

How does Redis implement delay queue? Method introduction


Delay queue, as the name suggests, is a message queue with delay function. So, under what circumstances do I need such a queue?
1. Background
Let’s first look at the following business scenario:
- When the order has been unpaid How to close the order in a timely manner when the order is in the refund status
- How to regularly check whether the order in the refund status has been successfully refunded
- When the order does not receive status notification from the downstream system for a long time, how to Strategies to achieve stepped synchronization of order status
- When the system notifies the upstream system of the final status of successful payment, the upstream system returns a notification failure. How to perform asynchronous notification and send it at a divided frequency: 15s 3m 10m 30m 30m 1h 2h 6h 15h
1.1 Solution
The simplest way is to scan the meter regularly . For example, if the order payment expiration requirements are relatively high, the meter will be scanned every 2 seconds to check expired orders and actively close the orders. The advantage is that it is simple, The disadvantage is that it scans the table globally every minute, which wastes resources. If the order volume of the table data is about to expire is large, it will cause a delay in order closing.
Use RabbitMq or other MQ modifications to implement delay queues. The advantages are that it is open source and a ready-made and stable implementation solution. The disadvantages are: MQ is a message middleware. If the team technology stack is inherently If you have MQ, that's fine. If not, then it's a bit expensive to deploy a set of MQ to delay the queue.
Using Redis's zset and list features, we can use redis to implement it A delay queueRedisDelayQueue
2. Design goal
- Real-time performance: Second-level errors are allowed for a certain period of time
- High availability: supports stand-alone, supports clusters
- Supports message deletion: the business will delete specified messages at any time
- Message reliability: guaranteed to be at least Consumed once
- Message persistence: Based on the persistence characteristics of Redis itself, if Redis data is lost, it means the loss of delayed messages, but primary backup and cluster guarantees can be provided. This can be considered for subsequent optimization to persist the message into MangoDB
3. Design plan
The design mainly includes the following points:
- Treat the entire Redis as a message pool and store messages in KV format
- Use ZSET as the priority queue and maintain the priority according to Score
- Use the LIST structure to advance First-out consumption
- ZSET and LIST store message addresses (corresponding to each KEY in the message pool)
- Customize the routing object, store ZSET and LIST names, and send messages from ZSET routes to the correct LIST
- Use timer to maintain routing
- Implement message delay according to TTL rules
3.1 Design diagram
It is still based on Youzan’s delay queue design, optimization and code implementation. Youzan Design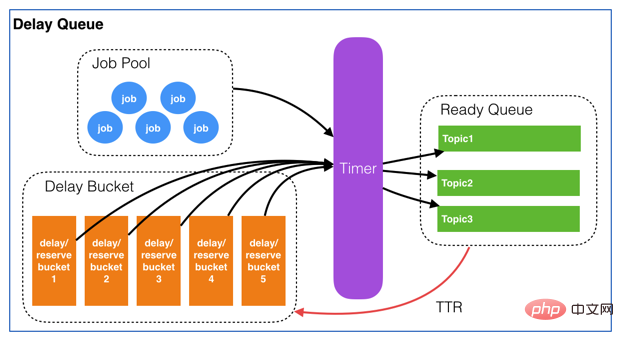
##3.2 Data Structure
- ZING:DELAY_QUEUE:JOB_POOL
It is a Hash_Table structure that stores all delay queue information. KV structure: K=prefix projectName field = topic jobId V=CONENT;VThe data passed in by the client will be returned when consuming - ZING:DELAY_QUEUE:BUCKET
There are delay queues The sequence set ZSET stores K=ID and the required execution timestamp, sorted according to the timestamp - ZING:DELAY_QUEUE:QUEUE
LIST structure, each Topic has a LIST, and the list stores The JOB
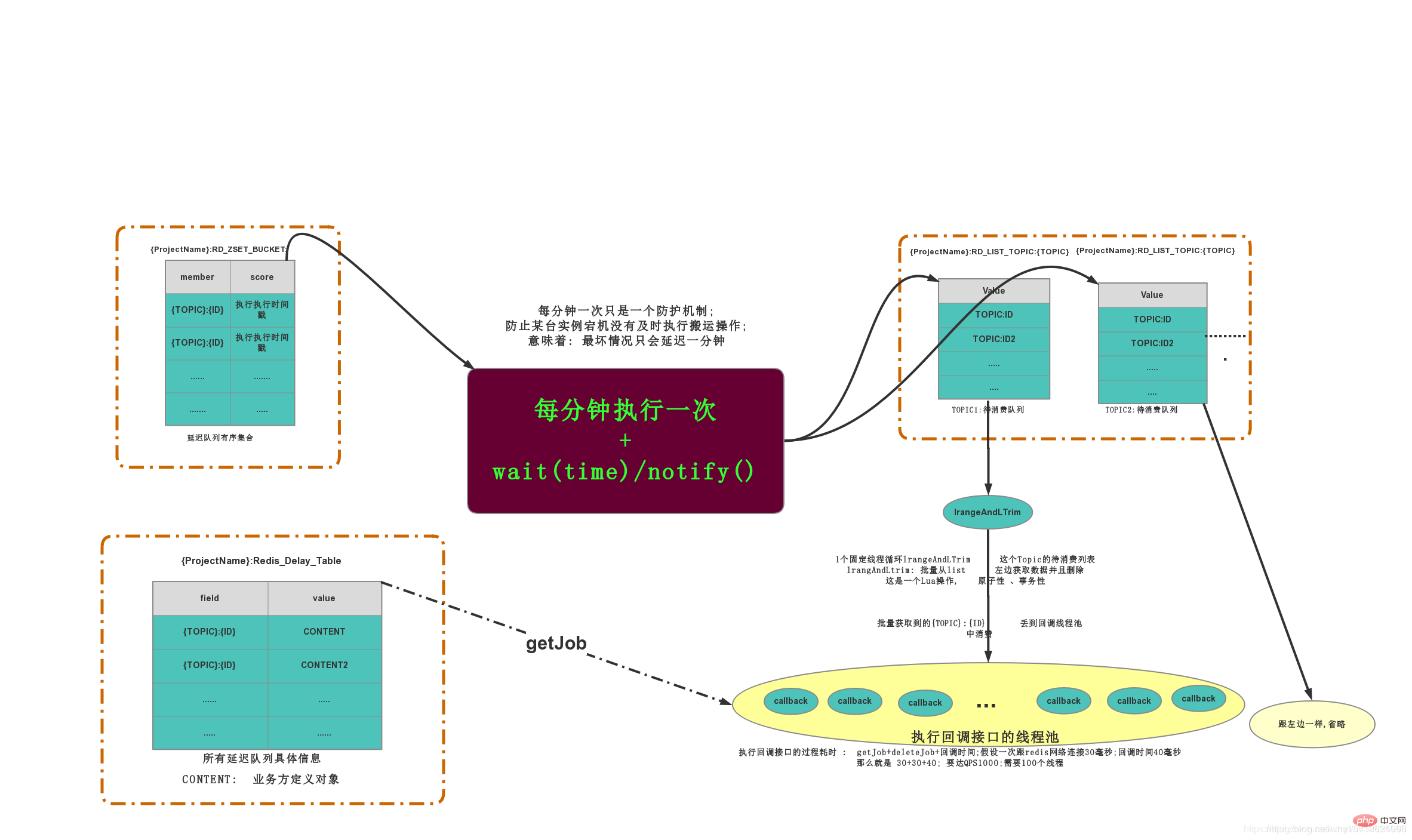 picture that currently needs to be consumed is for reference only. It can basically describe the execution of the entire process. The picture comes from the reference blog at the end of the article
picture that currently needs to be consumed is for reference only. It can basically describe the execution of the entire process. The picture comes from the reference blog at the end of the article
3.3 Task life cycle
- When a new JOB is added, a piece of data will be inserted into
- ZING:DELAY_QUEUE:JOB_POOL
and recorded Business side and consumer side.ZING:DELAY_QUEUE:BUCKETwill also insert a record to record the execution timestampThe handling thread will go to - ZING:DELAY_QUEUE:BUCKET
to find which execution timestamps RunTimeMillis is smaller than the current time, delete all these records; at the same time, it will parse what the Topic of each task is, and then push these tasks to the list corresponding to TOPICZING:DELAY_QUEUE:QUEUE中Each TOPIC LIST will have a listening thread to batch obtain the data to be consumed in the LIST, and all the acquired data will be thrown to the consumption thread pool of this TOPIC - The execution of the consumption thread pool will go
- ZING:DELAY_QUEUE:JOB_POOL
Find the data structure, return it to the callback structure, and execute the callback method.
3.4 Design Points
3.4.1 Basic concept
- JOB: Tasks that require asynchronous processing are the basic units in the delay queue
- Topic: a collection (queue) of jobs of the same type. For consumers to subscribe
3.4.2 Message structure
Each JOB must contain the following attributes
- jobId: The unique identifier of the Job. Used to retrieve and delete specified Job information
- topic: Job type. It can be understood as a specific business name
- delay: the time the job needs to be delayed. Unit: seconds. (The server will convert it into an absolute time)
- body: The content of the Job, for consumers to do specific business processing, stored in json format
- retry: Number of failed retries
- url: notification URL
3.5 Design details
3.5.1 How to consume quickly ZING:DELAY_QUEUE:QUEUE
The simplest implementation method is to use a timer to perform second-level scanning, in order to ensure the timeliness of message execution , you can set it to request Redis every 1S to determine whether there are JOBs to be consumed in the queue. But there will be a problem. If there are no consumable JOBs in the queue, then frequent scanning will be meaningless and a waste of resources. Fortunately, there is a BLPOP blocking primitive in the LIST. If the list If there is data, it will be returned immediately. If there is no data, it will be blocked there until data is returned. You can set the blocking timeout, and NULL will be returned after the timeout. The specific implementation methods and strategies will be introduced in the code.
3.5.2 Avoid repeated transfer and consumption of messages caused by timing
- Use Redis's distributed lock to control the transfer of messages. In order to avoid problems caused by repeated transfer of messages
- Use distributed locks to ensure the execution frequency of the timer
4. Core code implementation
4.1 Technical Description
Technology stack: SpringBoot, Redisson, Redis, distributed lock, timer
Note: This project does not realize the multiple Queue consumption in the design plan, and only opens one QUEUE. This will be optimized in the future
4.2 Core Entity
4.2.1 Add new objects to Job
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
4.2.2 Delete objects from Job
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
4.3 Transport thread
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
4.4 Consumer thread
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
|
4.5 Adding and deleting JOB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
|
5. Content to be optimized
- Currently there is only one Queue queue to store messages. When a large number of messages that need to be consumed accumulate, the timeliness of message notifications will be affected. The improvement method is to open multiple Queues, perform message routing, and then open multiple consumer threads for consumption to provide throughput.
- The messages are not persisted, which is risky. The messages will be persisted to MangoDB in the future.
6. Source code
Please get more detailed source code at the address below
-
RedisDelayQueue implementationzing-delay-queue(https://gitee.com/whyCodeData/zing-project/tree/master/zing-delay-queue) -
RedissonStarterredisson-spring-boot-starter(https://gitee.com/whyCodeData/zing-project/tree/master/zing-starter/redisson-spring-boot-starter) -
project applicationzing-pay(https://gitee.com/whyCodeData/zing-pay)
##7. Reference
- https://tech.youzan.com/queuing_delay/
- https://blog.csdn.net/u010634066/article/details/98864764
redis introductory tutorial column.
The above is the detailed content of How does Redis implement delay queue? Method introduction. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
Redis uses hash tables to store data and supports data structures such as strings, lists, hash tables, collections and ordered collections. Redis persists data through snapshots (RDB) and append write-only (AOF) mechanisms. Redis uses master-slave replication to improve data availability. Redis uses a single-threaded event loop to handle connections and commands to ensure data atomicity and consistency. Redis sets the expiration time for the key and uses the lazy delete mechanism to delete the expiration key.
 How to view all keys in redis
Apr 10, 2025 pm 07:15 PM
How to view all keys in redis
Apr 10, 2025 pm 07:15 PM
To view all keys in Redis, there are three ways: use the KEYS command to return all keys that match the specified pattern; use the SCAN command to iterate over the keys and return a set of keys; use the INFO command to get the total number of keys.
 How to view the version number of redis
Apr 10, 2025 pm 05:57 PM
How to view the version number of redis
Apr 10, 2025 pm 05:57 PM
To view the Redis version number, you can use the following three methods: (1) enter the INFO command, (2) start the server with the --version option, and (3) view the configuration file.
 What to do if redis-server can't be found
Apr 10, 2025 pm 06:54 PM
What to do if redis-server can't be found
Apr 10, 2025 pm 06:54 PM
Steps to solve the problem that redis-server cannot find: Check the installation to make sure Redis is installed correctly; set the environment variables REDIS_HOST and REDIS_PORT; start the Redis server redis-server; check whether the server is running redis-cli ping.
 How to use redis zset
Apr 10, 2025 pm 07:27 PM
How to use redis zset
Apr 10, 2025 pm 07:27 PM
Redis Ordered Sets (ZSets) are used to store ordered elements and sort by associated scores. The steps to use ZSet include: 1. Create a ZSet; 2. Add a member; 3. Get a member score; 4. Get a ranking; 5. Get a member in the ranking range; 6. Delete a member; 7. Get the number of elements; 8. Get the number of members in the score range.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
