be performed. Persist messages to disk so they can be used for batch consumption, such as ETL, as well as real-time applications. Prevent data loss by persisting data to hard disk and replication.
Distributed system, easy to expand outward. All producers, brokers and consumers will have multiple, and they are all distributed. Machines can be expanded without downtime.
The status of message processing is maintained on the consumer side, not on the server side. Automatically balances when failure occurs.
Supports online and offline scenarios.
The design points of Kafka:
1. Directly use the cache of the Linux file system to cache data efficiently.
2. Use linux Zero-Copy to improve sending performance. Traditional data sending requires 4 context switches. After using the sendfile system call, data is exchanged directly in the kernel state, and the system context switches are reduced to 2 times. According to the test results, the data sending performance can be improved by 60%.
3. The cost of data access on disk is O(1). Kafka uses topics for message management. Each topic contains multiple parts (itions). Each part corresponds to a logical log and is composed of multiple segments. Multiple messages are stored in each segment (see the figure below). The message ID is determined by its logical location, that is, the message ID can be directly located to the storage location of the message, avoiding additional mapping of ID to location. Each part corresponds to an index in the memory, and the offset of the first message in each segment is recorded. The message sent by the publisher to a certain topic will be evenly distributed to multiple parts (randomly or distributed according to the callback function specified by the user). The broker receives the published message and adds the message to the last segment of the corresponding part. When When the number of messages on a segment reaches the configured value or the message publishing time exceeds the threshold, the messages on the segment will be flushed to the disk. Only message subscribers flushed to the disk can subscribe to it. After the segment reaches a certain size, it will no longer be available. Data will be written to the segment again, and the broker will create a new segment.
4. Explicit distribution, that is, there will be multiple producers, brokers and consumers, all of which are distributed. There is no load balancing mechanism between Producer and broker. Zookeeper is used for load balancing between brokers and consumers.
All brokers and consumers will be registered in zookeeper, and zookeeper will save some of their metadata information. If a broker or consumer changes, all other brokers and consumers will be notified.
The above is the detailed content of What are the characteristics of Kafka?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1379
1379
 52
52

 How to implement real-time stock analysis using PHP and Kafka
Jun 28, 2023 am 10:04 AM
How to implement real-time stock analysis using PHP and Kafka
Jun 28, 2023 am 10:04 AM
With the development of the Internet and technology, digital investment has become a topic of increasing concern. Many investors continue to explore and study investment strategies, hoping to obtain a higher return on investment. In stock trading, real-time stock analysis is very important for decision-making, and the use of Kafka real-time message queue and PHP technology is an efficient and practical means. 1. Introduction to Kafka Kafka is a high-throughput distributed publish and subscribe messaging system developed by LinkedIn. The main features of Kafka are
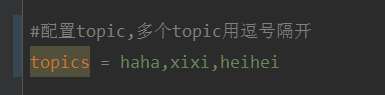 How to dynamically specify multiple topics with @KafkaListener in springboot+kafka
May 20, 2023 pm 08:58 PM
How to dynamically specify multiple topics with @KafkaListener in springboot+kafka
May 20, 2023 pm 08:58 PM
Explain that this project is a springboot+kafak integration project, so it uses the kafak consumption annotation @KafkaListener in springboot. First, configure multiple topics separated by commas in application.properties. Method: Use Spring’s SpEl expression to configure topics as: @KafkaListener(topics="#{’${topics}’.split(’,’)}") to run the program. The console printing effect is as follows
 How SpringBoot integrates Kafka configuration tool class
May 12, 2023 pm 09:58 PM
How SpringBoot integrates Kafka configuration tool class
May 12, 2023 pm 09:58 PM
spring-kafka is based on the integration of the java version of kafkaclient and spring. It provides KafkaTemplate, which encapsulates various methods for easy operation. It encapsulates apache's kafka-client, and there is no need to import the client to depend on the org.springframework.kafkaspring-kafkaYML configuration. kafka:#bootstrap-servers:server1:9092,server2:9093#kafka development address,#producer configuration producer:#serialization and deserialization class key provided by Kafka
 How to build real-time data processing applications using React and Apache Kafka
Sep 27, 2023 pm 02:25 PM
How to build real-time data processing applications using React and Apache Kafka
Sep 27, 2023 pm 02:25 PM
How to use React and Apache Kafka to build real-time data processing applications Introduction: With the rise of big data and real-time data processing, building real-time data processing applications has become the pursuit of many developers. The combination of React, a popular front-end framework, and Apache Kafka, a high-performance distributed messaging system, can help us build real-time data processing applications. This article will introduce how to use React and Apache Kafka to build real-time data processing applications, and
 Five selections of visualization tools for exploring Kafka
Feb 01, 2024 am 08:03 AM
Five selections of visualization tools for exploring Kafka
Feb 01, 2024 am 08:03 AM
Five options for Kafka visualization tools ApacheKafka is a distributed stream processing platform capable of processing large amounts of real-time data. It is widely used to build real-time data pipelines, message queues, and event-driven applications. Kafka's visualization tools can help users monitor and manage Kafka clusters and better understand Kafka data flows. The following is an introduction to five popular Kafka visualization tools: ConfluentControlCenterConfluent
 Comparative analysis of kafka visualization tools: How to choose the most appropriate tool?
Jan 05, 2024 pm 12:15 PM
Comparative analysis of kafka visualization tools: How to choose the most appropriate tool?
Jan 05, 2024 pm 12:15 PM
How to choose the right Kafka visualization tool? Comparative analysis of five tools Introduction: Kafka is a high-performance, high-throughput distributed message queue system that is widely used in the field of big data. With the popularity of Kafka, more and more enterprises and developers need a visual tool to easily monitor and manage Kafka clusters. This article will introduce five commonly used Kafka visualization tools and compare their features and functions to help readers choose the tool that suits their needs. 1. KafkaManager
 Sample code for springboot project to configure multiple kafka
May 14, 2023 pm 12:28 PM
Sample code for springboot project to configure multiple kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Configuration file related information kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#The number of threads that can be consumed concurrently (usually consistent with the number of partitions )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 How to install Apache Kafka on Rocky Linux?
Mar 01, 2024 pm 10:37 PM
How to install Apache Kafka on Rocky Linux?
Mar 01, 2024 pm 10:37 PM
To install ApacheKafka on RockyLinux, you can follow the following steps: Update system: First, make sure your RockyLinux system is up to date, execute the following command to update the system package: sudoyumupdate Install Java: ApacheKafka depends on Java, so you need to install JavaDevelopmentKit (JDK) first ). OpenJDK can be installed through the following command: sudoyuminstalljava-1.8.0-openjdk-devel Download and decompress: Visit the ApacheKafka official website () to download the latest binary package. Choose a stable version