
 Web Front-end
Front-end Q&A
A brief discussion on crawlers and bypassing website anti-crawling mechanisms
Web Front-end
Front-end Q&A
A brief discussion on crawlers and bypassing website anti-crawling mechanisms
A brief discussion on crawlers and bypassing website anti-crawling mechanisms


【Related learning recommendations: Website production video tutorial】
What is a crawler? To put it simply and one-sidedly, a crawler is a tool that allows a computer to automatically interact with a server to obtain data. The most basic thing of a crawler is to get the source code data of a web page. If you go deeper, you will have POST interaction with the web page and get the data returned by the server after receiving the POST request. In a word, crawlers are used to automatically obtain source data. As for more data processing, etc., they are follow-up work. This article mainly wants to talk about this part of crawlers obtaining data. Crawlers, please pay attention to the Robot.txt file of the website. Do not let crawlers break the law or cause harm to the website.
Inappropriate examples of anti-crawling and anti-anti-crawling concepts
Due to many reasons (such as server resources, data protection, etc.), many websites limit the effectiveness of crawlers .
Think about it, if a human plays the role of a crawler, how do we obtain the source code of a web page? The most commonly used method is of course right-clicking the source code.
The website blocks the right click, what should I do?

Take out the most useful thing we use in crawling, F12 (welcome to discuss)
Press F12 at the same time to open it (funny)
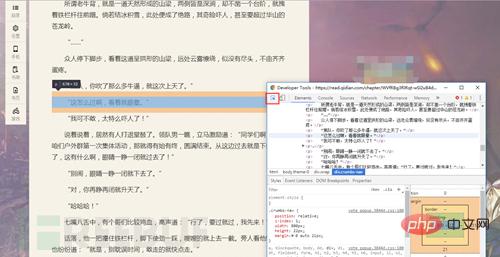
The source code is out!!
When treating people as crawlers, block the right click It is the anti-crawling strategy, and F12 is the anti-crawling method.
Let’s talk about the formal anti-crawling strategy
In fact, in the process of writing a crawler, there must be a situation where no data is returned. In this case, the server may Limiting the UA header (user-agent), this is a very basic anti-crawling. Just add the UA header when sending the request... Isn't it very simple? Adding all the required Request Headers is a simple and crude method...
Have you ever discovered that the verification code of the website is also an anti-crawling strategy? In order to ensure that the users of the website are real people, the verification code is really done A great contribution. Along with the verification code, verification code recognition appeared.
Speaking of which, I wonder whether verification code recognition or image recognition came first?
It is very simple to recognize simple verification codes now. There are too many tutorials on the Internet, including a little Advanced concepts such as denoising, binary, segmentation, and reorganization. But now website human-machine recognition has become more and more terrifying, such as this:
 Let’s briefly talk about the concept of denoising binary values
Let’s briefly talk about the concept of denoising binary values
Will a verification The code
 becomes
becomes
 which is a binary value, that is, changing the picture itself into only two tones, example It's very simple. It can be achieved through
which is a binary value, that is, changing the picture itself into only two tones, example It's very simple. It can be achieved through
Image.convert("1")
in the python PIL library. However, if the image becomes more complex, you still need to think more, such as
 If you use the simple method directly, it will become
If you use the simple method directly, it will become
 Think about how to identify this verification code? This At this time, denoising comes in handy. Based on the characteristics of the verification code itself, the background color of the verification code and the RGB values other than the font can be calculated, and these values can be turned into a color, leaving the fonts alone. The sample code is as follows, just change the color
Think about how to identify this verification code? This At this time, denoising comes in handy. Based on the characteristics of the verification code itself, the background color of the verification code and the RGB values other than the font can be calculated, and these values can be turned into a color, leaving the fonts alone. The sample code is as follows, just change the color
for x in range(0,image.size[0]): for y in range(0,image.size[1]): # print arr2[x][y] if arr[x][y].tolist()==底色: arr[x][y]=0 elif arr[x][y].tolist()[0] in range(200,256) and arr[x][y].tolist()[1] in range(200,256) and arr[x][y].tolist()[2] in range(200,256): arr[x][y]=0 elif arr[x][y].tolist()==[0,0,0]: arr[x][y]=0 else: arr[x][y]=255
Arr is obtained by numpy. The matrix is obtained based on the RGB values of the image. Readers can try to improve the code and experiment for themselves.
After careful processing, the picture can become
The recognition rate is still very high.
In the development of verification codes, there are wheels available online for fairly clear numbers and letters, simple addition, subtraction, multiplication and division. For some difficult numbers, letters and Chinese characters, you can also make your own wheels (such as the above), but there are more Things are enough to write an artificial intelligence... (One kind of job is to recognize verification codes...)
Add a little tip: Some websites have verification codes on the PC side, but not on the mobile phone side...
Next topic!
One of the more common anti-crawling strategies is the IP blocking strategy. Usually too many visits in a short period of time will be blocked. This It's very simple. It's OK to limit the access frequency or add an IP proxy pool. Of course, it can also be distributed... Not used much but still ok.
Another kind of anti-crawler strategy is asynchronous data. With the gradual deepening of crawlers (it is obviously an update of the website!), asynchronous loading is a problem that will definitely be encountered, and the solution is still It's F12. Take the anonymous NetEase Cloud Music website as an example. After right-clicking to open the source code, try searching for comments
 Where is the data?! This is asynchronous after the rise of JS and Ajax. Loaded features. But open F12, switch to the NetWork tab, refresh the page, and search carefully, there is no secret.
Where is the data?! This is asynchronous after the rise of JS and Ajax. Loaded features. But open F12, switch to the NetWork tab, refresh the page, and search carefully, there is no secret.
 Oh, by the way, if you are listening to the song, you can download it by clicking in...
Oh, by the way, if you are listening to the song, you can download it by clicking in...
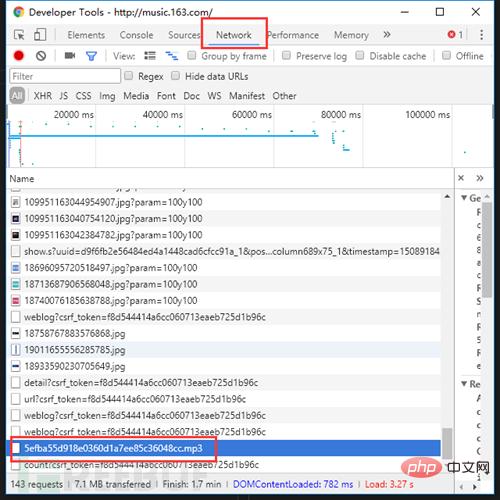 Only To popularize the structure of the website, please consciously resist piracy, protect copyright, and protect the interests of the original creator.
Only To popularize the structure of the website, please consciously resist piracy, protect copyright, and protect the interests of the original creator.
What should you do if this website restricts you? We have one last plan, an invincible combination: selenium PhantomJs
This combination is very powerful and can be perfect Simulate browser behavior. Please refer to Baidu for specific usage. This method is not recommended. It is very cumbersome. This is only for popular science.
The above is the detailed content of A brief discussion on crawlers and bypassing website anti-crawling mechanisms. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 How long does it take to learn python crawler
Oct 25, 2023 am 09:44 AM
How long does it take to learn python crawler
Oct 25, 2023 am 09:44 AM
The time it takes to learn Python crawlers varies from person to person and depends on factors such as personal learning ability, learning methods, learning time and experience. Learning Python crawlers is not just about learning the technology itself, but also requires good information gathering skills, problem solving skills and teamwork skills. Through continuous learning and practice, you will gradually grow into an excellent Python crawler developer.
 PHP crawler practice: crawling data on Twitter
Jun 13, 2023 pm 01:17 PM
PHP crawler practice: crawling data on Twitter
Jun 13, 2023 pm 01:17 PM
In the digital age, social media has become an indispensable part of people's lives. Twitter is one of them, with hundreds of millions of users sharing various information on it every day. For some research, analysis, promotion and other needs, it is very necessary to obtain relevant data on Twitter. This article will introduce how to use PHP to write a simple Twitter crawler to crawl some keyword-related data and store it in the database. 1. TwitterAPI provided by Twitter
 Crawler Tips: How to Handle Cookies in PHP
Jun 13, 2023 pm 02:54 PM
Crawler Tips: How to Handle Cookies in PHP
Jun 13, 2023 pm 02:54 PM
In crawler development, handling cookies is often an essential part. As a state management mechanism in HTTP, cookies are usually used to record user login information and behavior. They are the key for crawlers to handle user authentication and maintain login status. In PHP crawler development, handling cookies requires mastering some skills and paying attention to some pitfalls. Below we explain in detail how to handle cookies in PHP. 1. How to get Cookie when writing in PHP
 Analysis and solutions to common problems of PHP crawlers
Aug 06, 2023 pm 12:57 PM
Analysis and solutions to common problems of PHP crawlers
Aug 06, 2023 pm 12:57 PM
Analysis of common problems and solutions for PHP crawlers Introduction: With the rapid development of the Internet, the acquisition of network data has become an important link in various fields. As a widely used scripting language, PHP has powerful capabilities in data acquisition. One of the commonly used technologies is crawlers. However, in the process of developing and using PHP crawlers, we often encounter some problems. This article will analyze and give solutions to these problems and provide corresponding code examples. 1. Description of the problem that the data of the target web page cannot be correctly parsed.
 Efficient Java crawler practice: sharing of web data crawling techniques
Jan 09, 2024 pm 12:29 PM
Efficient Java crawler practice: sharing of web data crawling techniques
Jan 09, 2024 pm 12:29 PM
Java crawler practice: How to efficiently crawl web page data Introduction: With the rapid development of the Internet, a large amount of valuable data is stored in various web pages. To obtain this data, it is often necessary to manually access each web page and extract the information one by one, which is undoubtedly a tedious and time-consuming task. In order to solve this problem, people have developed various crawler tools, among which Java crawler is one of the most commonly used. This article will lead readers to understand how to use Java to write an efficient web crawler, and demonstrate the practice through specific code examples. 1. The base of the reptile
 Efficiently crawl web page data: combined use of PHP and Selenium
Jun 15, 2023 pm 08:36 PM
Efficiently crawl web page data: combined use of PHP and Selenium
Jun 15, 2023 pm 08:36 PM
With the rapid development of Internet technology, Web applications are increasingly used in our daily work and life. In the process of web application development, crawling web page data is a very important task. Although there are many web scraping tools on the market, these tools are not very efficient. In order to improve the efficiency of web page data crawling, we can use the combination of PHP and Selenium. First, we need to understand what PHP and Selenium are. PHP is a powerful
 Practical crawler practice: using PHP to crawl stock information
Jun 13, 2023 pm 05:32 PM
Practical crawler practice: using PHP to crawl stock information
Jun 13, 2023 pm 05:32 PM
The stock market has always been a topic of great concern. The daily rise, fall and changes in stocks directly affect investors' decisions. If you want to understand the latest developments in the stock market, you need to obtain and analyze stock information in a timely manner. The traditional method is to manually open major financial websites to view stock data one by one. This method is obviously too cumbersome and inefficient. At this time, crawlers have become a very efficient and automated solution. Next, we will demonstrate how to use PHP to write a simple stock crawler program to obtain stock data. allow
 PHP practice: crawling Bilibili barrage data
Jun 13, 2023 pm 07:08 PM
PHP practice: crawling Bilibili barrage data
Jun 13, 2023 pm 07:08 PM
Bilibili is a popular barrage video website in China. It is also a treasure trove, containing all kinds of data. Among them, barrage data is a very valuable resource, so many data analysts and researchers hope to obtain this data. In this article, I will introduce the use of PHP language to crawl Bilibili barrage data. Preparation work Before starting to crawl barrage data, we need to install a PHP crawler framework Symphony2. You can enter through the following command
