
 Database
Mysql Tutorial
What is the reason why MySQL index can improve query efficiency so much?
Database
Mysql Tutorial
What is the reason why MySQL index can improve query efficiency so much?
What is the reason why MySQL index can improve query efficiency so much?


Background
I believe everyone will talk about indexes when optimizing databases, and I am no exception. Everyone can basically answer one question about the optimization of data structures. Two or three, and page caching, etc., I can talk about it a few words, but once an interviewer from Alibaba P9 asked me: Can you talk about the process of loading index data from the computer level? (Just wanted me to talk about IO)
I died on the spot.... Because the basic knowledge of computer networks and operating systems is really my blind spot, but I made up for it later, so I won’t talk nonsense. , let’s start with the computer loading data, and talk about indexing from another angle.
Text
MySQL's index is essentially a data structure
Let us first understand the data loading of the computer.
Disk IO and pre-reading:

Let’s talk about disk IO first. Disk reading data relies on mechanical movement. Reading data at one time requires three steps of seeking, finding a point, and copying to memory.
SeekThe time is the time required for the magnetic arm to move to the specified track, usually less than 5ms;
Search point is from the track The average time to find the point where the data exists is half a turn. If it is a 7200 rpm disk, the average time to find the point is 600000/7200/2=4.17ms;
Copy to memory The time is very fast, which is negligible compared with the previous two times, so the average time of one IO is about 9ms. It sounds fast, but it takes 9000 seconds to go through millions of data in the database, which is obviously a disaster level.
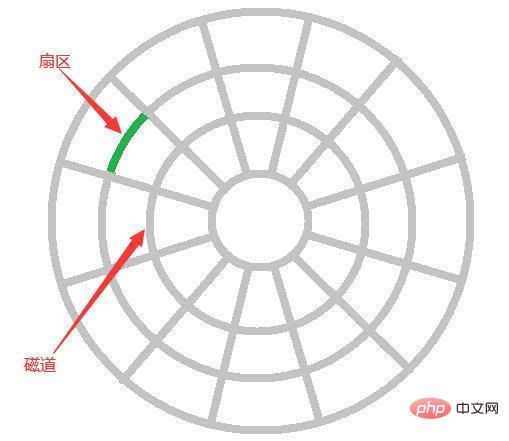
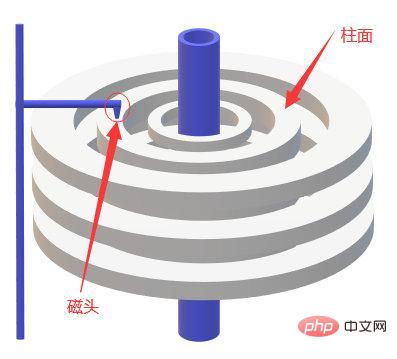
adjacent data are read into the memory buffer, because when the computer accesses the data at an address, it is adjacent to it. The data will also be accessed quickly.
We call the data read by IO each time a page. The specific size of data on a page depends on the operating system. It is usually 4k or 8k, that is, we read the data in one page. At that time, only one IO actually occurred. (Suddenly thought of a question I was asked just after graduation. In a 64-bit operating system, how many bytes does the int type in Java occupy? What is the maximum? Why?) Then if we want to optimize database queries, we mustreduce disk IO operations as much as possible, so indexes appear.
What is an index?MySQLThe official definition of index is: Index (Index) is a data structure that helps MySQL obtain data efficiently.
MySQL The commonly used indexes are physically divided into two categories, B-tree indexes and hash indexes.
BTree index.
BTreeIt is also called a multi-path balanced search tree. The characteristics of an m-fork BTree are as follows:
- Each node in the tree Nodes contain at most m children.
- Except for the root node and leaf nodes, each node has at least [ceil(m/2)] children (ceil() is rounded up).
- If the root node is not a leaf node, it has at least two children.
- All leaf nodes are on the same layer.
- Each non-leaf node consists of n keys and n 1 pointers, where [ceil(m/2)-1] <= n <= m-1.
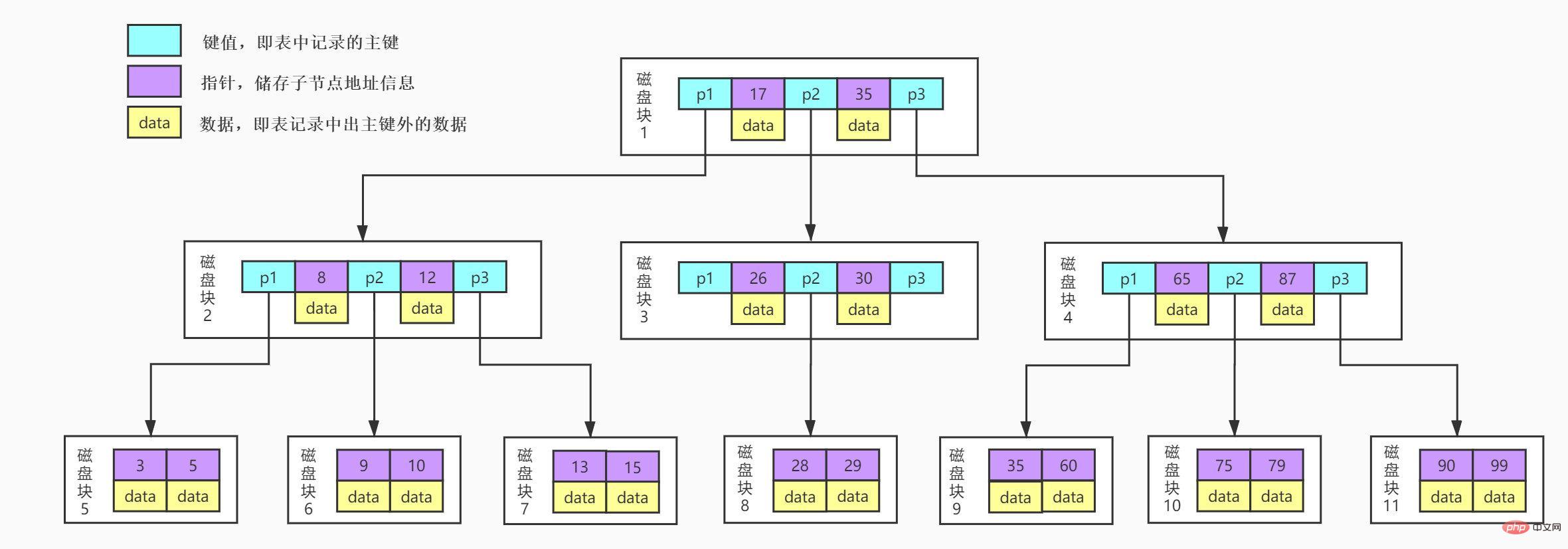
1 time]
2. Disk block 1 stores 17, 35 and three pointer data. We find 17<29<35, so we find pointer p2. 3. According to the p2 pointer, we locate and read disk block 3. [Disk IO operations2 times]
4. Disk block 3 stores 26, 30 and three pointer data. We find 26<29<30, so we find pointer p2.5. According to the p2 pointer, we locate and read disk block 8. [Disk IO operations 3 times]
6, disk block 8 stores 28, 29. We find 29 and get the data corresponding to 29.
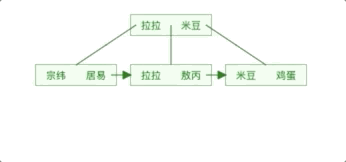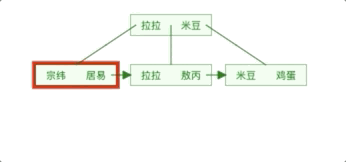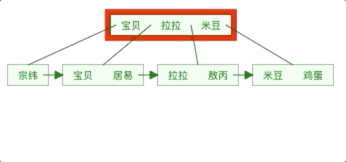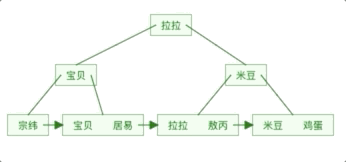
It can be seen that the BTree index makes the data fetched from the memory play a role in each disk I/O, thus improving the query efficiency.
But is there anything that can be optimized?
We can see from the figure that each node contains not only the key value of the data, but also the data value. The storage space of each page is limited. If the data data is large, the number of keys that can be stored in each node (i.e. one page) will be very small. When the amount of stored data is large, it will also lead to B- The depth of Tree is larger, which increases the number of disk I/Os during query, thereby affecting query efficiency.
B Tree Index
B Tree is an optimization based on B-Tree, making it more suitable for implementing external storage index structures . In B Tree, all data record nodes are stored on leaf nodes of the same layer in order of key value. Only key value information is stored on non-leaf nodes. This can greatly increase the number of key values stored in each node. Reduce the height of B Tree.
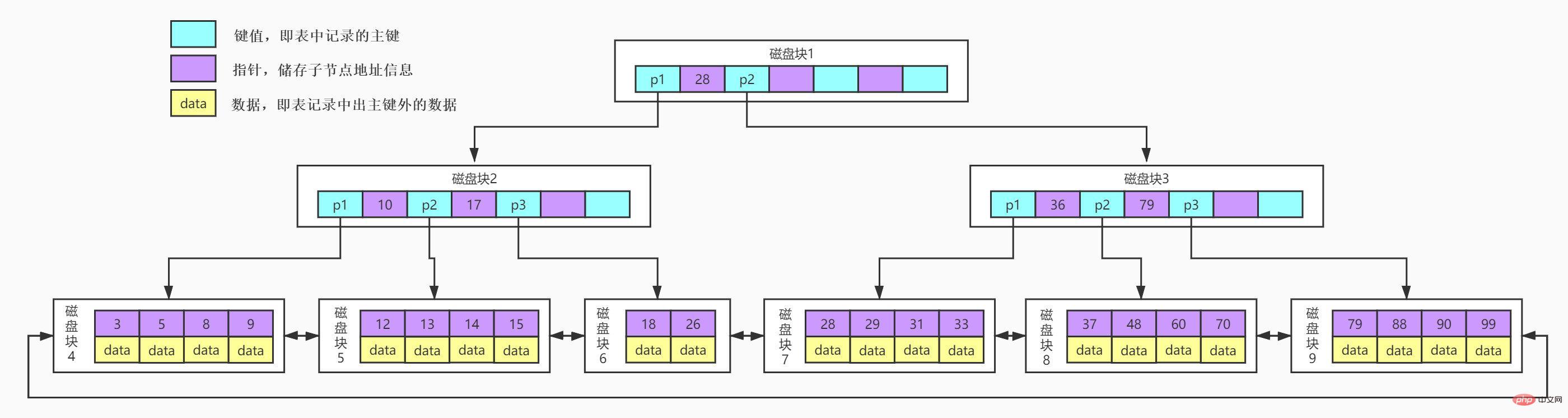
B Tree has several differences compared to B-Tree:
Non-leaf nodes only store key value information, data records are stored in leaf nodes. Optimize the B-Tree in the previous section. Since the non-leaf nodes of B Tree only store key value information, the height of B Tree can be compressed to a particularly low level.
The specific data is as follows:
The page size in the InnoDB storage engine is 16KB. The primary key type of the general table is INT (occupies 4 bytes) or BIGINT (occupies 8 bytes). Bytes), the pointer type is generally 4 or 8 bytes, which means that one page (a node in B Tree) stores approximately 16KB/(8B 8B)=1K key values (because it is an estimate, it is For convenience of calculation, the value of K here is 〖10〗^3).
That is to say, a B Tree index with a depth of 3 can maintain 10^3 10^3 10^3 = 1 billion records. (There are errors in this calculation method, and the leaf nodes are not calculated. If the leaf nodes are calculated, the depth is actually 4)
We only need to perform three IO operations to obtain data from 1 billion pieces of data. To find the data we want, we don’t know how many times better it is than the initial million data of 9,000 seconds.
And there are usually two head pointers on B Tree, one points to the root node, the other points to the leaf node with the smallest key, and there is a chain ring structure between all leaf nodes (i.e. data nodes) . Therefore, in addition to performing primary key range search and paging search on B Tree, we can also perform random searches starting from the root node.
The B Tree index in the database can be divided into clustered index (clustered index) and auxiliary index (secondary index).
The implementation of the above B Tree example diagram in the database is a clustered index. The leaf nodes in the B Tree of the clustered index store the row record data of the entire table. The difference between the auxiliary index and the clustered index is The leaf nodes of the auxiliary index do not contain all the data of the row record, but the clustered index key that stores the corresponding row data, that is, the primary key.
When querying data through the auxiliary index, the InnoDB storage engine will traverse the auxiliary index to find the primary key, and then find the complete row record data in the clustered index through the primary key.
However, although indexes can speed up queries and improve MySQL's processing performance, excessive use of indexes will also cause the following disadvantages:
- Creating and maintaining indexes takes time, and this time increases as the amount of data increases.
- In addition to the data space occupied by the data table, each index also occupies a certain amount of physical space. If you want to create a clustered index, the space required will be larger.
- When adding, deleting, and modifying data in the table, the index must also be dynamically maintained, which reduces the data maintenance speed.
Note: Indexes can speed up queries in some cases, but in some cases, they will reduce efficiency.
Index is only one factor to improve efficiency, so the following principles should be followed when establishing an index:
- Creating indexes on columns that are frequently searched can speed up searches.
- Create an index on the column as the primary key, enforce the uniqueness of the column, and organize the arrangement structure of the data in the table.
- Create indexes on columns that are frequently used for table connections. These columns are mainly foreign keys, which can speed up table connections.
- Create an index on a column that often needs to be searched based on a range. Because the index has been sorted, its specified range is continuous.
- Create indexes on columns that often need to be sorted. Because the index has been sorted, you can use the sorting of the index to speed up sorting queries.
- Create indexes on columns that frequently use WHERE clauses to speed up the judgment of conditions.
Now everyone knows why the index can be so fast. In fact, it is just one sentence. The index structure can minimize the number of IO times in the database. After all, one IO time is really too long. . . .
Summary
As far as interviews are concerned, we can actually master a lot of knowledge easily, but for the purpose of learning, you will find that there are many things that we need to go deep into the basics of computers to discover them. Mystery, many people ask me how I remember so many things. In fact, learning itself is a very helpless thing. Since we have to learn, why not learn it well? To learn to enjoy it? Recently, I have also been studying the basics, and I will start to update my computer basics and network-related knowledge later.
I am Ao Bing. The more you know, the more you don’t know. See you in the next issue!
TALENTS Our 【三连】 is the biggest motivation for Ao Bing’s creation. If there are any errors or suggestions in this blog, talents are welcome to leave a message!
More related free learning recommendations: mysql tutorial(Video)
The above is the detailed content of What is the reason why MySQL index can improve query efficiency so much?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Several situations of mysql index failure
Feb 21, 2024 pm 04:23 PM
Several situations of mysql index failure
Feb 21, 2024 pm 04:23 PM
Common situations: 1. Use functions or operations; 2. Implicit type conversion; 3. Use not equal to (!= or <>); 4. Use the LIKE operator and start with a wildcard; 5. OR conditions; 6. NULL Value; 7. Low index selectivity; 8. Leftmost prefix principle of composite index; 9. Optimizer decision; 10. FORCE INDEX and IGNORE INDEX.
 When might a full table scan be faster than using an index in MySQL?
Apr 09, 2025 am 12:05 AM
When might a full table scan be faster than using an index in MySQL?
Apr 09, 2025 am 12:05 AM
Full table scanning may be faster in MySQL than using indexes. Specific cases include: 1) the data volume is small; 2) when the query returns a large amount of data; 3) when the index column is not highly selective; 4) when the complex query. By analyzing query plans, optimizing indexes, avoiding over-index and regularly maintaining tables, you can make the best choices in practical applications.
 Under what circumstances will mysql index fail?
Aug 09, 2023 pm 03:38 PM
Under what circumstances will mysql index fail?
Aug 09, 2023 pm 03:38 PM
MySQL indexes will fail when querying without using index columns, mismatching data types, improper use of prefix indexes, using functions or expressions for querying, incorrect order of index columns, frequent data updates, and too many or too few indexes. . 1. Do not use index columns for queries. In order to avoid this situation, you should use appropriate index columns in the query; 2. Data types do not match. When designing the table structure, you should ensure that the index columns match the data types of the query; 3. , Improper use of prefix index, you can use prefix index.
 MySQL index left prefix matching rules
Feb 24, 2024 am 10:42 AM
MySQL index left prefix matching rules
Feb 24, 2024 am 10:42 AM
MySQL index leftmost principle principle and code examples In MySQL, indexing is one of the important means to improve query efficiency. Among them, the index leftmost principle is an important principle that we need to follow when using indexes to optimize queries. This article will introduce the principle of the leftmost principle of MySQL index and give some specific code examples. 1. The principle of index leftmost principle The index leftmost principle means that in an index, if the query condition is composed of multiple columns, then only the leftmost column in the index can be queried to fully satisfy the query conditions.
 What are the classifications of mysql indexes?
Apr 22, 2024 pm 07:12 PM
What are the classifications of mysql indexes?
Apr 22, 2024 pm 07:12 PM
MySQL indexes are divided into the following types: 1. Ordinary index: matches value, range or prefix; 2. Unique index: ensures that the value is unique; 3. Primary key index: unique index of the primary key column; 4. Foreign key index: points to the primary key of another table ; 5. Full-text index: full-text search; 6. Hash index: equal match search; 7. Spatial index: geospatial search; 8. Composite index: search based on multiple columns.
 Explain different types of MySQL indexes (B-Tree, Hash, Full-text, Spatial).
Apr 02, 2025 pm 07:05 PM
Explain different types of MySQL indexes (B-Tree, Hash, Full-text, Spatial).
Apr 02, 2025 pm 07:05 PM
MySQL supports four index types: B-Tree, Hash, Full-text, and Spatial. 1.B-Tree index is suitable for equal value search, range query and sorting. 2. Hash index is suitable for equal value searches, but does not support range query and sorting. 3. Full-text index is used for full-text search and is suitable for processing large amounts of text data. 4. Spatial index is used for geospatial data query and is suitable for GIS applications.
 How to use MySQL indexes rationally and optimize database performance? Design protocols that technical students need to know!
Sep 10, 2023 pm 03:16 PM
How to use MySQL indexes rationally and optimize database performance? Design protocols that technical students need to know!
Sep 10, 2023 pm 03:16 PM
How to use MySQL indexes rationally and optimize database performance? Design protocols that technical students need to know! Introduction: In today's Internet era, the amount of data continues to grow, and database performance optimization has become a very important topic. As one of the most popular relational databases, MySQL’s rational use of indexes is crucial to improving database performance. This article will introduce how to use MySQL indexes rationally, optimize database performance, and provide some design rules for technical students. 1. Why use indexes? An index is a data structure that uses
 Performance optimization strategies for data update and index maintenance of PHP and MySQL indexes and their impact on performance
Oct 15, 2023 pm 12:15 PM
Performance optimization strategies for data update and index maintenance of PHP and MySQL indexes and their impact on performance
Oct 15, 2023 pm 12:15 PM
Performance optimization strategies for data update and index maintenance of PHP and MySQL indexes and their impact on performance Summary: In the development of PHP and MySQL, indexes are an important tool for optimizing database query performance. This article will introduce the basic principles and usage of indexes, and explore the performance impact of indexes on data update and maintenance. At the same time, this article also provides some performance optimization strategies and specific code examples to help developers better understand and apply indexes. Basic principles and usage of indexes In MySQL, an index is a special number
