
 Database
Mysql Tutorial
The most complete database MVCC in the entire network, I am responsible for any incomplete explanation.
Database
Mysql Tutorial
The most complete database MVCC in the entire network, I am responsible for any incomplete explanation.
The most complete database MVCC in the entire network, I am responsible for any incomplete explanation.

Related learning recommendations: mysql tutorial
What is MVCC
The full name is Multi-Version Concurrency Control, which is Multi-version concurrency control, mainly to improve the concurrency performance of the database. The following articles are all about the InnoDB engine, because myIsam does not support transactions.
When a read or write request occurs for the same row of data, it will be locked and blocked. But mvcc uses a better way to handle read-write requests, so that no locking is required when a read-write request conflict occurs. This read refers to
, not current read. The current read is a locking operation, which is pessimistic lock. Then how does it achieve read-write
? What the hell are snapshot read and current read? Follow Your considerate brother, continue reading.

What are current reads and snapshot reads under MySQL InnoDB?
Current reading
The database records it reads are all
currently the latest version, and the currently read data will be Lock to prevent other transactions from modifying data. It is an operation of pessimistic lock. The following operations are all current reads:
- select lock in share mode (shared lock)
- select for update ( exclusive lock)
- update (exclusive lock)
- insert (exclusive lock)
- delete (Exclusive lock)
- Serialized transaction isolation level
- Snapshot read
The implementation of snapshot read is based on
Multi-versionConcurrency control, that is, MVCC, since it is multi-version, the data read by the snapshot is not necessarily the latest data, it may be the data of the previous historical version. The following operations are snapshot reads:
- Snapshot reads and mvcc The relationship
is an abstract concept of "maintaining multiple versions of a data so that read and write operations do not conflict". This concept requires specific functions to be implemented, and this specific implementation is
. (The specific implementation will be discussed below) After listening to the
’s explanation, did the toilet suddenly open?

- ##Read-Read
- : There is no problem , and no need for concurrency control
- : There are thread safety issues, which may cause transaction isolation problems, and dirty reads and phantom reads may be encountered. Non-repeatable read
- : There is a thread safety problem, there may be update loss problems, such as the first type of update loss, the second type of update loss
What concurrency problems does MVCC solve?
one-way growth
timestamps to transactions. A version is saved for each data modification, with the version associated with the transaction timestamp . Read operation only reads
database snapshot before the start of this transaction. The problem is solved as follows:
Concurrent read-write time
- : The read operation can be achieved without blocking the write operation. At the same time, write operations will not block read operations.
-
dirty readsSolve, - phantom reads
,
So there are the followingnon-repeatable readsand other transaction isolation problems, but cannot solve the aboveWrite-write update lostproblem. combination punch
- : MVCC resolves read-write conflicts, pessimistic lock resolves write-write conflicts
-
MVCC Optimistic Lock : MVCC resolves read-write conflicts, optimistic lock resolves Write-write conflict The implementation principle of MVCC Its implementation principle is mainly
,
undo log,Read View To achieve Version chainEach row of data in our database, in addition to the data we can see with the naked eye, there are several
, you have to open your
eyes of heaven to see it. They are db_trx_id, db_roll_pointer, db_row_id respectively. db_trx_id
6byte, latest modification (modification/insertion)Transaction ID: RecordCreationThis record/Last modificationTransaction ID of this record .
db_roll_pointer (version chain key)
7byte, rollback pointer, points to of this record Previous version (stored in rollback segment)
auto-increment ID (hidden primary key) , if the data table does not have a primary key , InnoDB will automatically generate a clustered index based on db_row_id.
delete flaghidden field. The fact that the record is updated or deleted does not mean it is really deleted. , butdelete flagchanged

It is the unique implicit primary key generated by the database by default for this row of records, db_trx_id is the transaction ID of the current operation on this record, and db_roll_pointer It is a rollback pointer, used to cooperate with the undo log, pointing to the previous old version. Every time a database record is modified, an
will be recorded. Each undo log also has a roll_pointer attribute (the undo log corresponding to the INSERT operation does not This attribute, because the record does not have an earlier version), these undo logs can be connected and into a linked list, so the current situation is like the picture below:
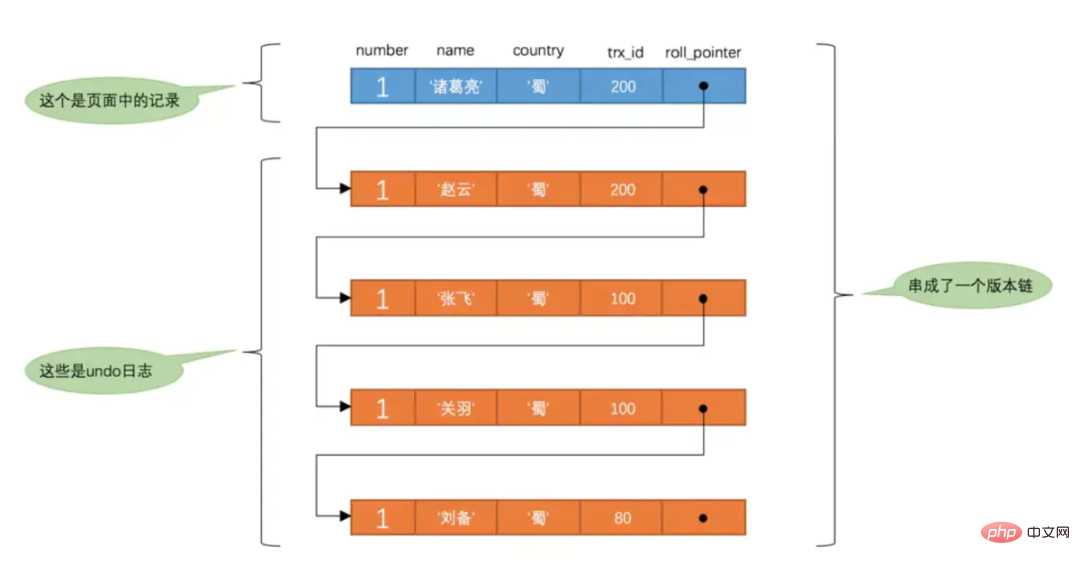
by the roll_pointer attribute. We call this linked list version chain, the head of the version chain. The node is the latest value of the current record. In addition, each version also contains the corresponding transaction id when the version was generated. This information is very important and will be used when judging the visibility of the version based on ReadView. undo log
Undo log is mainly used to
record the log before the data is modified. Before the table information is modified, the data will be copied to undo log. When
is rolled back you can data restore through the log in the undo log.
- Ensure
- transactions
are
atomic when performingrollbackPerformance and consistency, when the transaction isrolled back, the undo log data can be used torecover. Used for MVCC - snapshot reading
data, in MVCC multi-version control, by reading the
historical version ofundo logDatacan realize thatdifferent transaction version numbershave their ownindependent snapshot data versions.
- insert undo log
-
represents the transaction in The undo log generated when inserting new records is only needed when the transaction is rolled back, and can be discarded immediately after the transaction is committed.
update undo log (main) -
The undo log generated when a transaction is updated or deleted; it is not only needed when a transaction is rolled back, but also when a snapshot is read;
So it cannot be deleted casually, and it is only used when fast reading or transaction rollback does not involve this log When, the corresponding log will be uniformly cleared by the purge thread
Read View (read view)
Produced when the transaction performs a
snapshot read operation The Read View (Read View), at the moment when the transaction execution snapshot reads, a snapshot of the current database system will be generated. Record and maintain the system's current
(Without commit, when each transaction is started, it will be assigned an ID. This ID is increasing, so the newer the transaction, The larger the ID value), the list of other transaction IDs in the system that should not be seen by this transaction currently. Read View is mainly used to make
judgment, that is, when we certain transaction executes snapshot read, the Record and create a Read View read view, compare it to a condition to determine which version of data the current transaction can see, which may be the current latest The data may also be the data of a certain version in the undo log recorded in this row. Read View several properties
trx_ids
- : The current system is active (
- Uncommitted
) A collection of transaction version numbers.
low_limit_id : "The current system - maximum transaction version number
1" when creating the current read view.
up_limit_id: "The system is in an active transactionminimum version number" when the current read view is createdcreator_trx_id: Create the transaction version number of the current read view;
Read View visibility judgment condition
-
db_trx_id<up_limit_id||db_trx_id==creator_trx_id(display)If the data transaction ID is less than the
Or theminimum active transaction IDin the read view, you can be sure that the dataexistsbefore thecurrent transaction is started. , socan be displayed.transaction ID
of the data is equal tocreator_trx_id, then it means that this data is generated by the current transaction. Of course, the data generated by yourself can be See, so in this case this data can also bedisplayed. db_trx_id
If the data transaction ID is greater than the current system in read view The>= low_limit_id<code> (not displayed)maximum transaction ID
means that the data was generatedafter the current read view was created, so the datadoes not display. If it is less than then enter the next judgment-
db_trx_id
is inactive transaction(trx_ids)does not exist
: It means that the transactionhas been committedwhen the read view is generated. In this case, the data can bedisplayed.Exists
: It means that when my Read View was generated, your transaction is still active and has not yet been committed. The data you modified is also viewed by my current transaction. missing.

What’s mentioned above
Read View is used to support RC (Read Committed, read submission) and RR (Repeatable Read, repeatable read) isolation levelaccomplish. RR and RC generation timing
- #RC
Under the isolation level, every
snapshot readwill begenerated And get the latestRead View; and under the - RR
isolation level, it is
in the same transactionThe first snapshot readwill create aRead View,aftersnapshot reads will get thesame Read View, subsequent queries willnot generaterepeatedly, so the query result of a transaction isthe sameevery time. Solution to the phantom read problem
- Snapshot read
: Controlled through MVCC, no locking required. Perform operations such as additions, deletions, modifications, and searches according to the "grammar" specified in MVCC to avoid phantom reading.
- Current reading
: The problem is solved through next-key lock (row lock gap lock).
The difference between InnoDB snapshot reading at RC and RR levels
- The first read of a certain record by a transaction at the RR level The second snapshot read will create a snapshot and Read View to record other active transactions in the current system. After that, when calling the snapshot read, the same Read View will still be used, so as long as the current transaction is used before other transactions submit updates Snapshot read, then subsequent snapshot reads use the same Read View, so subsequent modifications are not visible;
- That is, at the RR level, when the snapshot read generates a Read View, Read View will record snapshots of all other active transactions at this time, and the modifications of these transactions are not visible to the current transaction. Modifications made by transactions created earlier than the Read View are visible
- #And at the RC level, in the transaction, each snapshot read will generate a new snapshot and Read View. This is why we can see updates submitted by other transactions in transactions at the RC level
- Summary
We can see from the above description, The so-called MVCC refers to the
that usesREAD COMMITTD and REPEATABLE READ two isolation level transactions to access records when performing ordinary SEELCT operations. #The process of version chain, in this way, read-write, write-readoperationsof different transactions can be executed concurrently, thereby improvement System performance. If you want to know more about programming learning, please pay attention to the
column!
The above is the detailed content of The most complete database MVCC in the entire network, I am responsible for any incomplete explanation.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 PHP's big data structure processing skills
May 08, 2024 am 10:24 AM
PHP's big data structure processing skills
May 08, 2024 am 10:24 AM
Big data structure processing skills: Chunking: Break down the data set and process it in chunks to reduce memory consumption. Generator: Generate data items one by one without loading the entire data set, suitable for unlimited data sets. Streaming: Read files or query results line by line, suitable for large files or remote data. External storage: For very large data sets, store the data in a database or NoSQL.
 How to optimize MySQL query performance in PHP?
Jun 03, 2024 pm 08:11 PM
How to optimize MySQL query performance in PHP?
Jun 03, 2024 pm 08:11 PM
MySQL query performance can be optimized by building indexes that reduce lookup time from linear complexity to logarithmic complexity. Use PreparedStatements to prevent SQL injection and improve query performance. Limit query results and reduce the amount of data processed by the server. Optimize join queries, including using appropriate join types, creating indexes, and considering using subqueries. Analyze queries to identify bottlenecks; use caching to reduce database load; optimize PHP code to minimize overhead.
 How to use MySQL backup and restore in PHP?
Jun 03, 2024 pm 12:19 PM
How to use MySQL backup and restore in PHP?
Jun 03, 2024 pm 12:19 PM
Backing up and restoring a MySQL database in PHP can be achieved by following these steps: Back up the database: Use the mysqldump command to dump the database into a SQL file. Restore database: Use the mysql command to restore the database from SQL files.
 How to insert data into a MySQL table using PHP?
Jun 02, 2024 pm 02:26 PM
How to insert data into a MySQL table using PHP?
Jun 02, 2024 pm 02:26 PM
How to insert data into MySQL table? Connect to the database: Use mysqli to establish a connection to the database. Prepare the SQL query: Write an INSERT statement to specify the columns and values to be inserted. Execute query: Use the query() method to execute the insertion query. If successful, a confirmation message will be output.
 How to fix mysql_native_password not loaded errors on MySQL 8.4
Dec 09, 2024 am 11:42 AM
How to fix mysql_native_password not loaded errors on MySQL 8.4
Dec 09, 2024 am 11:42 AM
One of the major changes introduced in MySQL 8.4 (the latest LTS release as of 2024) is that the "MySQL Native Password" plugin is no longer enabled by default. Further, MySQL 9.0 removes this plugin completely. This change affects PHP and other app
 How to use MySQL stored procedures in PHP?
Jun 02, 2024 pm 02:13 PM
How to use MySQL stored procedures in PHP?
Jun 02, 2024 pm 02:13 PM
To use MySQL stored procedures in PHP: Use PDO or the MySQLi extension to connect to a MySQL database. Prepare the statement to call the stored procedure. Execute the stored procedure. Process the result set (if the stored procedure returns results). Close the database connection.
 How to create a MySQL table using PHP?
Jun 04, 2024 pm 01:57 PM
How to create a MySQL table using PHP?
Jun 04, 2024 pm 01:57 PM
Creating a MySQL table using PHP requires the following steps: Connect to the database. Create the database if it does not exist. Select a database. Create table. Execute the query. Close the connection.
 The difference between oracle database and mysql
May 10, 2024 am 01:54 AM
The difference between oracle database and mysql
May 10, 2024 am 01:54 AM
Oracle database and MySQL are both databases based on the relational model, but Oracle is superior in terms of compatibility, scalability, data types and security; while MySQL focuses on speed and flexibility and is more suitable for small to medium-sized data sets. . ① Oracle provides a wide range of data types, ② provides advanced security features, ③ is suitable for enterprise-level applications; ① MySQL supports NoSQL data types, ② has fewer security measures, and ③ is suitable for small to medium-sized applications.
