
The following column Redis Tutorial will give you a detailed explanation of the jump table of the Redis data structure. I hope it will be helpful to friends in need!

The jump list is an ordered data structure that maintains multiple pointers to other nodes in each node. To achieve the purpose of quickly accessing nodes. In this way, it may be difficult for us to understand, we can first recall the linked list.
For a singly linked list, even if the data stored in the linked list is ordered, if we want To find certain data in it, you can only traverse the linked list from beginning to end. In this way, the search efficiency will be very low, and the time complexity will be very high, which is O(n).
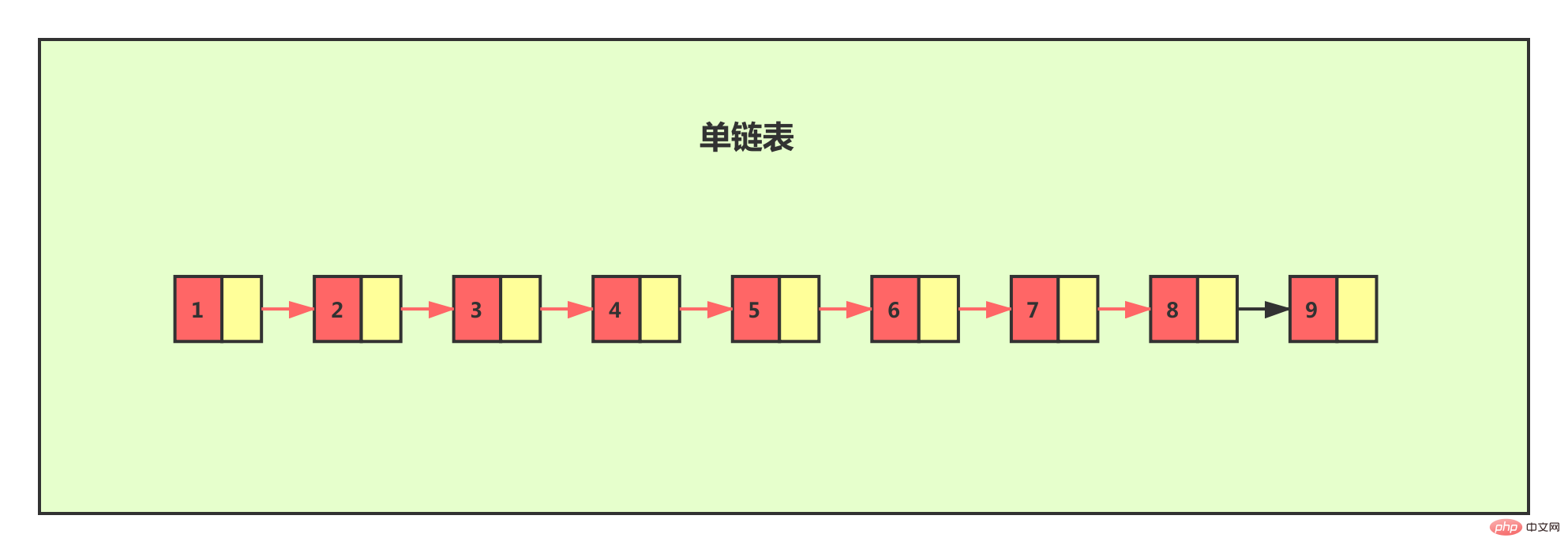
If we want to improve the search efficiency, we can consider building an index on the linked list. Extract one node from every two nodes to the previous level, and we call the extracted level the index. 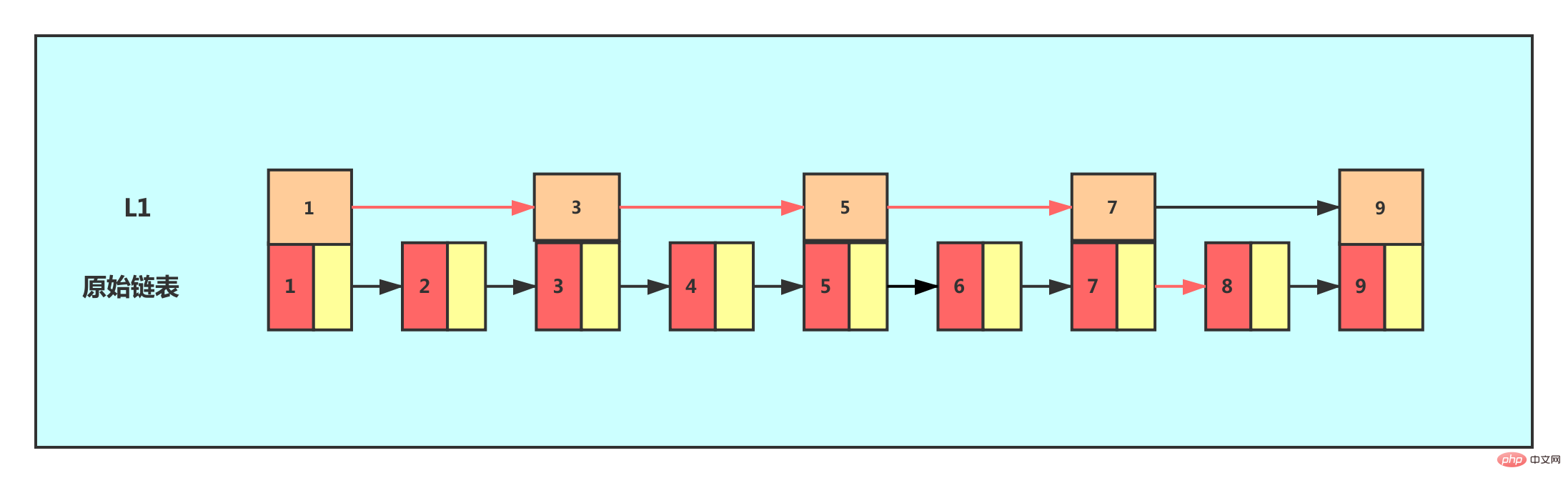
At this time, we assume that we want to find node 8. We can traverse in the index layer first. When we traverse to the node with a value of 7 in the index layer, we find that the next node is 9, then we need to The node 8 being searched for must be between these two nodes. We descended to the linked list level and continued traversing to find the node 8. Originally, we needed to traverse 8 nodes to find node 8 in a singly linked list, but now with the first-level index, we only need to traverse five nodes.
From this example, we can see that after adding a layer of index, the number of nodes that need to be traversed to find a node is reduced, which means that the search efficiency is improved. For the same reason, add another level. index.
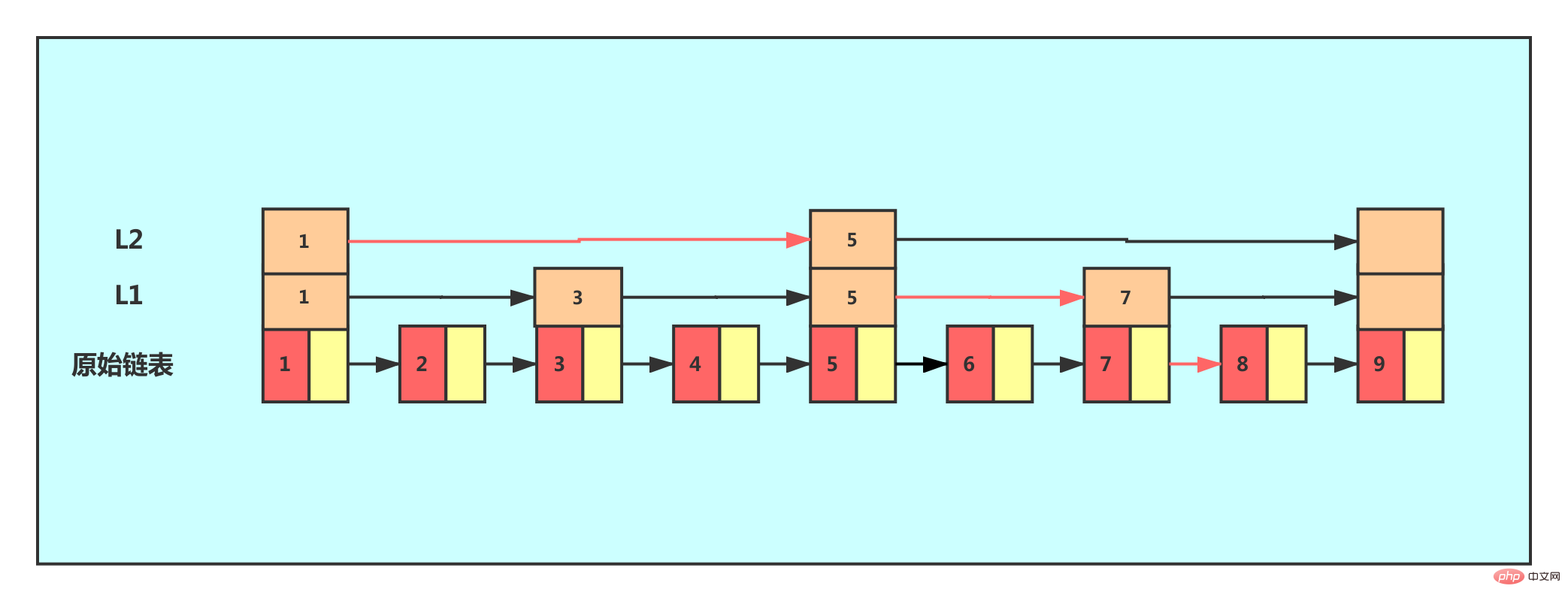
We can see from the picture that the search efficiency has improved again. In our example, we have very little data. When there is a large amount of data, we can add multi-level indexes, and the search efficiency can be significantly improved.
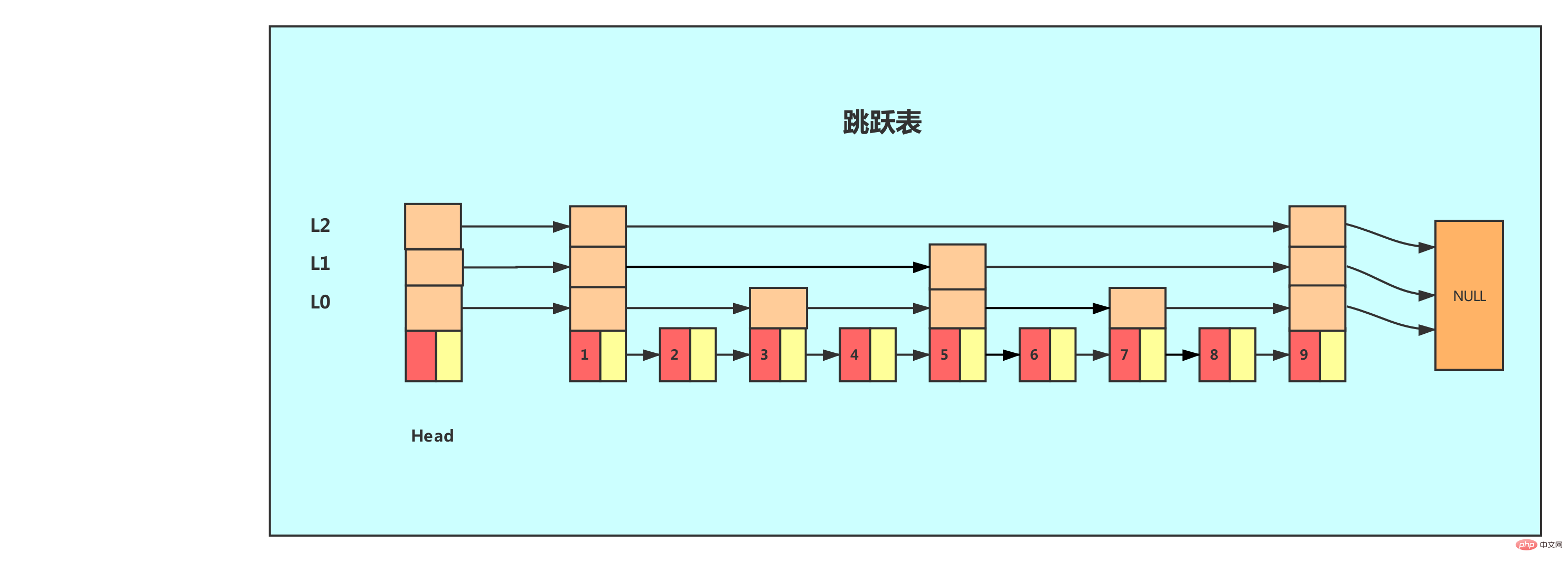
A structure like this linked list plus multi-level index is a jump list!
Redis uses jump table as one of the underlying implementations of ordered set keys. If an ordered set contains a large number of elements, or when the member of the element in the ordered set is a relatively long string , Redis will use a jump table as the underlying implementation of the ordered set key.
Here we need to think about a question - why does Redis use a jump table to implement it when there are a large number of elements or the members are relatively long strings?
From the above we can know that the jump list adds a multi-level index to the linked list to improve the efficiency of search, but it is a space-for-time solution, which will inevitably bring about a problem - the index is It takes up memory. The original linked list may store very large objects, but the index node only needs to store key values and a few pointers, and does not need to store objects. Therefore, when the node itself is relatively large or the number of elements is relatively large, its advantage is It will inevitably be magnified, while the shortcomings can be ignored.
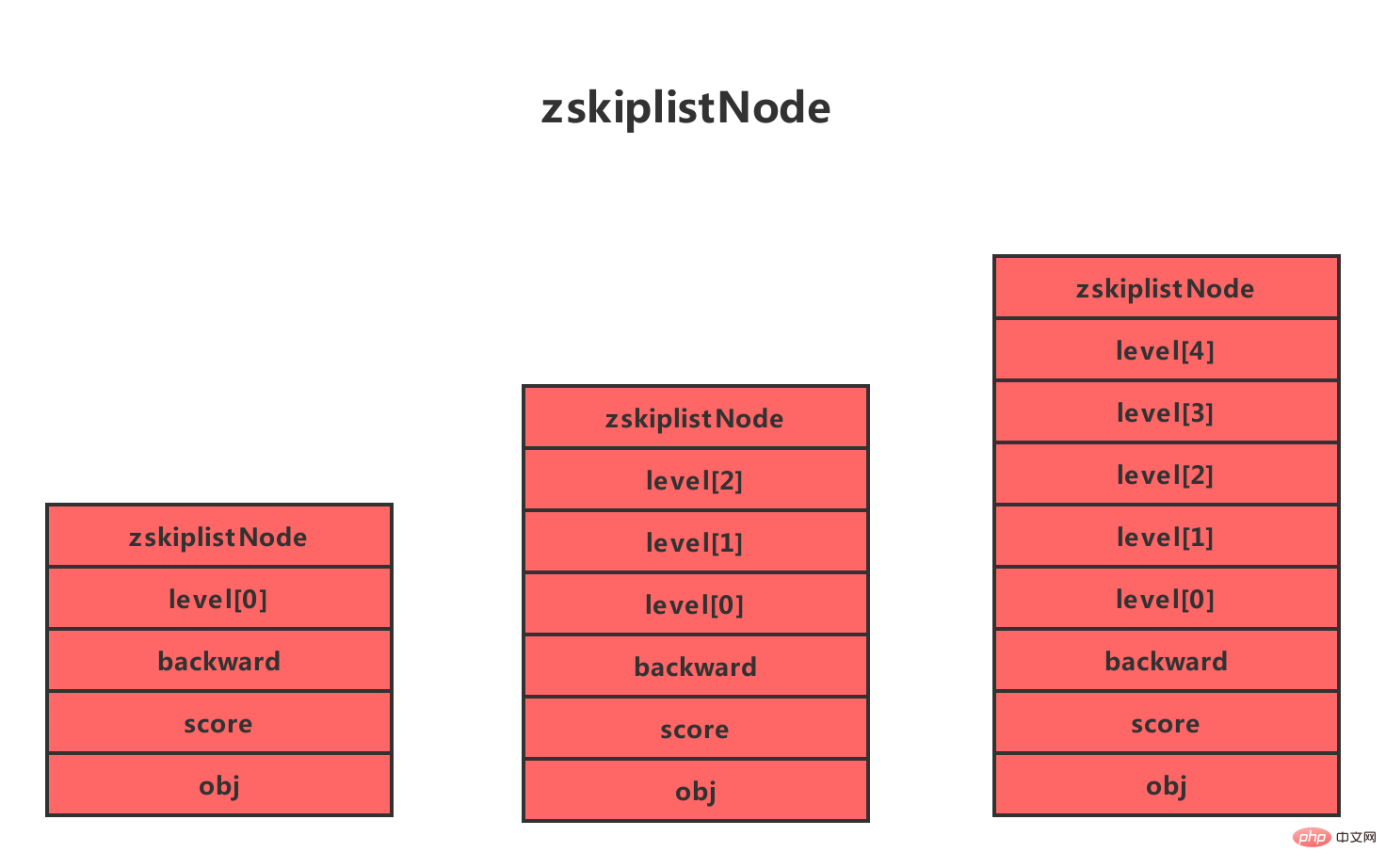
The skip table of Redis is defined by two structures, Detailed explanation of jump table of Redis data structure and skiplist. The Detailed explanation of jump table of Redis data structure structure is used to represent the skip table node, and the zskiplist structure is used to save the jump. Information related to table nodes, such as the number of nodes, pointers to the head node and tail node, etc.
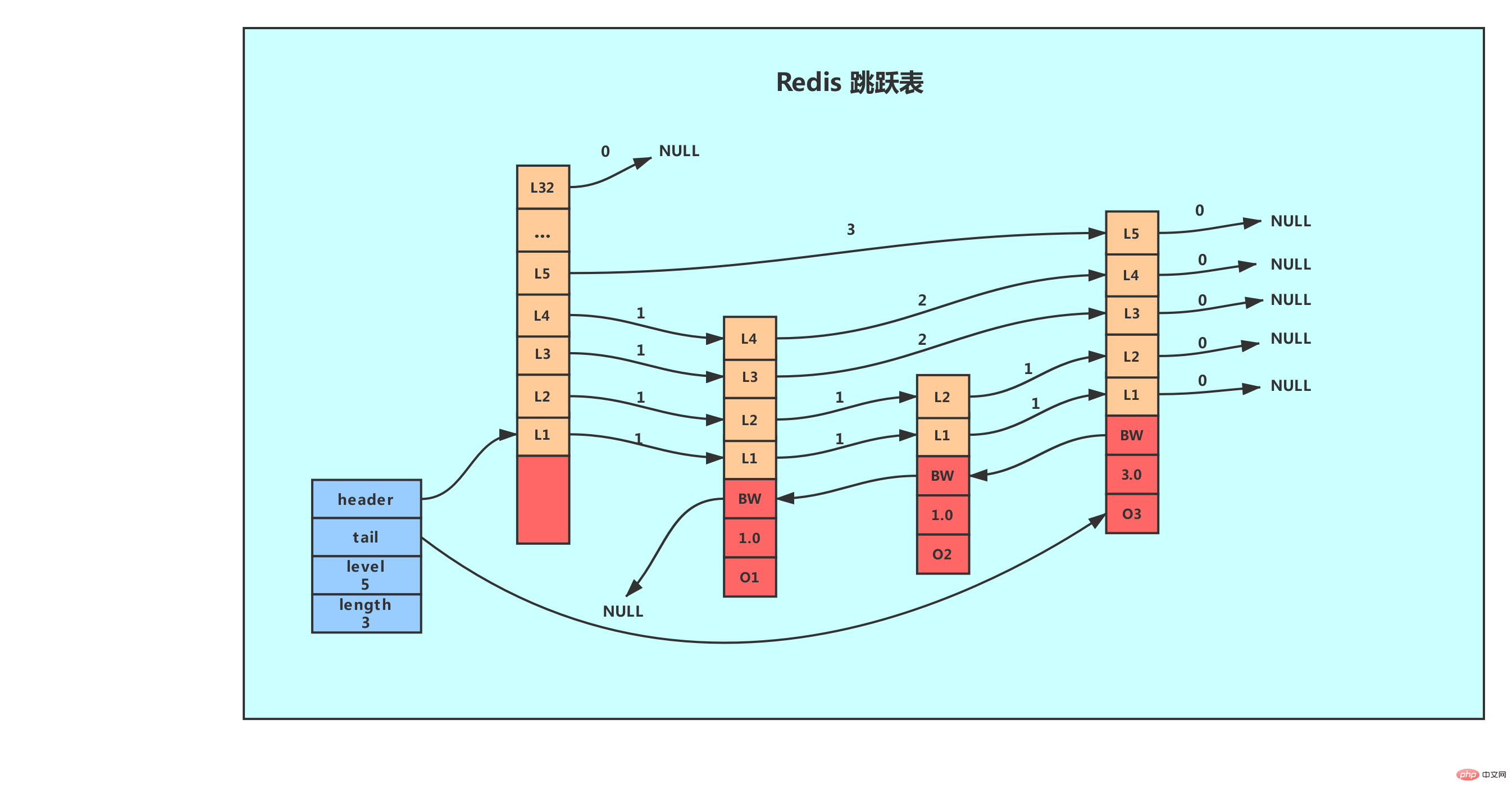
The above figure shows an example of a skip list. The leftmost one is the skiplist structure, which contains the following attributes.
header: points to the header node of the jump table. The time complexity of locating the header node through this pointer program is O(1)
tail: Points to the tail node of the jump table. The time complexity of locating the tail node of the table through this pointer program is O(1)
level: Record the current jump table, The number of layers of the node with the largest number of layers (the number of layers of the header node is not included). Through this attribute, the number of layers of the node with the best layer height can be obtained in O(1) time complexity.
length: Record the length of the jump table, that is, the number of nodes currently contained in the jump table (head nodes are not included). Through this attribute, the program can be O(1) Returns the length of the jump list in time complexity.
On the right side of the structure are four Detailed explanation of jump table of Redis data structure structures, which contain the following attributes
| Time complexity | |
|---|---|
| O(1) | |
| O(N) | |
| Average O (logN), worst case O(logN) (N is the length of the skip list) | |
| The average is O(logN), the worst is O(logN) (N is the length of the jump table) | |
| Average O(logN), worst O(logN) (N is the length of the jump table) | |
| Average O(logN), worst O(logN) (N is the length of the jump list) | |
| O(1) | |
| Average O( logN), worst O(logN) (N is the length of the jump table) | |
| Average O(logN), worst O(logN) (N is the length of the jump list) | |
| O(N), N is the number of nodes to be divided | |
| O(N), N is the number of nodes to be removed. |
The above is the detailed content of Detailed explanation of jump table of Redis data structure. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



