

DataFrame using pandas for data processing


Relevant learning recommendations: python tutorial
pandas data processing topic's second article, let's talk about the most important data structure in pandas - DataFrame.
In the previous article, we introduced the usage of Series, and also mentioned that Series is equivalent to a one-dimensional array, but pandas encapsulates many convenient and easy-to-use APIs for us. The DataFrame can be simply understood as a dictcomposed of Series, thus splicing the data into a two-dimensional table. It also provides us with many interfaces for table-level data processing and batch data processing, which greatly reduces the difficulty of data processing.
Create DataFrame
DataFrame is a tabular data structure, which has two indexes, namelyRow index and column index allow us to easily obtain the corresponding rows and columns. This greatly reduces the difficulty of finding data for data processing.
First, let’s start with the simplest one, how to create a DataFrame.Create from dictionary
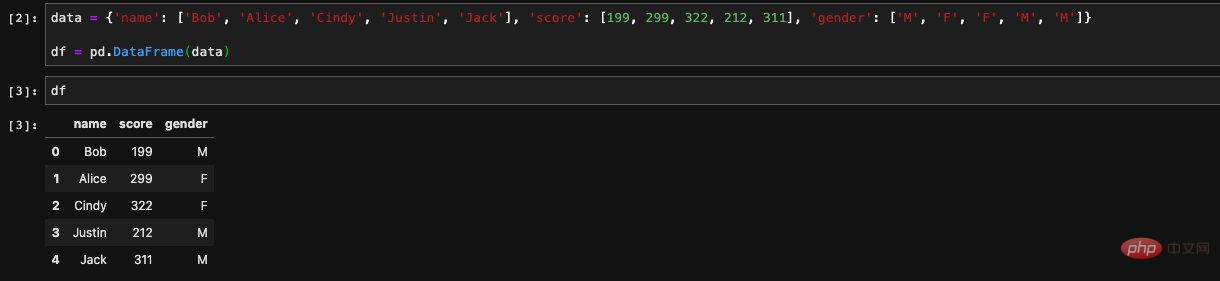
create a DataFrame for us with key as the column name and value as the corresponding value. When we output in jupyter, it will automatically display the contents of the DataFrame in table form for us.
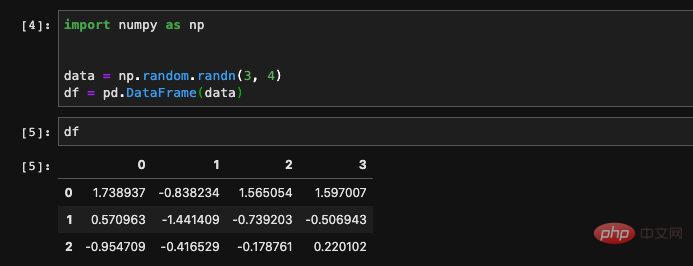
We can also create a DataFrame from a numpy two-dimensional array, if If we just pass in the numpy array without specifying the column name, then pandas
will use the number as the index to create the columnfor us:
 We are in When creating, pass in a list of strings for the columns field to specify a column name for it:
We are in When creating, pass in a list of strings for the columns field to specify a column name for it: 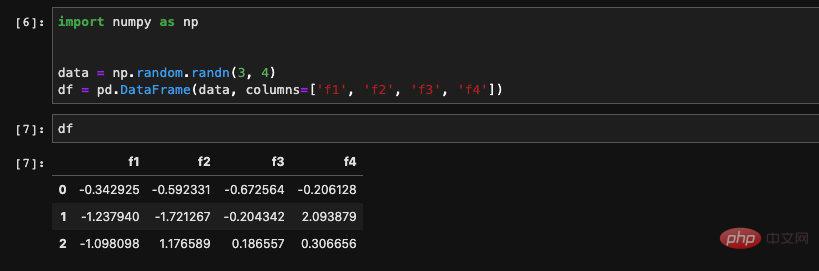
Reading from a file
Another very powerful function of pandas is that it canRead data from files in various formats to create DataFrame, such as commonly used excel, csv, or even databases.
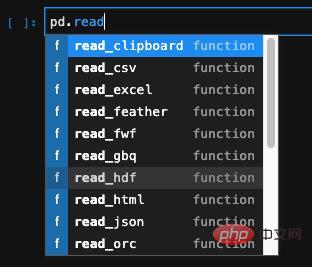
For structured data such as excel, csv, json, etc., pandas provides a special API. We can find the corresponding API and use it:
If it is in some special format, it doesn't matter. We use read_table, which can read data from various text files and complete the creation by passing in the separator and other parameters. For example, in the previous article verifying the dimensionality reduction effect of PCA, we read data from a .data format file. The delimiter between columns in this file is a space, not the comma or table character of csv. We pass in the sep parameter through and specify the delimiter to complete the data reading.

This header parameter indicates which lines of the file are used as column names of the data. The default header=0 means that the first line is used as the column name. . If the column name does not exist in the data, header=None needs to be specified, otherwise problems will occur. We rarely need to use multi-level column names, so generally the most commonly used method is to take the default value or set it equal to None.
Among all these methods to create a DataFrame, the most commonly used is the last one , reading from a file. Because when we do machine learning or participate in some competitions in Kaggle, the data is often ready-made and given to us in the form of files. There are very few cases where we need to create data ourselves. If it is in an actual work scenario, although the data will not be stored in files, there will be a source, usually stored in some big data platforms, and the model will obtain training data from these platforms.
So in general, we rarely use other methods of creating DataFrame. We have some understanding and focus on mastering the method of reading from files.
Common operations
#The following introduces some common operations of pandas. These operations were performed before I learned how to use pandas systematically. Already understood. The reason for understanding it is also very simple, because they are too commonly used, and they can be said to be common sense content that must be known.
View data
When we run the DataFrame instance in jupyter, all the data in the DataFrame will be printed for us. , if there are too many rows of data, the middle part will be omitted in the form of ellipses. For a DataFrame with a large amount of data, we generally do not directly output and display it like this, but choose to display the first few or last few pieces of data. Two APIs are needed here.
The method for displaying the first several pieces of data is called head. It accepts a parameter and allows us to specify it to display the number of data we specify from the beginning.
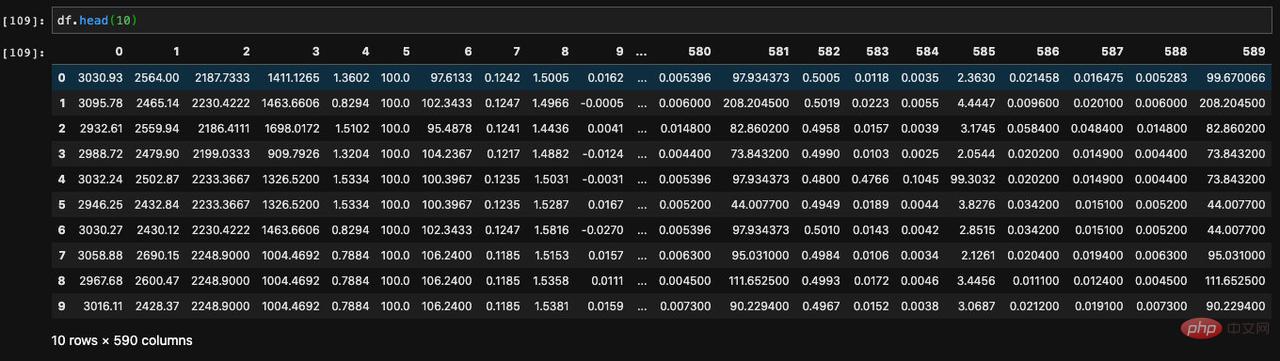
Since there is an API for displaying the first few items, there is also an API for displaying the last few items. Such an API is called tail. Through it, we can view the last specified number of data in the DataFrame:

Add, delete and modify columns
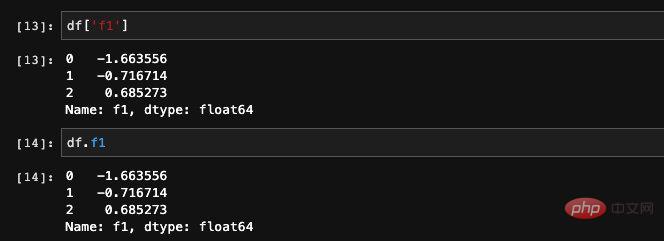
We mentioned before that for DataFrame, it is actually equivalent to a dict composed of Series. Since it is a dict, we can naturally obtain the specified Series based on the key value.
There are two ways to get the specified column in DataFrame. We can add column names or find elements through dict to query:
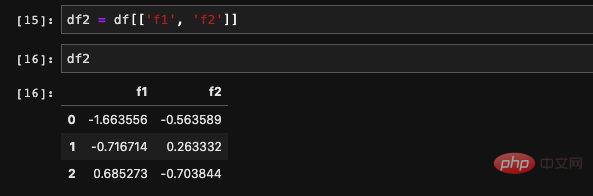
We can also can read multiple columns at the same time. If there are multiple columns, only one method is supported, which is to query elements through dict. It allows receiving an incoming list and finding the data corresponding to the columns in the list. The result returned is a new DataFrame composed of these new columns.
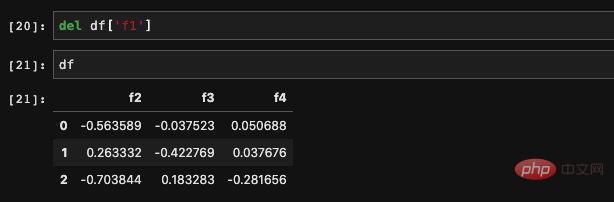
We canuse del to delete a column we don’t need:
We want to create a new The columns are also very simple. We can directly assign values to the DataFrame just like dict assignment:
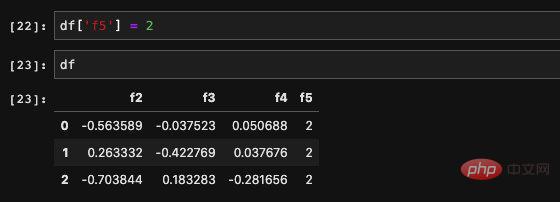
The assigned object cannot only be Real numbers, can also be an array:
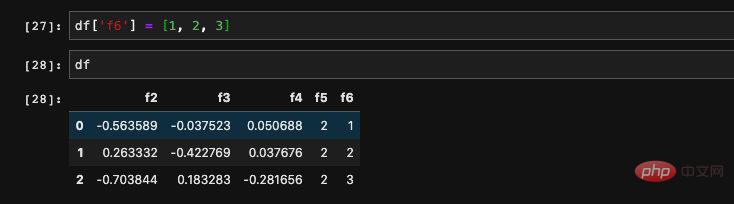
It is very simple to modify a certain column. We can also overwrite the original data through the same method of assignment.
Convert to numpy array
#Sometimes it is inconvenient for us to use pandas and want to obtain its corresponding original data , you can directly use .values to obtain the numpy array corresponding to DataFrame:

Since each column in the DataFrame has a separate type , After being converted into a numpy array, all data share the same type. Then pandas will find a common type for all columns, which is why you often get an object type. Therefore, it is best to check the type before using .values to ensure that there will be no errors due to the type.
Summary
In today’s article we learned about the relationship between DataFrame and Series, and also learned some DataFrame The basics and common usage. Although DataFrame can be approximately regarded as a dict composed of Series, in fact, as a separate data structure, it also has many own APIs, supports many fancy operations, and is a powerful tool for us to process data.
Professional organizations have made statistics. For an algorithm engineer, about 70% of the time will be invested in data processing. The time spent actually writing the model and adjusting parameters may be less than 20%. From this we can see the necessity and importance of data processing. In the field of Python, pandas is the best scalpel and toolbox for data processing. I hope everyone can master it.
If you want to learn more about programming, please pay attention to the php training column!
The above is the detailed content of DataFrame using pandas for data processing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
36
110
52
36
110

 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
