

This article introduces springboot quartz to implement scheduled tasks in a persistent manner. The details are as follows:
It is long, and those who are patient can always get it. The final answer: This is my first time using quartz to do scheduled tasks. I apologize for any shortcomings.
First of all
It is relatively simple to do scheduled tasks in the springboot project. The simplest way to implement it is to use the **@Scheduled annotation. Then use @EnableScheduling** on the application startup class to enable scheduled tasks.
Example
@SpringBootApplication
@EnableScheduling
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
// cron为每秒执行一次
@Scheduled(cron = "* * * * * ?")
public void print(){
System.out.println("执行定时任务");
}
}ResultExecute scheduled tasksExecute scheduled tasks
Execute scheduled task
Execute scheduled task
Execute scheduled task
Execute scheduled task Task
Execute scheduled tasks
Execute scheduled tasks
Simple scheduled tasks can be done in this way, cron expression The result is the interval between task executions. However
In actual development, we may have many tasks, and we need to manually operate individual/all tasks, such as adding, opening , stop, continue and other operations. Then quartz will appear along with the BGM of "Qianniu Class B...".
quartzIntegration <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
is used to define Job (task) trigger conditions, trigger time, trigger interval, termination time, etc.Task job
Specific task content to be performed
UseUse quartz requires a configuration file. The default configuration file quartz.properties can be found under the org.quartz package of the quartz jar package. quartz.properties
# Default Properties file for use by StdSchedulerFactory # to create a Quartz Scheduler Instance, if a different # properties file is not explicitly specified. # # 名字 org.quartz.scheduler.instanceName: DefaultQuartzScheduler org.quartz.scheduler.rmi.export: false org.quartz.scheduler.rmi.proxy: false org.quartz.scheduler.wrapJobExecutionInUserTransaction: false # 实例化ThreadPool时,使用的线程类为SimpleThreadPool org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool # 线程总个数 org.quartz.threadPool.threadCount: 10 # 线程的优先级 org.quartz.threadPool.threadPriority: 5 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true org.quartz.jobStore.misfireThreshold: 60000 # 持久化方式,默认持久化在内存中,后面我们使用db的方式 org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore
Persistence of the quartz task to the db requires some officially defined databases Table, the sql file of the table can be found in the quartz jar package
coordinates org.quartz.impl.jdbcjobstore, you can see that there are many sql files in it, including various databases, we use MySQL, we There is no need to manually execute the sql statement, we will automatically initialize it later when starting the project.
Create our own properties file
# 实例化ThreadPool时,使用的线程类为SimpleThreadPool org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool # threadCount和threadPriority将以setter的形式注入ThreadPool实例 # 并发个数 org.quartz.threadPool.threadCount=10 # 优先级 org.quartz.threadPool.threadPriority=5 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread=true org.quartz.jobStore.misfireThreshold=5000 #持久化使用的类 org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX #数据库中表的前缀 org.quartz.jobStore.tablePrefix=QRTZ_ #数据源命名 org.quartz.jobStore.dataSource=qzDS #qzDS 数据源,我们使用hikaricp,默认的是c3p0 org.quartz.dataSource.qzDS.provider=hikaricp org.quartz.dataSource.qzDS.driver=com.mysql.cj.jdbc.Driver org.quartz.dataSource.qzDS.URL=jdbc:mysql://localhost:3306/quartz?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8 org.quartz.dataSource.qzDS.user=root org.quartz.dataSource.qzDS.password=123456 org.quartz.dataSource.qzDS.maxConnections=10
Since we are not using the default connection pool, let’s explore it and get the source code! Under this package: org.quartz.utils, there is a PoolingConnectionProvider. As the name suggests, the connection pool provider part source code
public interface PoolingConnectionProvider extends ConnectionProvider {
/** The pooling provider. */
String POOLING_PROVIDER = "provider";
/** The c3p0 pooling provider. */
String POOLING_PROVIDER_C3P0 = "c3p0";
/** The Hikari pooling provider. */
String POOLING_PROVIDER_HIKARICP = "hikaricp";
}Then HikariCpPoolingConnectionProvider class implements PoolingConnectionProvider, check it out yourself. We can search for c3p0 in StdSchedulerFactory under org.quartz.impl and find
if(poolingProvider != null && poolingProvider.equals(PoolingConnectionProvider.POOLING_PROVIDER_HIKARICP)) {
cpClass = "org.quartz.utils.HikariCpPoolingConnectionProvider";
}
else {
cpClass = "org.quartz.utils.C3p0PoolingConnectionProvider";
}Let’s take a look at the rest. Researching the initial source code is not as difficult or boring as imagined (I don’t like to read the source code either) ), but this source code does seem to have a small sense of accomplishment.
Go back to the topic channel and configure application.yml
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver password: 123456 url: jdbc:mysql://localhost:3306/quartz?characterEncoding=UTF8&useSSL=false&serverTimezone=GMT%2B8 username: root quartz: jdbc: initialize-schema: always job-store-type: jdbc
initialize-schema: always Every time you start the project, always initialize the database table and automatically create the key place of the table. The process is to delete the database table first. , create again, if the table does not exist, an exception will be thrown, but it will not affect the subsequent generated table. When the project is started next time, since the table already exists, the exception will not be thrown job-store-type: jdbc It is the task persistence type. When we use jdbc
, we may need to inject the spring object into the job. Without configuration, it cannot be injected.
/**
* @author: taoym
* @date: 2020/6/4 11:32
* @desc: 一定要自定义JobFactory重写SpringBeanJobFactory的createJobInstance方法,否则在job中是获取不到spring容器中的bean的
*/
@Component
public class JobFactory extends SpringBeanJobFactory {
@Autowired
private AutowireCapableBeanFactory beanFactory;
/**
* 这里覆盖了super的createJobInstance方法,对其创建出来的类再进行autowire
*/
@Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {
Object jobInstance = super.createJobInstance(bundle);
beanFactory.autowireBean(jobInstance);
return jobInstance;
}
}Create quartz configuration file
@Configuration
public class QuartzConfig {
@Autowired
private JobFactory jobFactory;
/**
* 读取quartz.properties 文件
* 将值初始化
*
* @return
*/
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
SchedulerFactoryBean schedulerFactoryBean = new SchedulerFactoryBean();
schedulerFactoryBean.setJobFactory(jobFactory);
schedulerFactoryBean.setQuartzProperties(quartzProperties());
return schedulerFactoryBean;
}
/**
* 初始化监听器
*
* @return
*/
@Bean
public QuartzInitializerListener executorListener() {
return new QuartzInitializerListener();
}
@Bean(name = "scheduler")
public Scheduler scheduler() throws IOException {
return schedulerFactoryBean().getScheduler();
}
}Create trigger component
public class TriggerComponent {
/**
* @author: taoym
* @date: 2020/6/1 10:35
* @desc: 构建cron触发器
*/
public static Trigger cronTrigger(String cron) {
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule(cron).withMisfireHandlingInstructionDoNothing())
.build();
return cronTrigger;
}
public static Trigger cronTrigger(String cron, JobDataMap jobDataMap) {
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule(cron).withMisfireHandlingInstructionDoNothing())
.usingJobData(jobDataMap)
.build();
return cronTrigger;
}
}Just use this component to obtain the trigger.
Create Task
@DisallowConcurrentExecution
public class TestJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
}
}jobExecutionContext Here you can get information such as task group, task name, trigger group, trigger name, jobdetail, etc. That annotation is to allow the same instance (jobdetail) to be executed only in a single thread. It can be understood that job is the interface, jobdetail is the implementation class, and a is one of the implementation classes. It takes 100s to perform a certain operation, and the timer you gave will perform an operation every 50s. When a is halfway through the execution Another thread needs to be started for execution. Using DisallowConcurrentExecution means that when a has not completed the operation, a is not allowed to open the thread and then perform the current operation. I don’t know if my description is easy to understand!
Create your own task list on demand. I use scheduled tasks to make crawlers (small crawlers)
CREATE TABLE `quartz_job` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号', `job_name` varchar(50) DEFAULT '' COMMENT '任务名', `job_group` varchar(50) DEFAULT '' COMMENT '任务组名称', `job_desc` varchar(255) DEFAULT '' COMMENT 'job描述', `cron` varchar(50) DEFAULT '' COMMENT 'cron表达式', `status` tinyint(1) DEFAULT '0' COMMENT '状态', `url` varchar(255) DEFAULT '' COMMENT '请求地址', `param` varchar(255) DEFAULT '' COMMENT '参数', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=31 DEFAULT CHARSET=utf8;
When we add tasks, we don’t deal with quartz, just put the tasks in the database. . Don't panic, he will be useful later. This table needs to be added, deleted, modified and checked. We will query the task list in the system and select a single or all tasks to start executing
Execute tasks
@Resource
private QuartzJobMapper quartzJobMapper;
@Autowired
private Scheduler scheduler;
@Override
public String start(Integer id) {
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put(k,v);
QuartzJob quartzJob = quartzJobMapper.selectByPrimaryKey(id);
JobKey jobKey = JobKey.jobKey(quartzJob.getJobName(), quartzJob.getJobGroup());
jobDetail = JobBuilder.newJob(TestJob.class).withIdentity(jobKey).storeDurably().build();
Trigger trigger = TriggerComponent.cronTrigger(quartzJob.getCron(), jobDataMap);
try {
scheduler.scheduleJob(jobDetail, trigger);
quartzJobMapper.updateStatus(true, id);
return "开始任务执行成功";
} catch (SchedulerException se) {
log.info("开始任务的时候发生了错误");
}
return "开始任务的时候发生了错误,请检查日志";
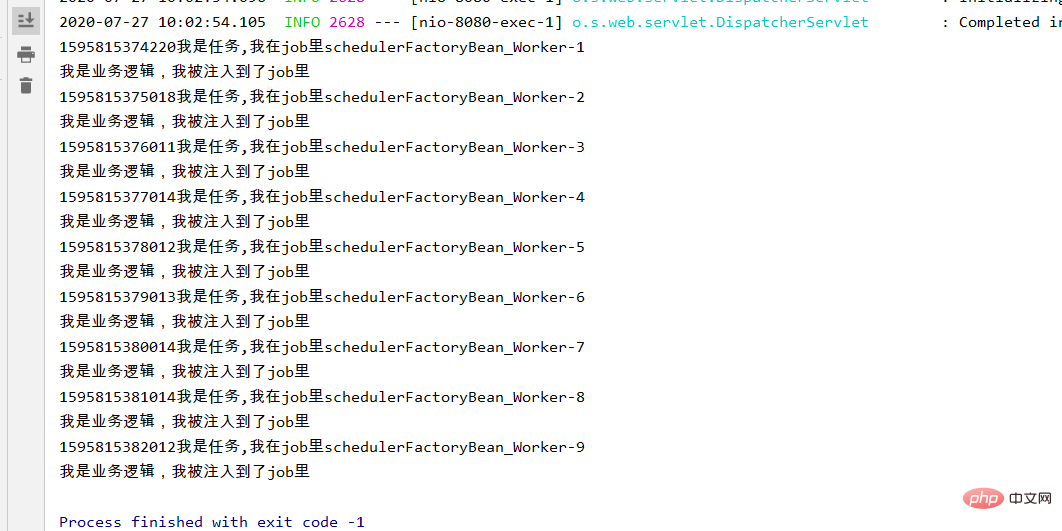
}Finally, I pasted it according to the content of this tutorial Once the code is passed, it can run normally. 



Recommended tutorial: "PHP"
The above is the detailed content of springboot+quartz implements scheduled tasks in a persistent manner. For more information, please follow other related articles on the PHP Chinese website!
 SpringBoot project building steps
SpringBoot project building steps
 What is the difference between j2ee and springboot
What is the difference between j2ee and springboot
 Introduction to java access control modifiers
Introduction to java access control modifiers
 Free website domain name
Free website domain name
 Solution to slow access speed when renting a US server
Solution to slow access speed when renting a US server
 Usage of base keyword in C#
Usage of base keyword in C#
 Ranking of the top ten digital currency exchanges
Ranking of the top ten digital currency exchanges
 How to introduce external css into html
How to introduce external css into html









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



