

Detailed explanation of Redis's LRU algorithm

The following column Redis Tutorial will give you a detailed explanation of Redis's LRU algorithm. I hope it will be helpful to friends in need!

Redis's LRU algorithm
The idea behind the LRU algorithm is ubiquitous in computer science, and it is very similar to the "locality principle" of the program . In a production environment, although there are Redis memory usage alarms, it is still beneficial to understand Redis's cache usage strategy. The following is the Redis usage strategy in the production environment: the maximum available memory is limited to 4GB, and the allkeys-lru deletion strategy is adopted. The so-called deletion strategy: When redis usage has reached the maximum memory, such as 4GB, if a new Key is added to redis at this time, Redis will select a Key to delete. So how to choose the appropriate Key to delete?
CONFIG GET maxmemory
- "maxmemory"
- "4294967296"
CONFIG GET maxmemory-policy
- "maxmemory-policy"
- "allkeys-lru"
In the official document Using Redis as an LRU cache description, several are provided A variety of deletion strategies, such as allkeys-lru, volatile-lru, etc. In my opinion, three factors are considered when selecting: randomness, the time when the Key was recently accessed, and the expiration time of the Key (TTL)
For example: allkeys-lru, "Count all "Key historical access time, remove the "oldest" Key. Note: I added quotation marks here. In fact, in the specific implementation of redis, it is very costly to count the recent access time of all Keys. Think about it, how to do it?
evict keys by trying to remove the less recently used (LRU) keys first, in order to make space for the new data added.Another example: allkeys- Random means randomly selecting a Key and removing it.
evict keys randomly in order to make space for the new data added.Another example: volatile-lru, which only removes those that have expired using the expire command The time key is removed according to the LRU algorithm.
evict keys by trying to remove the less recently used (LRU) keys first, but only among keys that have anAnother example: volatile-ttl, which only removes those Keys whose expiration time is set using the expire command. Which Key has a shorter survival time (the smaller the TTL KEY), it will be moved first. remove.expire set, in order to make space for the new data added.
evict keys with anThe Keys that volatile strategies (eviction methods) work on are those Keys with an expiration time set. In the redisDb structure, a dictionary (dict) named expires is defined to saveexpire set, and try to evict keys with a shorter time to live (TTL) first, in order to make space for the new data added.
all the keys with expiration time set by the expire command, where the keys of the expires dictionary point to the redis database key space (redisServer-- ->redisDb--->redisObject), and the value of the expires dictionary is the expiration time of this key (long type integer). An additional mention: the redis database key space refers to: a pointer named "dict" defined in the structure redisDb and of type hash dictionary, which is used to save each key object in the redis DB. and the corresponding value object.
Power-law distribution (power-law distribution), In addition, the access mode of Key may also change over time, so a suitable deletion strategy is needed to catch (capture) various situations. Under the power exponential distribution, LRU is a good strategy:
While caches can't predict the future, they can reason in the following way:Implementation of LRU strategy in RedisThe most intuitive idea: LRU, record the most recent access time of each key (such as unix timestamp). The key with the smallest unix timestamp is the one that has not been used recently, and remove this key. It seems that a HashMap can do it. Yes, but first you need to store each Key and its timestamp. Secondly, the timestamp must be compared to get the minimum value. The cost is very high and unrealistic. The second method: change the perspective, do not record the specific access time point (unix timestamp), but record the idle time: the smaller the idle time, it means that it was accessed recently.keys that are likely to be requested again are keys that were recently requested often. Since usually access patterns don't change very suddenly, this is an effective strategy.
The LRU algorithm evicts the Least Recently Used key, which means the one with the greatest idle time.
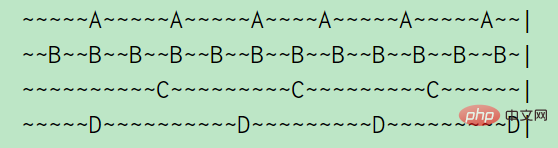
For example, A, B, C , D four keys, A is accessed every 5s, B is accessed every 2s, C and D are accessed every 10s. (A tilde represents 1s), as can be seen from the above picture: A's idle time is 2s, B's idle time is 1s, C's idle time is 5s, D just visited so the idle time is 0s
Here, use a doubly linked list to list all the Keys. If a Key is accessed, move the Key to the head of the linked list. When you want to remove the Key, remove it directly from the end of the list.
It is simple to implement because all we need to do is to track the last time a given key was accessed, or sometimes this is not even needed: we may just have all the objects we want to evict linked in a linked list.
But in redis, it is not implemented in this way because it thinks LinkedList takes up too much space. Redis does not implement the KV database directly based on data structures such as strings, linked lists, and dictionaries. Instead, it creates an object system Redis Object based on these data structures. A 24-bit unsigned field is defined in the redisObject structure to store the last time the object was accessed by the command program:
By modifying a bit the Redis Object structure I was able to make 24 bits of space. There was no room for linking the objects in a linked list (fat pointers!)
After all, a completely accurate LRU algorithm is not required, even if the most recent one is removed The accessed Key has little impact.
To add another data structure to take this metadata was not an option, however since LRU is itself an approximation of what we want to achieve, what about approximating LRU itself?
Originally Redis was implemented like this:
Randomly select three Keys and remove the Key with the largest idle time. Later, 3 was changed to a configurable parameter, and the default was N=5: maxmemory-samples 5
when there is to evict a key, select 3 random keys, and evict the one with the highest idle time
It’s so simple, unbelievably simple, and very effective. But it still has shortcomings: every time it is randomly selected, historical information is not used. When removing (evict) a Key in each round, randomly select a Key from N and remove the Key with the largest idle time; in the next round, randomly select a Key from N... Have you thought about it? Past: In the process of removing Keys in the last round, we actually knew the idle time of N Keys. Can I make good use of some of the information I learned in the previous round when removing Keys in the next round?
However if you think at this algorithm across its executions, you can see how we are trashing a lot of interesting data. Maybe when sampling the N keys, we encounter a lot of good candidates, but we then just evict the best, and start from scratch again the next cycle.
start from scratch is too silly. So Redis made another improvement: using buffer pooling
When the Key is removed in each round, the idle time of the N Keys is obtained. If its idle time is longer than the Key in the pool If the idle time is still larger, add it to the pool. In this way, the Key removed each time is not only the largest among the N Keys randomly selected, but also the largest idle time in the pool, and: the Key in the pool has been screened through multiple rounds of comparison, and its idle time The time is more likely to be larger than the idle time of a randomly obtained Key. It can be understood as follows: the Key in the pool retains "historical experience information".
Basically when the N keys sampling was performed, it was used to populate a larger pool of keys (just 16 keys by default). This pool has the keys sorted by idle time, so new keys only enter the pool when they have an idle time greater than one key in the pool or when there is empty space in the pool.
Using "pool", a global sorting problem is transformed into a local one Comparison question. (Although sorting is essentially comparison, 囧). To know the key with the largest idle time, accurate LRU needs to sort the idle time of the global keys, and then find the key with the largest idle time. However, an approximate idea can be adopted, that is, randomly sampling several keys, which represent the global keys, putting the keys obtained by sampling into the pool, and updating the pool after each sampling, so that the keys in the pool The keys with the largest idle time among randomly selected keys are always saved. When an evict key is needed, directly take out the key with the largest idle time from the pool and evict it. This idea is worth learning from.
At this point, the analysis of the LRU-based removal strategy is complete. There is also a removal strategy based on LFU (access frequency) in Redis, which I will talk about later.
LRU implementation in JAVA
LinkedHashMap in JDK implements the LRU algorithm, using the following construction method, accessOrder represents the "least recently used" measurement standard. For example, accessOrder=true, when executing the java.util.LinkedHashMap#get element, it means that this element has been accessed recently.
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}Then rewrite: java.util.LinkedHashMap#removeEldestEntry method.
The {@link #removeEldestEntry(Map.Entry)} method may be overridden to impose a policy for removing stale mappings automatically when new mappings are added to the map.
In order to ensure thread safety, use Collections.synchronizedMap to wrap the LinkedHashMap object:
Note that this implementation is not synchronized. If multiple threads access a linked hash map concurrently, and at least one of the threads modifies the map structurally, it must be synchronized externally. This is typically accomplished by synchronizing on some object that naturally encapsulates the map.
Implemented as follows: (org.elasticsearch.transport.TransportService)
final Map<Long, TimeoutInfoHolder> timeoutInfoHandlers =
Collections.synchronizedMap(new LinkedHashMap<Long, TimeoutInfoHolder>(100, .75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 100;
}
});When the capacity exceeds 100, the LRU strategy begins: evict the least recently unused TimeoutInfoHolder object.
Reference link:
- Random notes on improving the Redis LRU algorithm
- Using Redis as an LRU cache
Finally, again Let’s talk about something unrelated to this article: some thoughts on data processing:
5G has the ability to allow all kinds of nodes to connect to the network, which will generate a large amount of data. How to process this data and mine data efficiently? The hidden patterns behind (machine learning, deep learning) are a very interesting thing, because these data are actually objective reflections of human behavior. For example, the step counting function of WeChat Sports will let you find: Hey, it turns out that my activity level is about 10,000 steps every day. Going one step further, various industrial equipment and household appliances will generate a variety of data in the future. These data are a reflection of social business activities and human activities. How to make reasonable use of this data? Can the existing storage system support the storage of this data? Is there an efficient computing system (spark or tensorflow...) to analyze the value hidden in the data? In addition, will the algorithm model trained based on these data bring bias after application? Is there any misuse of data? Algorithms will recommend things to you when you buy things online. Targeted ads will be placed on you when browsing Moments. Models will also evaluate how much money you need to borrow and how much you want to borrow. Algorithms will also recommend you when reading news and entertainment gossip. Many of the things you see and come into contact with every day are decisions made by these "data systems". Are they really fair? In reality, if you make a mistake and your teachers, friends, and family give you feedback and corrections, and you change it, you can start from scratch. But what about under these data systems? Is there a feedback mechanism for error correction? Will it stimulate people to sink deeper and deeper? Even if you are upright and have good credit, the algorithm model may still have probabilistic biases. Does this affect the opportunity for "fair competition" for humans? These are questions worth thinking about for data developers.
Original text: https://www.cnblogs.com/hapjin/p/10933405.html
The above is the detailed content of Detailed explanation of Redis's LRU algorithm. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
Redis uses hash tables to store data and supports data structures such as strings, lists, hash tables, collections and ordered collections. Redis persists data through snapshots (RDB) and append write-only (AOF) mechanisms. Redis uses master-slave replication to improve data availability. Redis uses a single-threaded event loop to handle connections and commands to ensure data atomicity and consistency. Redis sets the expiration time for the key and uses the lazy delete mechanism to delete the expiration key.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
Redis, as a message middleware, supports production-consumption models, can persist messages and ensure reliable delivery. Using Redis as the message middleware enables low latency, reliable and scalable messaging.
