
❝I believe that many friends have already configured master-slave replication, but they do not have an in-depth understanding of the workflow and common problems of redis master-slave replication. Kaka here It took me two days to sort out all the knowledge points about redis master-slave replication.
❞
❝Kaka compiled a road map to create an interview guide, and prepared to write articles according to such a road map. Later, I found that there were no supplements. Knowledge points are being added. We also look forward to your partners helping to add them. See you in the comment area! ❞

But in the actual process, it is impossible to have only two redis servers for master-slave replication, which means that each redis server may be called the master node (master)
The picture below In the case, our slave3 is both the slave node of the master and the master node of the slave.
First understand this concept, and continue to read below for more detailed explanations. 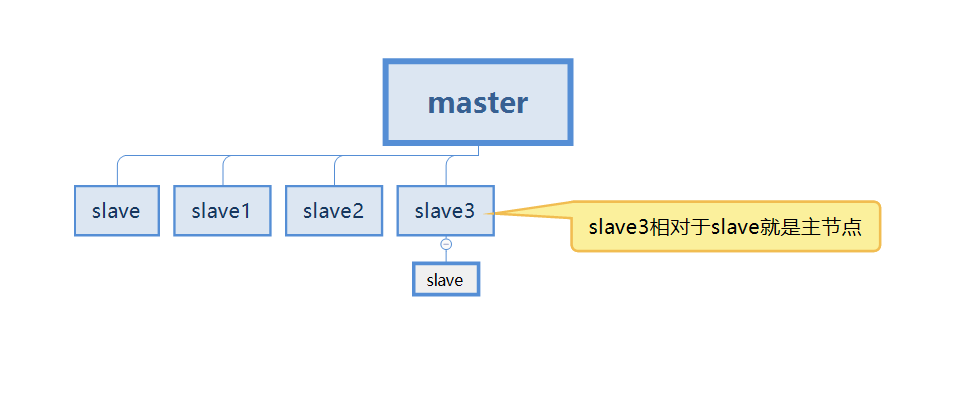
Assume that we have a redis server now, which is a stand-alone state.
The first problem that will arise in this case is server downtime, which directly leads to data loss. If the project is related to RMB, the consequences can be imagined.
The second situation is the memory problem. When there is only one server, the memory will definitely reach the peak. It is impossible to upgrade one server infinitely.  So in response to the above two problems, we will prepare a few more servers and configure master-slave replication. Store data on multiple servers. And ensure that the data of each server is synchronized. Even if a server goes down, it will not affect users' use. Redis can continue to achieve high availability and redundant backup of data.
So in response to the above two problems, we will prepare a few more servers and configure master-slave replication. Store data on multiple servers. And ensure that the data of each server is synchronized. Even if a server goes down, it will not affect users' use. Redis can continue to achieve high availability and redundant backup of data.
There should be many questions at this point. How to connect master and slave? How to synchronize data? What if the master server goes down? Don't worry, solve your problems bit by bit. 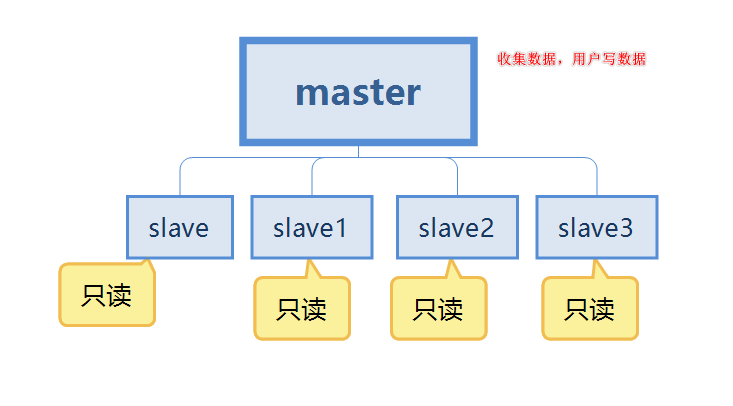
We talked about why we use redis above Master-slave replication, then the role of master-slave replication is to explain why it is used.
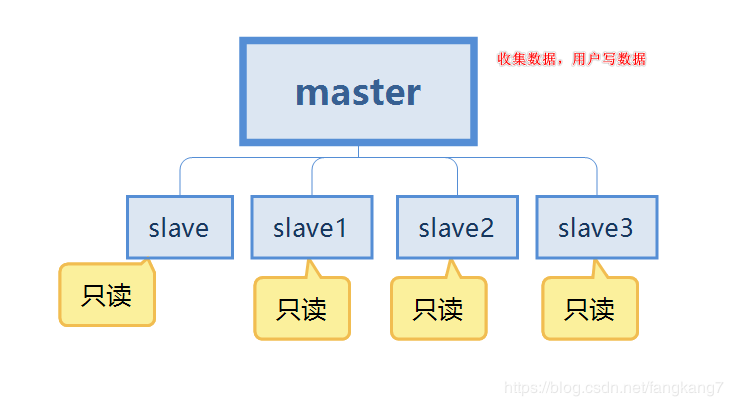
First we configure two configuration files, namely redis6379.conf and redis6380.conf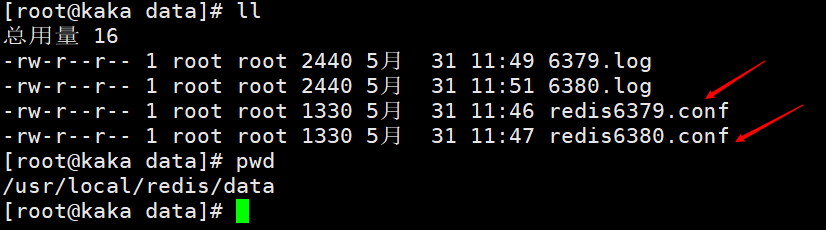 Modify the configuration file, mainly to modify the port. For the convenience of viewing, the names of log files and persistent files are identified with their respective ports.
Modify the configuration file, mainly to modify the port. For the convenience of viewing, the names of log files and persistent files are identified with their respective ports. 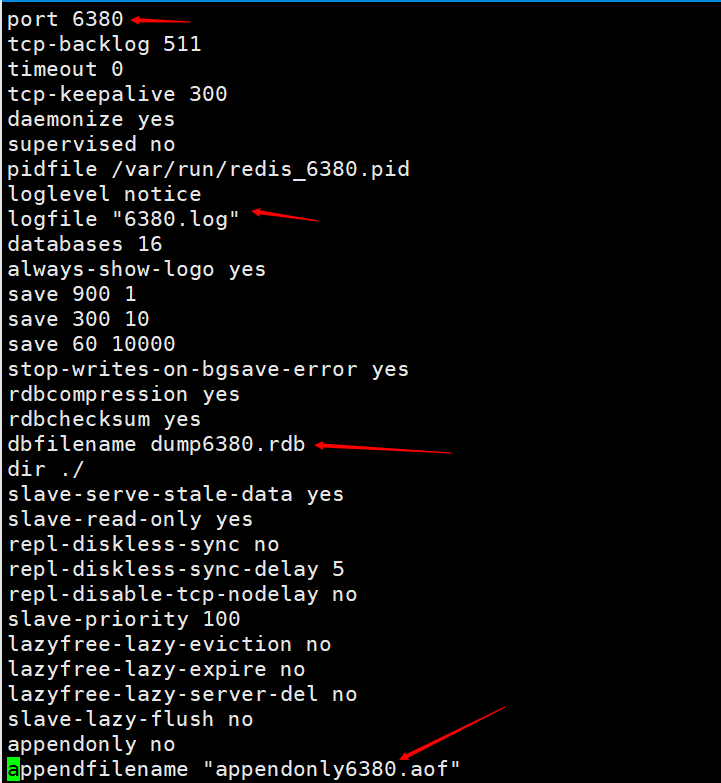 Then open two redis services respectively, one port is 6379 and the other port is 6380. Execute the command
Then open two redis services respectively, one port is 6379 and the other port is 6380. Execute the command redis-server redis6380.conf, and then use redis-cli -p 6380 to connect. Because the default port of redis is 6379, we start another redis server and use it directly redis-server redis6379.conf Then use redis-cli to connect directly.  At this time we have successfully configured two redis services, one is 6380 and the other is 6379. This is just for demonstration. In actual work, it needs to be configured on two different servers.
At this time we have successfully configured two redis services, one is 6380 and the other is 6379. This is just for demonstration. In actual work, it needs to be configured on two different servers.
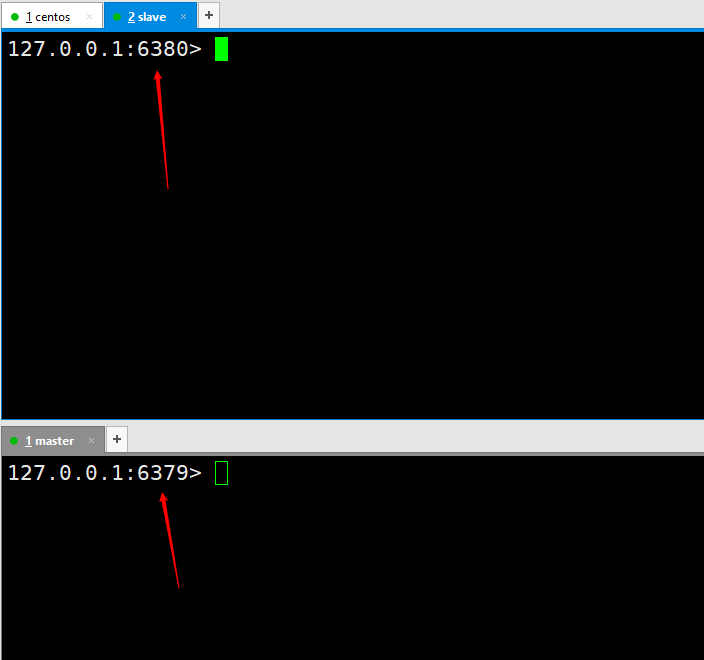
We must first have a concept, that is, when configuring master-slave replication, all operations are performed on the slave node, which is the slave.
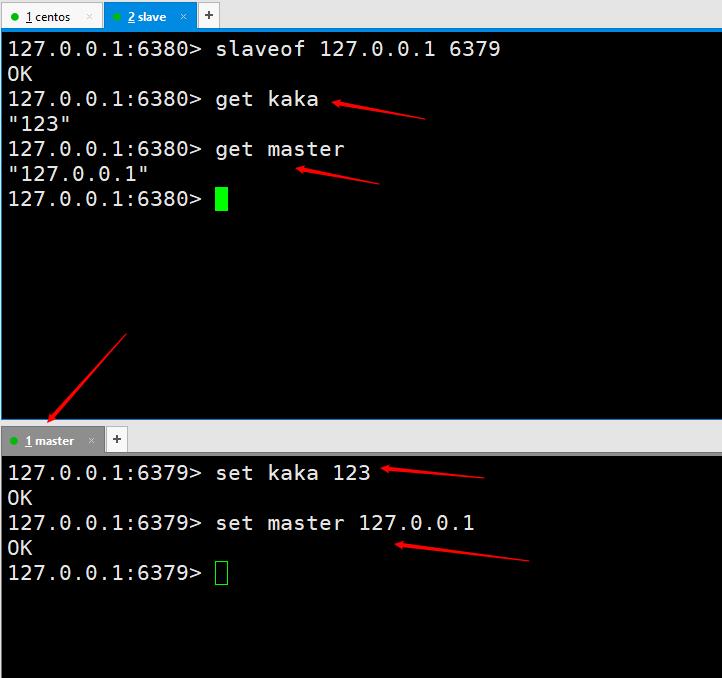
Then we execute a command on the slave node as slaveof 127.0.0.1 6379. After execution, it means we are connected. 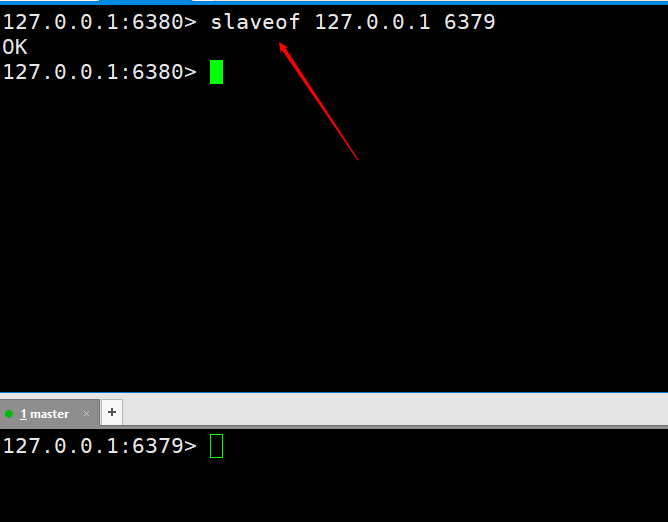 Let’s test first to see if master-slave replication is implemented. Execute two
Let’s test first to see if master-slave replication is implemented. Execute two set kaka 123 and set master 127.0.0.1 on the master server, and then the slave6380 port can be successfully obtained, which means that our master-slave replication has been configured. However, the implementation of the production environment is not the end of the world. Later, the master-slave replication will be further optimized until high availability is achieved.
Before using the configuration file to start master-slave replication! First, you need to disconnect the previous connection using the client command line, and execute slaveof no one on the slave host to disconnect the master-slave replication. 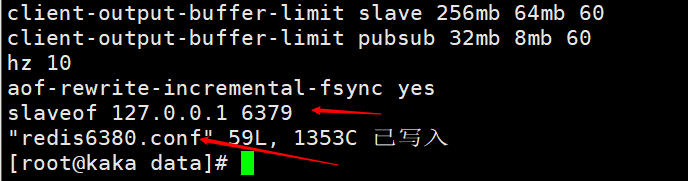 Where can I check that the slave node has disconnected from the master node? Enter the command line
Where can I check that the slave node has disconnected from the master node? Enter the command line info on the client of the master node to view
This picture is the information printed by entering info on the client of the master node after using the slave node to connect to the master node using the client command line. You can see that there is a piece of information about slave0. 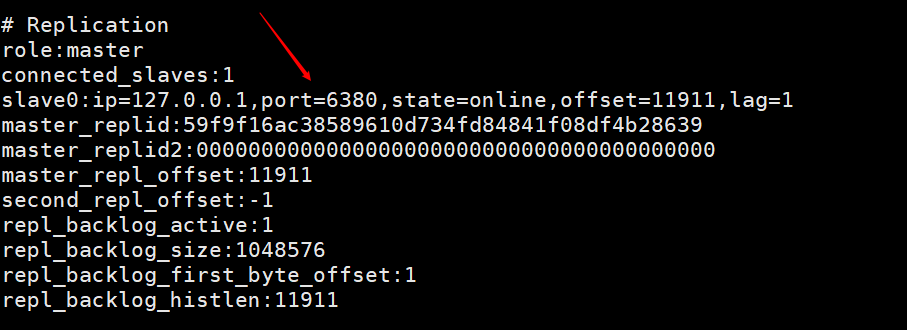 This picture is
This picture is info printed on the master node after the slave node executes slaveof no one, indicating that the slave node has disconnected from the master node. 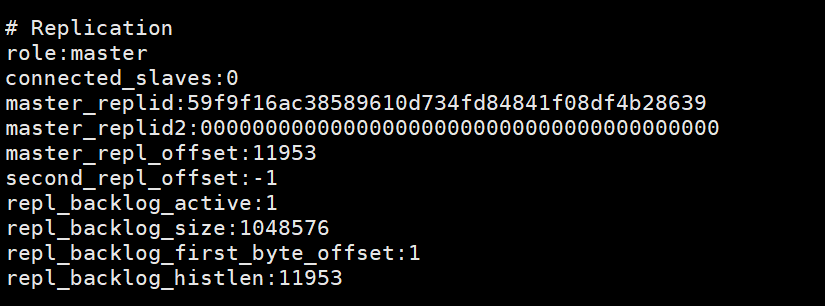 Start the redis service according to the configuration file,
Start the redis service according to the configuration file, redis-server redis6380.conf
After the slave node is restarted, you can directly view the connection information of the slave node on the master node. 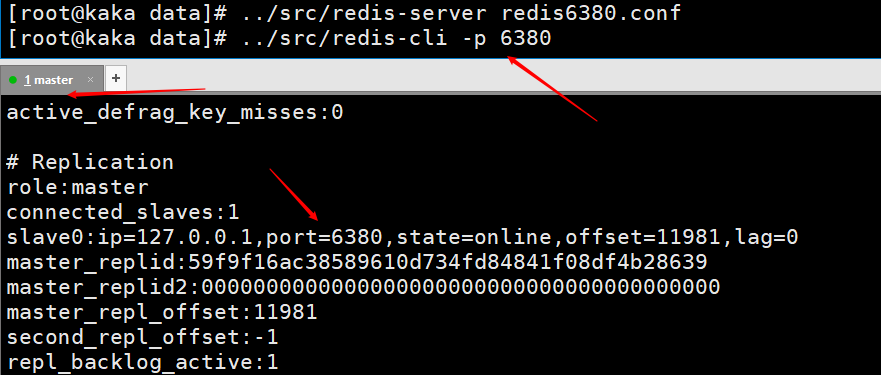 Test data, what is written by the master node, will still be automatically synchronized by the slave node.
Test data, what is written by the master node, will still be automatically synchronized by the slave node. 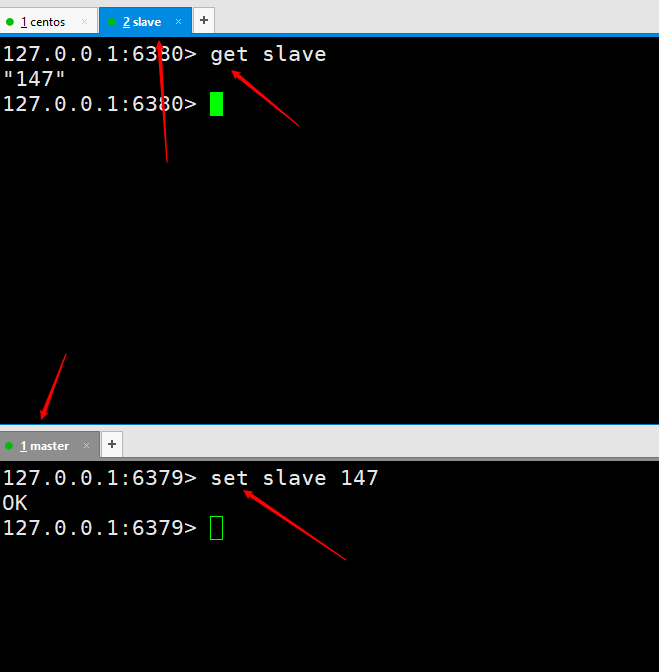
This configuration is also very simple. When using the redis server, start master-slave replication directly and execute the command: redis-server --slaveof host port.
This is the log information of the master node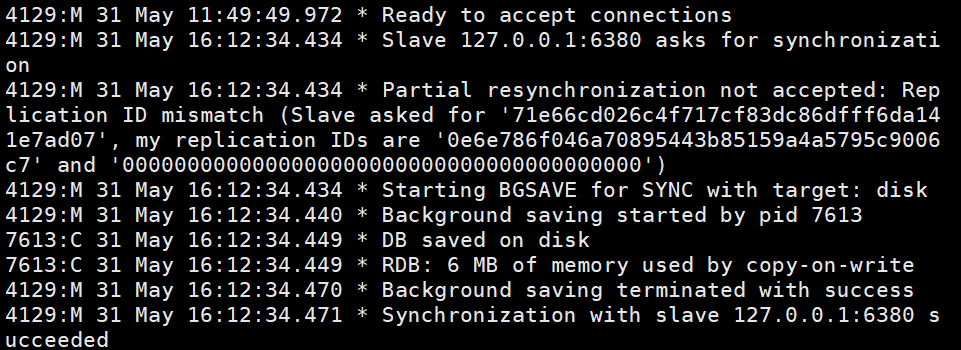 This is The information of the slave node, including the connection information of the master node, and RDB snapshot saving.
This is The information of the slave node, including the connection information of the master node, and RDB snapshot saving. 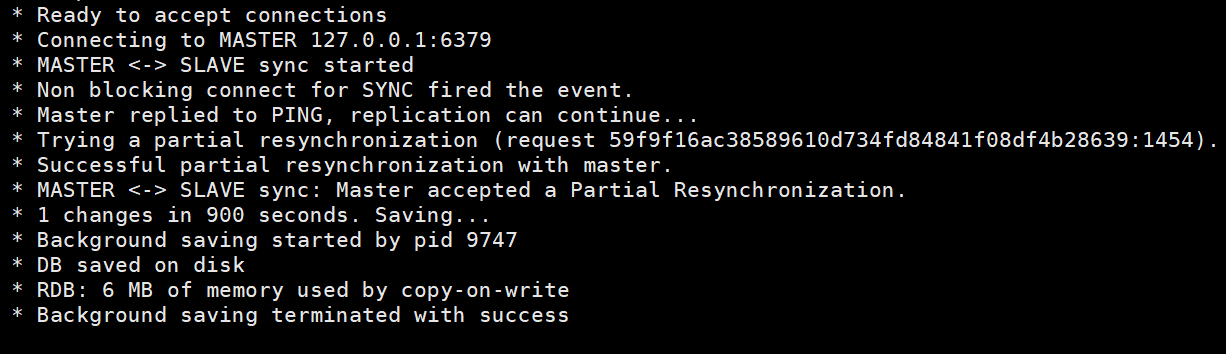
The complete workflow of master-slave replication is divided into the following three stages. Each segment has its own internal workflow, so we will talk about these three processes.
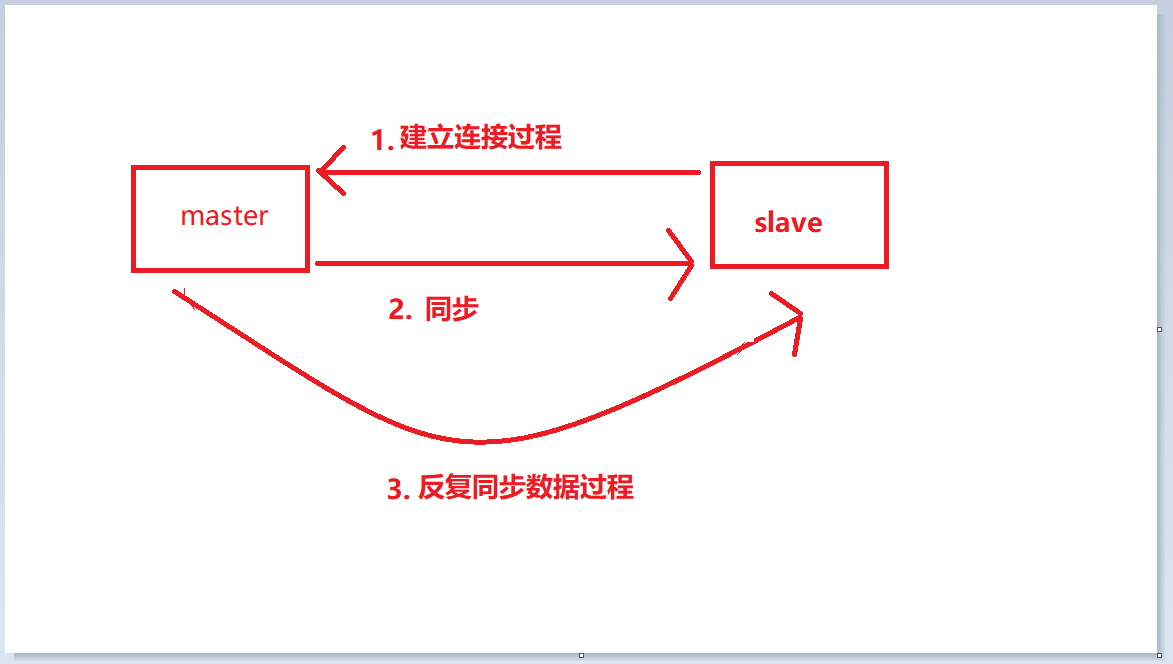
The above picture is a complete master-slave replication connection establishment workflow. Then use short words to describe the above workflow. 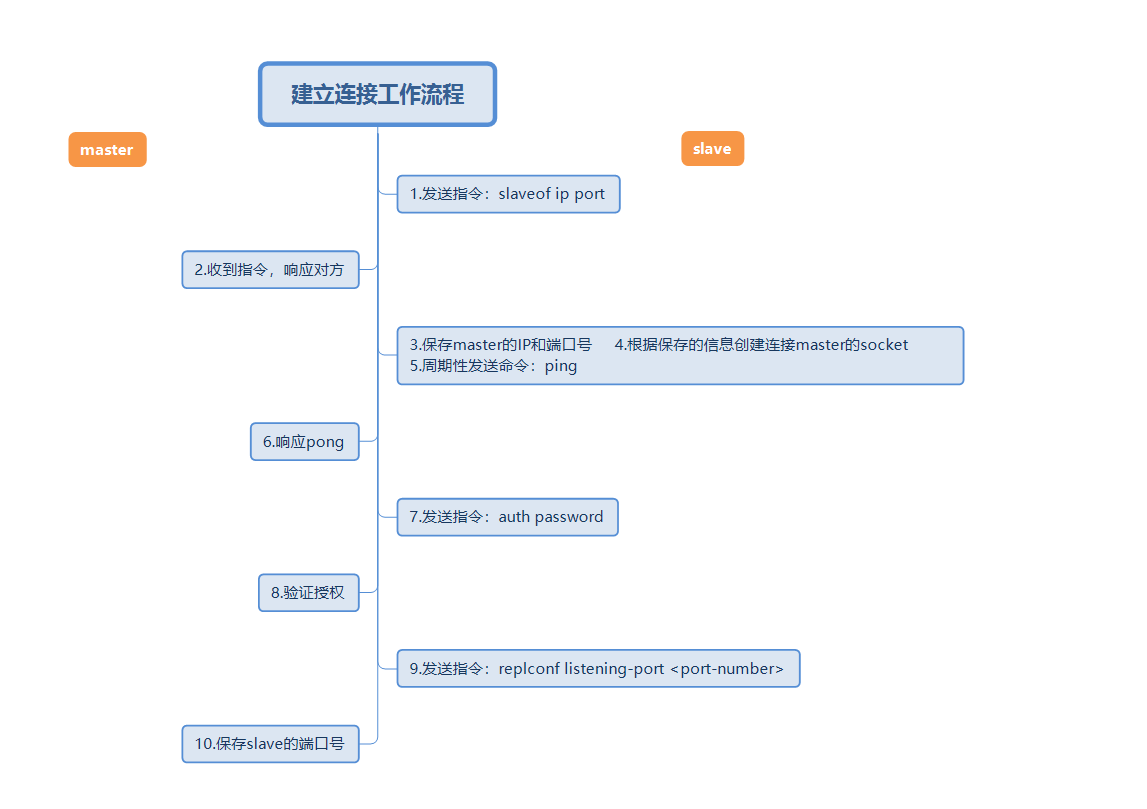
This picture is a detailed description of the first The data synchronization process when a slave node connects to the master node. 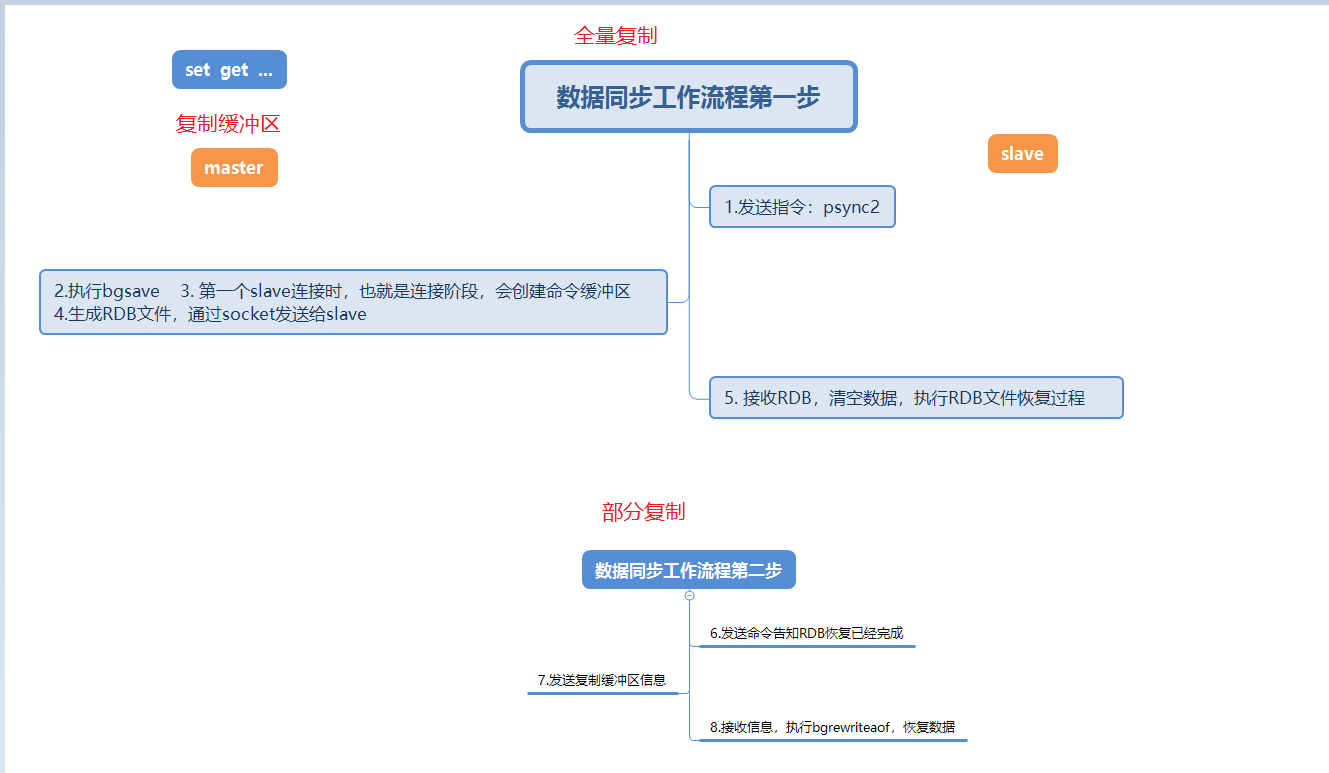
When the slave node connects to the master node for the first time, it will first perform a full copy. This full copy is unavoidable.
After the full replication is completed, the master node will send the data in the replication backlog buffer, and then the slave node will execute bgrewriteaof to restore the data, which is also partial replication.
Three new points are mentioned at this stage, full copy, partial copy, and copy buffer backlog area. These points will be explained in detail in the FAQ below.
When the master database is modified, the master and slave servers After the data is inconsistent, the master-slave data will be synchronized to be consistent. This process is called command propagation.
The master will send the received data change command to the slave, and the slave will execute the command after receiving the command to make the master-slave data consistent.
「Partial replication in the command propagation phase」
During the command propagation phase, the network is disconnected or the network jitters. Causes the connection to be disconnected (connection lost)
At this time, the master node master will continue to write data to the replbackbuffer (replication buffer backlog area)
The slave node will continue to try to connect to the master
When the slave node puts its runid and The replication offset is sent to the master node, and the pysnc command is executed to synchronize
If the master determines that the offset is within the replication buffer range, it will return continue Order. And send the data in the copy buffer to the slave node.
Receive data from the node and execute bgrewriteaof to restore the data
This process is the most complete process explanation of master-slave replication. So let’s briefly introduce each step of the process
psync ? 1 psync runid offset Find the corresponding runid to request data. But here you can consider that when the slave node connects for the first time, it does not know the runid and offset of the master node at all. So the first command sent is psync? 1 means that I want all the data of the master node. psync runid offset2 to continue performing full replication. The runid mismatch here may only be caused by restarting the slave node. This problem will be solved later. The offset (offset) mismatch is caused by the replication backlog buffer overflow. If the runid or offset check passes, if the offset of the slave node is the same as the offset of the master node, it will be ignored. If the runid or offset check passes and the offset of the slave node is different from the offset, CONTINUE offset (this offset belongs to the master node) will be sent, and the data from the slave node offset to the master node offset in the replication buffer will be sent through the socket. 「1-4 are full copies, 5-8 are partial copies」
Under step 3 of the master node, the master node has been receiving client data during the master-slave replication period, and the offset of the master node has been changing. Only changes will be sent to each slave. This sending process is called the heartbeat mechanism
In the command propagation stage, information exchange between the master node and the slave node is always required, and the heartbeat mechanism is used for maintenance to keep the connection between the master node and the slave node online.
master heartbeat
slave heartbeat task
"Precautions during the heartbeat phase"In order to ensure data stability, the master node will wait until the number of slave nodes hangs or When latency is too high. All information synchronization will be refused.
There are two parameters for configuration adjustment:
min-slaves-to-write 2
min-slaves-max-lag 8
These two parameters indicate that there are only 2 slave nodes left, or when the delay of the slave node is greater than 8 seconds, the master node will forcibly turn off the master function and stop data synchronization.
So how does the master node know the number and delay time of slave nodes hanging up? In the heartbeat mechanism, the slave will send the perlconf ack command every second. This command can carry the offset, the delay time of the slave node, and the number of slave nodes.
# Let's first take a look at what this run id is. You can see it by executing the info command. We can also see this when we look at the startup log information above.
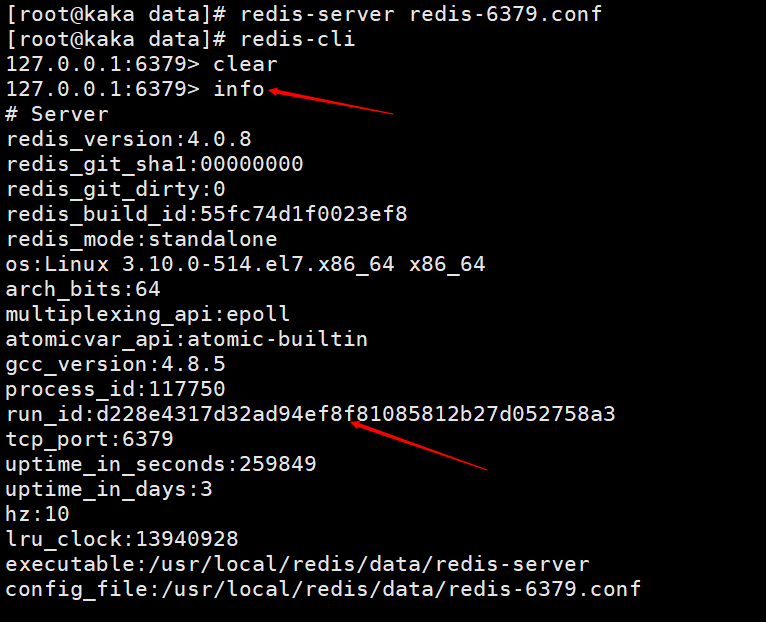 Redis will automatically generate a random ID when it is started (it should be noted here that the ID will be different every time it is started), which is composed of 40 random hexadecimal strings. Used to uniquely identify a redis node.
Redis will automatically generate a random ID when it is started (it should be noted here that the ID will be different every time it is started), which is composed of 40 random hexadecimal strings. Used to uniquely identify a redis node.
When the master-slave replication is first started, the master will send its runid to the slave, and the slave will save the master's ID. We can use the info command to view it

When the connection is disconnected and reconnected, the slave sends this ID to the master. If the runid saved by the slave is the same as the current runid of the master, the master will try Use partial copy (another factor in whether this block can be copied successfully is the offset). If the runid saved by the slave is different from the current runid of the master, full copy will be performed directly.
#The copy buffer backlog is a first-in-first-out queue where the user stores data collected by the master command record. The default storage space of the copy buffer is 1M.
You can modify repl-backlog-size 1mb in the configuration file to control the buffer size. This ratio can be modified according to your own server memory. Kaka has reserved 30 %about.
"What exactly is stored in the copy buffer?"
When executing a command as set name kaka, we can view the persistence File View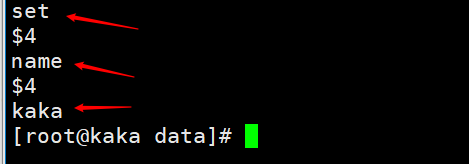 Then the copy backlog buffer is the stored aof persistent data, separated by bytes, and each byte has its own offset. This offset is also the copy offset (offset)
Then the copy backlog buffer is the stored aof persistent data, separated by bytes, and each byte has its own offset. This offset is also the copy offset (offset) "Then why is it said that the copy buffer backlog may cause full copy?"
"Then why is it said that the copy buffer backlog may cause full copy?"
In the command propagation stage, The master node will store the collected data in the replication buffer and then send it to the slave node. This is where the problem arises. When the amount of data on the master node is extremely large in an instant, and exceeds the memory of the replication buffer, some data will be squeezed out, resulting in data inconsistency between the master node and the slave node. To make a full copy. If the buffer size is set unreasonably, it may cause an infinite loop. The slave node will always copy in full, clear the data, and copy in full.
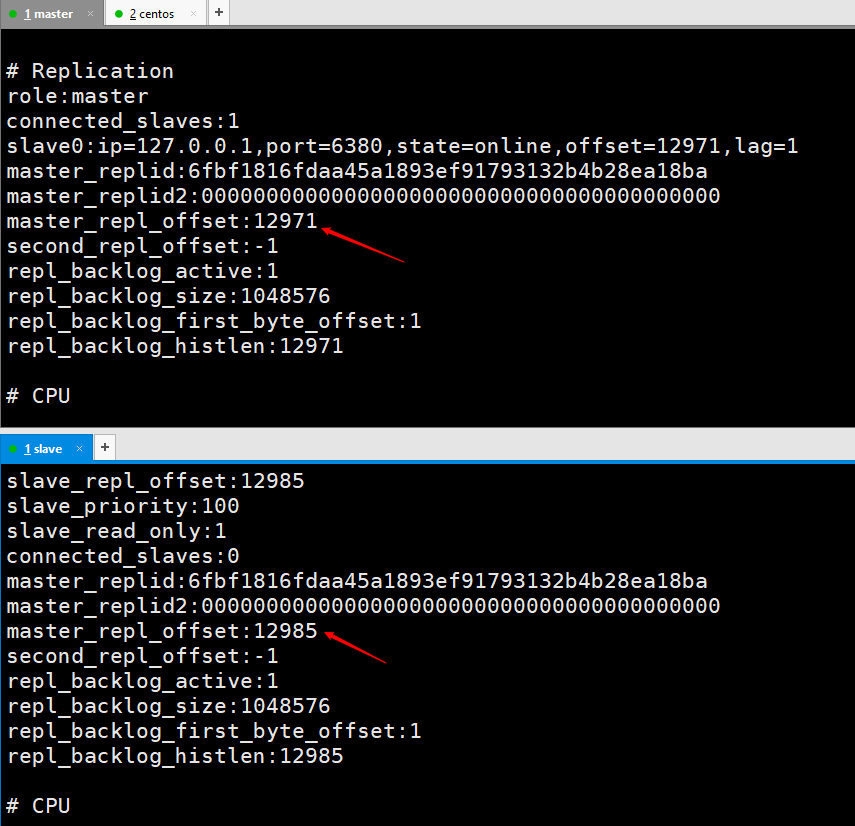 The master node replication offset is sent to the slave node Record once, and the slave node receives record once.
The master node replication offset is sent to the slave node Record once, and the slave node receives record once.
is used to synchronize information, compare the differences between the master node and the slave node, and restore data usage when the slave is disconnected.
This value is the offset from the copy buffer backlog.
When the master node restarts, the value of runid will change, which will cause all slave nodes to perform full replication.
We don’t need to consider this issue, we just need to know how the system is optimized.
After the master-slave replication is established, the master node will create the master-replid variable. The generated strategy is the same as the runid, the length is 41 bits, and the runid length is 40 bits, and then sent to the slave node.
When the shutdown save command is executed on the master node, an RDB persistence will be performed and the runid and offset will be saved to the RDB file. You can use the command redis-check-rdb to view this information.
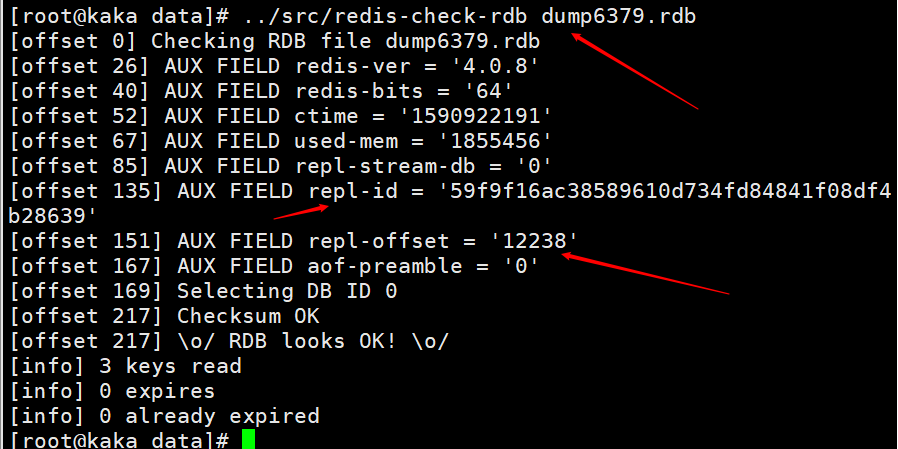 Load the RDB file after the master node restarts, and load the repl-id and repl-offset in the file into the memory. Even if all slave nodes are considered to be the previous master nodes.
Load the RDB file after the master node restarts, and load the repl-id and repl-offset in the file into the memory. Even if all slave nodes are considered to be the previous master nodes.
Due to poor network environment, the slave node network is interrupted . The replication backlog buffer memory is too small, causing data overflow. Along with the slave node offset crossing the boundary, full replication occurs. This may result in repeated full copies.
Solution: Modify the size of the replication backlog buffer: repl-backlog-size
Setting suggestions: Test the time for the master node to connect to the slave node, and obtain the average total number of commands generated by the master node per second. Amount write_size_per_second
Copy buffer space setting = 2 * Master-slave connection time * Total amount of data generated by the master node per second
#Because the CPU usage of the master node is too high, or the slave node is frequently connected. The result of this situation is that various resources of the master node are seriously occupied, including but not limited to buffers, bandwidth, connections, etc.
Why are the master node resources seriously occupied?
In the heartbeat mechanism, the slave node will send a command replconf ack command to the master node every second. A slow query was executed on the slave node, occupying a large amount of CPU. The master node calls the replication timing function replicationCron every second, and then the slave node does not respond for a long time.
Solution:
Set slave node timeout release
Set parameter: repl-timeout
This parameter defaults to 60 seconds. After 60 seconds, release the slave.
Due to network factors, the data of multiple slave nodes will be inconsistent. There is no way to avoid this factor.
There are two solutions to this problem:
The first data needs to be highly consistent and configure a redis server, and use one server for both reading and writing. This method is limited to a small amount of data. , and the data needs to be highly consistent.
The second monitors the offset of the master-slave node. If the delay of the slave node is too large, the client's access to the slave node is temporarily blocked. Set the parameter to slave-serve-stale-data yes|no. Once this parameter is set, it can only respond to a few commands such as info slaveof.
#This problem directly maintains a list of available nodes on the client. When the slave node In the event of a failure, switch to other nodes for work. This issue will be discussed later in the cluster.
This article mainly explains what is master-slave replication and the three major aspects of master-slave replication. Stages, workflows, and the three core components of partial replication. Heartbeat mechanism during the command propagation phase. Finally, common problems with master-slave replication are explained.
It took two days to write this article. This is also the longest article that Kaka has recently written. I estimate that all articles published by Kaka in the future will be like this. I will not publish multiple articles on one issue separately. I will explain it in an article, and I will explain it all in one article. Incomplete knowledge points or wrong knowledge points will be improved as Kaka's knowledge points increase. The article is mainly for the convenience of Kaka review. If you have any questions, see the comment section.
Kaka hopes that everyone can communicate and learn together. If something is wrong, you can point it out. If you don’t like it, don’t criticize it.
❝Persistence in learning, persistence in blogging, and persistence in sharing are the beliefs that Kaka has always upheld since his career. I hope that Kaka’s articles on the huge Internet can bring you a little bit of help. See you next time.
❞
Recommended: "redis tutorial"
The above is the detailed content of Redis master-slave replication principle and common problems. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis












![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



