

Java High Concurrency System Design - Cache

java Basics column today introduces the caching chapter of java high-concurrency system design.

The latency of common hardware components is as shown below: 
From these data, you can see that doing a memory Addressing takes about 100ns, and doing a disk lookup takes 10ms. It can be seen that when we use memory as the cache storage medium, the performance will be improved by many orders of magnitude compared to a database that uses disk as the main storage medium. Therefore, memory is the most common medium for caching data.
1. Caching Case
1. TLB
Linux memory management is realized from virtual address to physical address through a piece of hardware called MMU (Memory Management Unit). Converted, but if such complex calculations are required for each conversion, it will undoubtedly cause performance losses, so we will use a component called TLB (Translation Lookaside Buffer) to cache the recently converted virtual addresses and physical addresses. mapping. TLB is a caching component.
2. The short videos on Douyin
platform are actually completed using the built-in network player. The network player receives the data stream, downloads the data, separates the audio and video streams, decodes and other processes, and then outputs it to the peripheral device for playback. Some caching components are usually designed in the player to cache part of the video data when the video is not opened. For example, when we open Douyin, the server may return three video information at a time. When we play the first video, the player We have cached part of the data of the second and third videos for us, so that when watching the second video, we can give users the feeling of "starting in seconds".
3. HTTP protocol cache
When we request a static resource for the first time, such as a picture, in addition to returning the picture information, the server also has an "Etag" in the response header. field. The browser will cache the image information and the value of this field. The next time the image is requested, there will be an "If-None-Match" field in the request header initiated by the browser, and the cached "Etag" value will be written into it and sent to the server. The server checks whether the image information has changed. If not, a 304 status code is returned to the browser, and the browser will continue to use the cached image information. Through this cache negotiation method, the data size transmitted over the network can be reduced, thereby improving page display performance. 
2. Cache classification
1. Static cache
Static cache is very famous in the Web 1.0 era. It usually generates Velocity templates or static HTML files. To implement static caching, deploying static caching on Nginx can reduce the pressure on the backend application server
2. Distributed caching
The name of distributed caching is very familiar, and we are usually familiar with it. Memcached and Redis are typical examples of distributed cache. They have strong performance and can break through the limitations of a single machine by forming a cluster through some distributed solutions. Therefore, in the overall architecture, distributed cache plays a very important role
3. Local cache
Guava Cache or Ehcache, etc. They are deployed in the same process as the application. The advantages It does not require cross-network scheduling and is extremely fast, so it can be used to block hot queries in a short period of time.
3. Cache read and write strategy
1. Cache Aside strategy
Do not update the cache when updating data, but delete the data in the cache and read the data When, after discovering that there is no data in the cache, the data is read from the database and updated to the cache. 
This strategy is the most common strategy we use to cache, Cache Aside strategy (also called bypass cache strategy), this strategy data is based on the data in the database, the data in the cache is on demand loaded.
Cache Aside strategy is the most commonly used caching strategy in our daily development, but we must also learn to change according to the situation when using it, and it is not static. The biggest problem with Cache Aside is that when writes are frequent, the data in the cache will be cleared frequently, which will have some impact on the cache hit rate. If your business has strict requirements on cache hit rate, you can consider two solutions:
One way is to update the cache when updating the data, but add a distributed lock before updating the cache, because in this way only one thread is allowed to update the cache at the same time, and no concurrency problems will occur. Of course, doing this will have some impact on writing performance (recommended);
Another approach is to update the cache when updating data, but just add a shorter expiration time to the cache, so that even if the cache occurs In the case of inconsistency, the cached data will expire quickly, and the impact on the business is acceptable.
2. Read/Write Through
The core principle of this strategy is that users only deal with the cache, and the cache communicates with the database to write or read data. 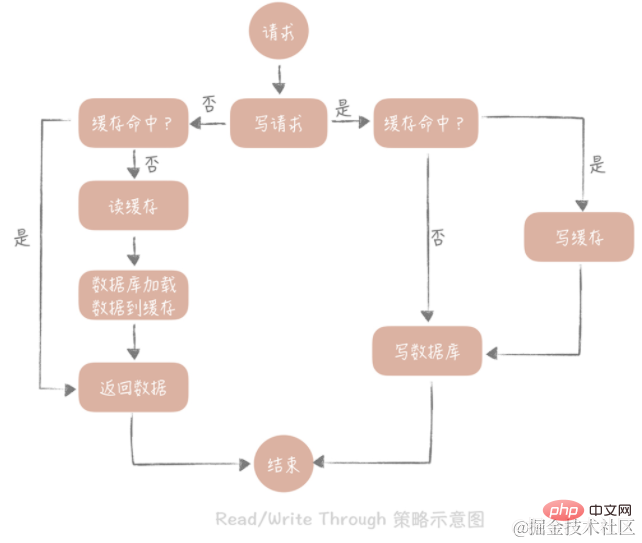
Write Through
The strategy is as follows: first query whether the data to be written already exists in the cache, and if it already exists, update the cache The data in the cache is synchronized and updated to the database by the cache component. If the data in the cache does not exist, we call this situation "Write Miss". Generally speaking, we can choose two "Write Miss" methods: one is "Write Allocate (allocate by write)", which is to write the corresponding location in the cache, and then the cache component updates it to the database synchronously; the other is "No -write allocate (do not allocate on write)", the method is not to write to the cache, but to update directly to the database. We see that writing to the database in the Write Through strategy is synchronous, which will have a greater impact on performance, because the latency of synchronous writing to the database is much higher than writing to the cache. Update the database asynchronously through the Write Back strategy.
Read Through
The strategy is simpler. Its steps are as follows: first query whether the data in the cache exists, and if it exists, return it directly. If it does not exist, The cache component is responsible for synchronously loading data from the database.
3. Write Back
The core idea of this strategy is to only write to the cache when writing data, and mark the cache blocks as "dirty". The data in dirty blocks will only be written to the back-end storage when they are used again.
In the case of "Write Miss", we use the "Write Allocate" method, which means writing to the cache while writing to the backend storage, so that we only need to update the cache in subsequent write requests. , without updating the backend storage. Note the distinction from the write through strategy above. 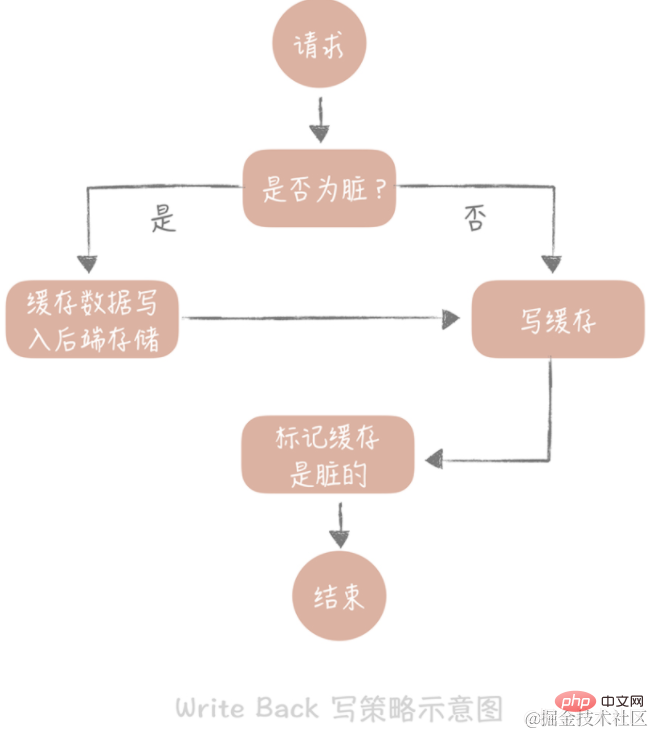
If we find a cache hit when reading the cache, we will directly return the cache data. If the cache misses, it looks for an available cache block. If the cache block is "dirty", the previous data in the cache block is written to the back-end storage, and the data is loaded from the back-end storage to the cache. If the block is not dirty, the cache component will load the data in the back-end storage into the cache. Finally, we will set the cache to not be dirty and return the data. 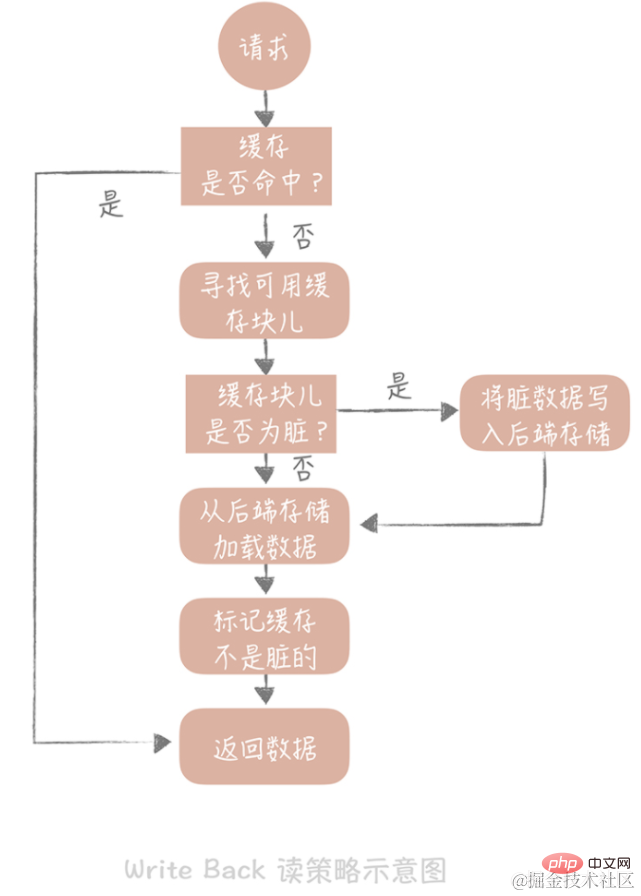
The write back strategy is mostly used to write data to the disk. For example: Page Cache at the operating system level, asynchronous flushing of logs, asynchronous writing of messages in the message queue to disk, etc. Because the performance advantage of this strategy is undoubted, it avoids the random write problem caused by writing directly to disk. After all, the latency of random I/O for writing to memory and writing to disk is several orders of magnitude different.
4. Cache High Availability
The cache hit rate is a data indicator that needs to be monitored by the cache. The high availability of the cache can reduce the probability of cache penetration to a certain extent and improve the stability of the system. High-availability solutions for caching mainly include three categories: client-side solutions, intermediate proxy layer solutions, and server-side solutions:
1. Client-side solution
In the client-side solution, you need to pay attention to caching Both writing and reading aspects: When writing data, the data written to the cache needs to be distributed to multiple nodes, that is, data sharding is performed; When reading data, multiple sets of caches can be used for fault tolerance to improve the availability of the cache system. Regarding reading data, two strategies, master-slave and multi-copy, can be used here. The two strategies are proposed to solve different problems. Specific implementation details include: data sharding, master-slave, and multiple copies
Data sharding
Consistent Hash algorithm. In this algorithm, we organize the entire Hash value space into a virtual ring, and then Hash the IP address or host name of the cache node and place it on this ring. When we need to determine which node a certain Key needs to be accessed, we first do the same Hash value for the Key, determine its position on the ring, and then "walk" on the ring in a clockwise direction. When we encounter The first cache node is the node to be accessed. 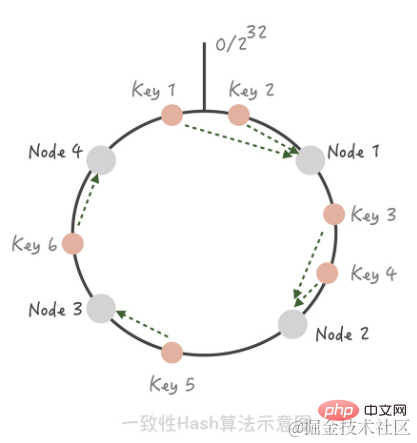
If you add a Node 5 between Node 1 and Node 2, you can see that Key 3 that originally hit Node 2 now hits Node 5, while the other Keys have not changed; In the same way, if we remove Node 3 from the cluster, it will only affect Key 5. So you see, when adding and deleting nodes, only a small number of Keys will "drift" to other nodes, while the nodes hit by most Keys will remain unchanged, thus ensuring that the hit rate will not drop significantly. [Tip] Use virtual nodes to solve the cache avalanche phenomenon that occurs with consistent hashing. The difference between consistent hash sharding and hash sharding is the problem of cache hit rate. When machines are added or reduced, hash sharding will cause the cache to become invalid and the cache hit rate to decrease.
Master-slave
Redis itself supports the master-slave deployment method, but Memcached does not support it. How is the master-slave mechanism of Memcached implemented on the client. Configure a set of Slaves for each group of Masters. When updating data, the masters and slaves update simultaneously. When reading, the data is read from the Slave first. If the data cannot be read, it is read through the Master, and the data is seeded back to the Slave to keep the Slave data hot. The biggest advantage of the master-slave mechanism is that when a certain Slave goes down, the Master will be the backup, so there will not be a large number of requests penetrating into the database, which improves the high availability of the cache system.
Multiple copies
The master-slave method can already solve the problems in most scenarios, but for extreme traffic scenarios, a group of Slave usually cannot fully bear the burden. For all traffic, Slave network card bandwidth may become a bottleneck. In order to solve this problem, we consider adding a copy layer before Master/Slave. The overall architecture is as follows: 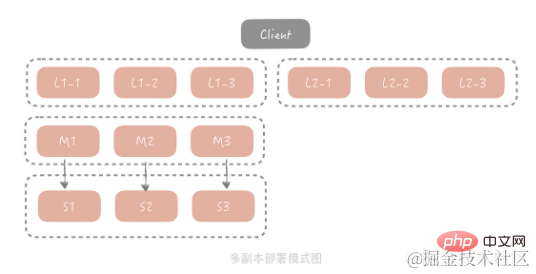
In this solution, when the client initiates a query request, the request will first be sent from Select a copy group from multiple copy groups to initiate a query. If the query fails, the query continues to the Master/Slave, and the query results are seeded back to all copy groups to avoid the existence of dirty data in the copy group. Based on cost considerations, the capacity of each copy group is smaller than that of Master and Slave, so it only stores hotter data. In this architecture, the request volume of the Master and Slave will be greatly reduced. In order to ensure the heat of the data they store, in practice we will use the Master and Slave as a copy group.
2. Intermediate proxy layer
There are also many intermediate proxy layer solutions in the industry, such as Facebook's Mcrouter, Twitter's Twemproxy, and Wandoujia's Codis. Their principles can basically be summarized by a picture: 
3. Server-side solution
Redis proposed the Redis Sentinel mode in version 2.4 to solve the problem of master-slave Redis deployment. High availability problem, it can automatically promote the slave node to the master node after the master node hangs up, ensuring the availability of the entire cluster. The overall architecture is shown in the figure below: 
redis Sentinel is also a cluster deployment This can avoid the problem of automatic failure recovery caused by the failure of Sentinel nodes. Each Sentinel node is stateless. The Master's address will be configured in Sentinel. Sentinel will monitor the status of the Master at all times. When it finds that the Master does not respond within the configured time interval, it will consider that the Master has died. Sentinel will select one of the slave nodes to promote it to the master node, and Treat all other slave nodes as slave nodes for the new master. During the arbitration within the Sentinel cluster, it will be determined based on the configured value. When several Sentinel nodes think that the master is down, they can perform a master-slave switch operation. That is, the cluster needs to reach a consensus on the status of the cache node.
[Tip] The connection between the above client and the Sentinel cluster is a dotted line, because write and read requests for the cache will not pass through the Sentinel node.
5. Cache Penetration
1. Pareto
The data access model of Internet systems generally follows the "80/20 principle". The "80/20 principle", also known as the Pareto Principle, is an economic theory proposed by the Italian economist Pareto. Simply put, it means that in a set of things, the most important part usually only accounts for 20%, while the other 80% is not that important. Applying this to the field of data access, we will frequently access 20% of the hot data, while the other 80% of the data will not be accessed frequently. Since the cache capacity is limited, and most accesses will only request 20% of the hotspot data, theoretically, we only need to store 20% of the hotspot data in the limited cache space to effectively protect the fragile back-end system. , you can give up caching the other 80% of non-hot data. So this small amount of cache penetration is inevitable, but it does no harm to the system.
2. Returning a null value
When we query a null value from the database or an exception occurs, we can return a null value to the cache. However, because the null value is not accurate business data and will occupy cache space, we will add a relatively short expiration time to the null value so that the null value can quickly expire and be eliminated in a short period of time. Although returning null values can block a large number of penetrating requests, if there are a large number of null values cached, it will also waste cache storage space. If the cache space is full, some user information that has been cached will also be eliminated. On the contrary, it will cause the cache hit rate to decrease. Therefore, I suggest you evaluate whether the cache capacity can support this solution when using it. If a large number of cache nodes are needed to support it, then it cannot be solved by planting null values. In this case, you can consider using a bloom filter.
3. Bloom filter
In 1970, Bloom proposed a Bloom filter algorithm to determine whether an element is in a set. This algorithm consists of a binary array and a Hash algorithm. Its basic idea is as follows: We calculate the corresponding Hash value for each value in the set according to the provided Hash algorithm, then modulo the Hash value to the array length to obtain the index value that needs to be included in the array, and add the index value at this position of the array Value changed from 0 to 1. When judging whether an element exists in this set, you only need to calculate the index value of the element according to the same algorithm. If the value of this position is 1, it is considered that the element is in the set, otherwise it is considered not to be in the set. 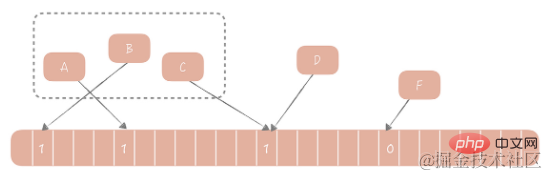
How to use Bloom filter to solve cache penetration?
Take the table that stores user information as an example to explain. First we initialize a large array, say an array with a length of 2 billion, then we choose a Hash algorithm, then we calculate the Hash value of all existing user IDs and map them to this large array, mapping The value of the position is set to 1 and other values are set to 0. In addition to writing to the database, the newly registered user also needs to update the value of the corresponding position in the Bloom filter array according to the same algorithm. Then when we need to query the information of a certain user, we first query whether the ID exists in the Bloom filter. If it does not exist, we directly return a null value without continuing to query the database and cache, which can greatly reduce exceptions. Cache penetration caused by queries. 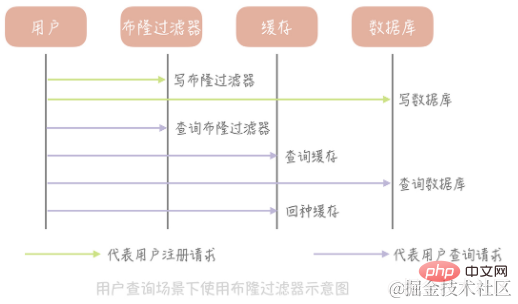
Advantages of Bloom filter:
(1) High performance. Whether it is a write operation or a read operation, the time complexity is O(1) and is a constant value
(2) to save space. For example, an array of 2 billion requires 2000000000/8/1024/1024 = 238M of space. If an array is used for storage, assuming each user ID occupies 4 bytes of space, then storing 2 billion users requires 2000000000 * 4 / 1024 / 1024 = 7600M space, 32 times that of Bloom filter.
Disadvantages of Bloom filter:
(1) It has a certain probability of error when judging whether an element is in the set. For example, it will classify elements that are not in the set. The elements are judged to be in the set.
Reason: The flaw of the Hash algorithm itself.
Solution: Use multiple Hash algorithms to calculate multiple Hash values for the element. Only when the values in the array corresponding to all Hash values are 1, will the element be considered to be in the set.
(2) Deletion of elements is not supported. The defect that Bloom filters do not support deletion of elements is also related to Hash collision. For example, if two elements A and B are both elements in the collection and have the same Hash value, they will be mapped to the same position in the array. At this time, we delete A, and the value of the corresponding position in the array also changes from 1 to 0. Then when we judge B and find that the value is 0, we will also judge that B is an element that is not in the set, and we will get the wrong conclusion.
Solution: Instead of just having 0 and 1 values in the array, I would store a count. For example, if A and B hit the index of an array at the same time, then the value of this position is 2. If A is deleted, the value is changed from 2 to 1. The array in this solution no longer stores bits, but values, which will increase space consumption.
4. Dog pile effect
For example, when there is a very hot cache item, once it fails, a large number of requests will penetrate into the database, which will cause instantaneous and huge pressure on the database. , we call this scene the "dog-pile effect". The idea to solve the dog stub effect is to minimize the concurrency after cache penetration. The solution is relatively simple:
(1) Control in the code to start a background thread after a certain hot cache item expires, and the penetration Go to the database and load the data into the cache. Before the cache is loaded, all requests to access this cache will not penetrate and return directly.
(2) By setting a distributed lock in Memcached or Redis, only the request to obtain the lock can penetrate the database
6. CDN
1, static Reasons for resource acceleration
There are a large number of static resource requests in our system: for mobile APPs, these static resources are mainly pictures, videos and streaming media information; for Web websites, they include JavaScript files, CSS files, static HTML files, etc. They have a huge amount of read requests, require high access speeds, and occupy a high bandwidth. At this time, there will be problems with slow access speeds and full bandwidth affecting dynamic requests. Then you need to consider how to target these static resources. Reading is accelerated.
2. CDN
The key point of static resource access is nearby access, that is, users in Beijing access data in Beijing, and users in Hangzhou access data in Hangzhou. Only in this way can optimal performance be achieved. We consider adding a special layer of cache to the upper layer of the business server to handle most access to static resources. The nodes of this special cache need to be distributed all over the country, so that users can choose the nearest node to access. The cache hit rate also needs to be guaranteed to a certain extent, and the number of requests to access the resource storage origin site (return-to-origin requests) should be minimized. This layer of caching is CDN.
CDN (Content Delivery Network/Content Distribution Network, content distribution network). Simply put, CDN distributes static resources to servers located in computer rooms in multiple geographical locations. Therefore, it can well solve the problem of nearby data access and speed up the access speed of static resources.
3. Build a CDN system
Two points need to be considered when building a CDN system:
(1) How to map user requests to CDN nodes
You may think this is very simple. You only need to tell the user the IP address of the CDN node, and then request the CDN service deployed on this IP address. However, this is not the case. You need to replace the ip with the corresponding domain name. So how to do this? This requires relying on DNS to help us solve the problem of domain name mapping. DNS (Domain Name System) is actually a distributed database that stores the correspondence between domain names and IP addresses. There are generally two types of domain name resolution results, one is called "A record", which returns the IP address corresponding to the domain name; the other is "CNAME record", which returns another domain name, that is to say, the resolution of the current domain name To jump to the resolution of another domain name.
For example: For example, if your company's first-level domain name is called example.com, then you can define the domain name of your image service as "img.example.com", and then parse the domain name The CNAME is configured to the domain name provided by the CDN. For example, ucloud may provide a domain name of "80f21f91.cdn.ucloud.com.cn". In this way, the image address used by your e-commerce system can be "img.example.com/1.jpg".
When the user requests this address, the DNS server will resolve the domain name to the 80f21f91.cdn.ucloud.com.cn domain name, and then resolve the domain name to the CDN node IP, so that the CDN can be obtained resource data.
Domain name level resolution optimization
Because the domain name resolution process is hierarchical, and each level has a dedicated domain name server responsible for the resolution, so the domain name resolution process is possible It requires multiple DNS queries across the public network, which is relatively poor in performance. One solution is to pre-parse the domain name that needs to be parsed when the APP is started, and then cache the parsed results into a local LRU cache. In this way, when we want to use this domain name, we only need to get the required IP address directly from the cache. If it does not exist in the cache, we will go through the entire DNS query process. At the same time, in order to avoid data in the cache becoming invalid due to changes in DNS resolution results, we can start a timer to regularly update the data in the cache.
(2) How to select a relatively close node based on the user’s geographical location information.
GSLB (Global Server Load Balance) means load balancing between servers deployed in different regions. Many local load balancing components may be managed below. It has two functions: on the one hand, it is a load balancing server. Load balancing, as the name suggests, refers to the even distribution of traffic so that the load of the servers managed below is more even; on the other hand, it also needs to ensure that the traffic The server flowing through is relatively close to the source of the traffic.
GSLB can use a variety of strategies to ensure that the returned CDN nodes and users are in the same geographical area as much as possible. For example, the user's IP address can be divided into several areas according to geographical location, and then the CDN nodes can be mapped to In a region, the appropriate node is returned according to the region where the user is located; it is also possible to determine which node to return by sending data packets to measure the RTT.
Summary: DNS technology is the core technology used in CDN implementation, which can map user requests to CDN nodes; DNS resolution results need to be cached locally to reduce the response time of the DNS resolution process; GSLB can provide users with Return a node closer to it to speed up access to static resources.
Expansion
(1) Baidu domain name resolution process
At the beginning, the domain name resolution request will first check the hosts file of the local machine to see if There is an IP corresponding to www.baidu.com; if not, request Local DNS to see if there is a cache of domain name resolution results. If so, return the result indicating that it is returned from a non-authoritative DNS; if not, start an iterative query of DNS. First request the root DNS, which returns the address of the top-level DNS (.com); then request the .com top-level DNS to get the domain name server address of baidu.com; then query the domain name server address of www.baidu.com from the domain name server of baidu.com. IP address, while returning this IP address, mark the result as coming from the authoritative DNS, and write it into the local DNS parsing result cache, so that the next time you parse the same domain name, you don't need to do an iterative DNS query.
(2) CDN delay
Generally, we will write static resources to a certain CDN node through the CDN manufacturer’s interface, and then use the CDN internal The synchronization mechanism disperses and synchronizes resources to each CDN node. Even if the CDN internal network is optimized, this synchronization process is delayed. Once we cannot obtain data from the selected CDN node, we have to obtain data from the source. The network from the user network to the origin site may span multiple backbone networks, which not only causes performance loss but also consumes the bandwidth of the origin site, resulting in higher R&D costs. Therefore, when using a CDN, we need to pay attention to the hit rate of the CDN and the bandwidth of the origin site.
Related learning recommendations: java basics
The above is the detailed content of Java High Concurrency System Design - Cache. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52