

Finally here...RocketMQ Literacy Chapter

java Basic Tutorial column introduces the knowledge about RocketMQ in detail today.

It’s been a long time since I wrote a blog. Although I can find countless reasons for not blogging, in the final analysis, it’s still “lazy”. Today I finally took a pill to cure lazy cancer and decided to write a blog. What should I introduce? After much thought, I’d better introduce RocketMQ. After all, I have written more than 30 blogs, but I haven’t written a good blog about MQ yet. This blog is relatively basic and does not involve source code analysis, just literacy.
What is the use of MQ
Decoupling
I think from a certain perspective, microservices have promoted the vigorous development of MQ. Originally, a system has N multiple modules , all modules are strongly coupled together. Now with microservices, a module is a system, and systems definitely need to interact. There are three common methods of interaction, one is RPC, one is HTTP, and the other is MQ.
Asynchronous
Originally, a business was divided into N steps, which had to be processed step by step before the final result could be returned to the user. Now with MQ, the most critical part is processed first, and then Send a message to MQ and directly return OK to the user. As for the subsequent steps, let's slowly process them in the background. It is really an artifact to improve the user experience.
Peak clipping
The sudden surge in the number of requests for a certain interface will inevitably put a lot of pressure on the application server and database server. Now with MQ, you don’t have to worry about how many requests come. It will be processed slowly in the background.
Introduction to RocketMQ
RocketMQ is written in Java. It is Alibaba’s open source message middleware and absorbs many of the advantages of Kafka. Kafka is also a popular message middleware, but Kafka is written in Scala, which is not conducive for Java programmers to read the source code, and it is also not conducive for Java programmers to do some customized development. Friends who have been exposed to Kafka know that it is not easy to use Kafka well. Relatively speaking, RocketMQ is much simpler, and RocketMQ is blessed by Alibaba and has experienced the test of N Double 11. It is more suitable for domestic Internet companies, so it is used domestically. There are many RocketMQ companies.
The four major components of RocketMQ
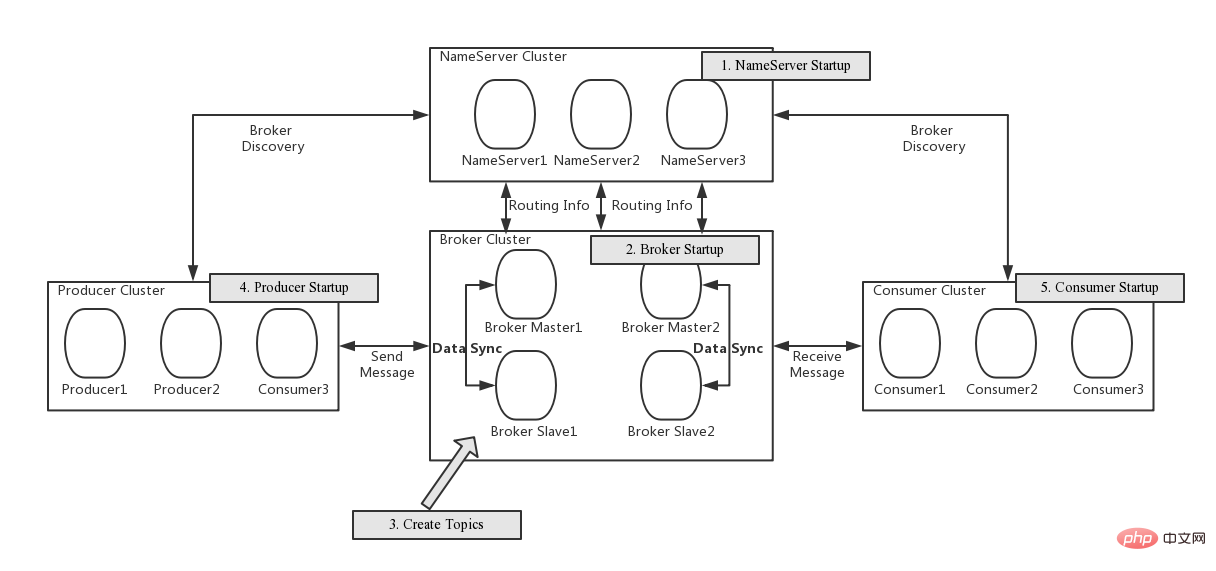 The picture comes from gitee.com/mirrors/roc...
The picture comes from gitee.com/mirrors/roc...
You can see that RocketMQ has four main components:
NameServer
- Stateless service, registration center, can be deployed in clusters, but there is no data interaction between NameServer nodes.
- Borker will report Topic routing information to all NameServers regularly. Producer and Consumer will randomly select a NameServer Topic to update routing information regularly.
- Topic routing information adopts eventual consistency in the NameServer cluster.
- Guaranteed AP.
Borker
- The server of RocketMQ is used to store and distribute messages.
- Borker will regularly report all Topic routing information it owns to NameServer.
- Borker has two roles: Master and Follower. Master is responsible for reading (consuming messages) and writing (producing messages) operations. If Master is busy or unavailable, Follower can undertake reading operations. BorkerId=0 means Matser, BorkerId!=0 means Follower. There are two points to note: First, so far, only Followers with BorkerId=1 can undertake read operations; Second, only higher versions of RocketMQ support automatic upgrade of Follower to Master when the Master node hangs up.
Producer
The producer initiates Topic routing information query to NameServer at regular intervals.
Consumer
Consumer initiates Topic routing information query to NameServer at regular intervals.
Why the registration center does not use Zookeeper
In fact, in the lower version of RocketMQ, Zookeeper was indeed used as the registration center, but it was later changed to the current NameServer. I guess the main reason is:
- RocketMQ is already a middleware, and I don’t want to rely on other middleware.
- Zookeeper is relatively heavy and has many functions that RocketMQ cannot use. It is better to write a lightweight registration center.
- Zookeeper is a CP. Once the leader election is triggered, the registration center will be unavailable. However, RocketMQ's registration center does not require strong consistency, as long as it ensures eventual consistency.
RocketMQ message domain model
Message
- Transmitted message.
- The message must have a Topic.
- Messages can have multiple tags and multiple keys, which can be regarded as additional attributes of the message.
Topic
- A collection of messages of one type.
- Each message must have a Topic.
- The first-level type of message.
Tag
- In addition to a Topic, a message can also have Tags, which are used to subdivide different types of messages under the same Topic.
- Tag is not required.
- Second-level type of message.
Group
It is divided into ProducerGroup and ConsumerGroup. We pay more attention to ConsumerGroup. ConsumerGroup contains multiple Consumers.
In cluster consumption mode, consumers under a ConsumerGroup consume a Topic together, and each Consumer will be assigned to N queues, but a queue will only be consumed by one Consumer. Different ConsumerGroups can consume the same A Topic and a message will be consumed by all ConsumerGroups subscribed to this Topic.
Queue
- A Topic contains four Queues by default.
- In cluster consumption mode, Consumers in the same ConsumerGroup can consume messages from multiple Queues, but one Queue can only be consumed by one Consumer.
- Messages in the Queue are ordered.
- It is divided into read Queue and write Queue. Generally speaking, the number of read Queue and the number of write Queue are consistent, otherwise it is easy to cause problems.
Consumption mode
There are two consumption modes: Clustering (cluster consumption) and Broadcasting (broadcast consumption).
Different from other MQs, other MQs specify cluster consumption or broadcast consumption when sending messages. RocketMQ sets cluster consumption or broadcast consumption on the consumer side.
Clustering (cluster consumption)
The default is cluster consumption mode. In this mode, all Consumers of the ConsumerGroup jointly consume messages from a Topic, and each Consumer is responsible for consuming messages from N queues. (N may also be 1, or even 0, which is not assigned to the queue), but a queue will only be consumed by one Consumer. If a Consumer dies, other Consumers under the ConsumerGroup will take over and continue consuming.
In cluster consumption mode, the consumption progress is maintained on the Borker side, and the storage path is ${ROCKET_HOME}/store/config/ consumerOffset.json, as shown in the following figure: 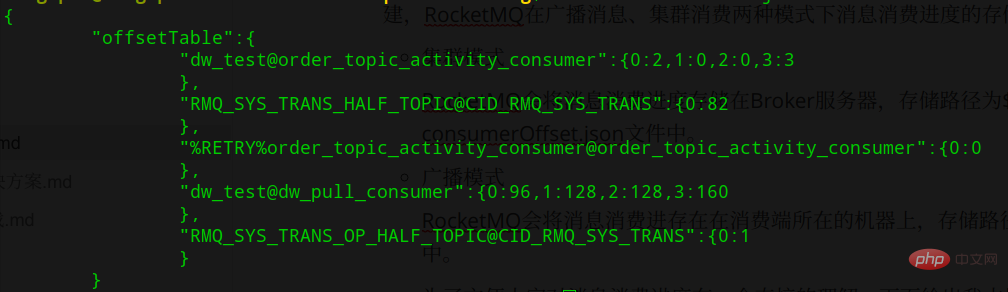 Use
UsetopicName@consumerGroupName is Key, and the consumption progress is Value. The form of Value is queueId:offset, indicating that if there are multiple ConsumerGroups, the consumption progress of each ConsumerGroup is different and needs to be separated. storage.
Broadcasting (broadcast consumption)
Broadcast consumption messages will be sent to all Consumers in the ConsumerGroup.
In broadcast consumption mode, the consumption progress is maintained on the Consumer side.
Consumption Queue Load Algorithm and Rebalancing Mechanism
Consumption Queue Load Algorithm
We know that in cluster consumption mode, all Consumers under the ConsumerGroup jointly consume a Topic message , each Consumer is responsible for consuming messages from N queues, so how is it allocated? This involves the consumption queue load algorithm.
RocketMQ provides numerous consumer queue load algorithms, among which the two most commonly used algorithms are AllocateMessageQueueAveragely and AllocateMessageQueueAveragelyByCircle. Let's take a look at the differences between these two algorithms.
Assume that a Topic now has 16 queues, represented by q0~q15, and 3 Consumers, represented by c0-c2.
The results of using AllocateMessageQueueAveragely to consume the queue load algorithm are as follows:
- c0:q0 q1 q2 q3 q4 q5
- c1:q6 q7 q8 q9 q10
- c2:q11 q12 q13 q14 q15
The results of using AllocateMessageQueueAveragelyByCircle to consume the queue load algorithm are as follows:
- c0:q0 q3 q6 q9 q12 q15
- c1:q1 q4 q7 q10 q13
- c2:q2 q5 q8 q11 q14
All Consumers under the ConsumerGroup consume messages from a Topic together, and each Consumer is responsible for consuming N queues messages, but a queue cannot be consumed by N Consumers at the same time. What does this mean?
If you are smart, you must have thought that if a Topic has only 4 queues and 5 Consumers, then one Consumer will not be assigned to any queue, so in RocketMQ, the number of queues under the Topic is directly It determines the maximum number of Consumers, which means that you cannot increase the consumption speed just by adding more Consumers.
Rebalancing
Although it is recommended that the number of queues should be fully considered when creating a Topic, the actual situation is often unsatisfactory. Even if the number of queues does not change, the number of Consumers will remain the same. Changes will occur, such as when a Consumer goes online or offline, a Consumer hangs up, or a new Consumer is added. The expansion and contraction of the queue and the expansion and contraction of the Consumer will lead to rebalancing, that is, the consumption queue is redistributed to the Consumer.
In RocketMQ, the Consumer will periodically query the number of Topic queues. If the number of Consumers changes, rebalancing will be triggered.
Rebalancing is implemented internally by RocketMQ, and programmers do not need to care.
Pull OR Push?
Generally speaking, MQ has two methods to obtain messages:
- Pull: Consumer actively pulls messages. The advantage is that Consumer can control the frequency and number of messages pulled. Knowing its own consumption capacity, it is not easy to cause message accumulation on the Consumer side, but the real-time performance is not very good and the efficiency is relatively low.
- Push: Broker actively sends messages, which has the advantage of real-time and high efficiency. However, Broker cannot know the consumption capacity of Consumer. If too many messages are sent to Consumer, it will cause the accumulation of messages on Consumer side; if sent to If the Consumer's data is too little, the Consumer side will be idle.
Whether it is Pull or Push, the Consumer will always interact with the Broker. The interaction methods generally include short connection, long connection, and polling.
It seems that RocketMQ supports both Pull and Push, but in fact Push is also implemented using Pull. So how does the Consumer interact with the Broker?
This is the ingenious part of RocketMQ's design. It is neither a short connection, nor a long connection, nor polling, but long polling.
Long polling
Consumer initiates a request to pull messages, which is divided into two situations:
- There is a message: After the Consumer gets the message, the connection is disconnected .
- No message: Borker Hold (keeps) the connection for a certain period of time. Every 5 seconds, it checks whether there is a message. If there is a message, it is sent to the Consumer and the connection is disconnected.
Transaction Message
RocketMQ supports transaction messages. After the Producer sends the transaction message to the Broker, the Broker will store the message in the system Topic: RMQ_SYS_TRANS_HALF_TOPIC, so that the Consumer This message cannot be consumed.
Broker will have a scheduled task, consume the RMQ_SYS_TRANS_HALF_TOPIC message, and initiate a review to the Producer. There are three statuses of the review: submitted, rolled back, and unknown.
- If the status of the review is submission or rollback, the submission and rollback of the message will be triggered;
- If it is unknown, it will wait for the next review. RocketMQ can set a The checkback interval and the number of checkbacks for the message. If the number of checkbacks exceeds a certain number, the message will be automatically rolled back.
Delayed message
Delayed message means that after the message is sent to the Broker, it cannot be consumed by the Consumer immediately. It needs to wait for a certain period of time before it can be consumed. RocketMQ only supports specific delays. Time: 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h.
Consumption Form
RocketMQ supports two consumption forms: concurrent consumption and sequential consumption. If it is consumed sequentially, you need to ensure that the sorted messages are in the same queue. How to choose a queue to send? RocketMQ has several overloads for sending messages, one of which supports queue selection.
Synchronous disk flushing, asynchronous disk flushing
Producer sends messages to Borker. Borker needs to persist the message. RocketMQ supports two persistence strategies:
- Synchronous flushing: Borker persists the message before returning ACK to the Producer. The advantage is that the message is highly reliable, but the efficiency is slow.
- Asynchronous flushing: Broker writes the message into PageCache and returns ACK to Producer. The advantage is that it is extremely efficient, but if the server hangs up, messages may be lost. If only the RocketMQ service hangs up, messages will not be lost.
Synchronous replication, asynchronous replication
In order to ensure the reliability and availability of MQ, in the production environment, follower nodes are generally deployed, and the follower nodes will copy the master's data. RocketMQ supports two types Persistent replication strategy:
- Synchronous replication: Master and Follower both write the message successfully before returning ACK to the Producer. The reliability is higher, but the efficiency is slower.
- Asynchronous replication: As long as the Master writes successfully, ACK is returned to the Producer, which is more efficient, but messages may be lost.
Whether "writing" is written to PageCache or to the hard disk depends on the configuration of Follower Broker.
Let’s talk about Producer
RocketMQ provides three methods of sending messages:
- oneway: fire and forget, one-way message, which means that after the message is sent, it will be ignored. This method has no return value.
- Synchronization: After the message is sent, wait for the Borker's response synchronously.
- Asynchronous: After the message is sent, it returns immediately. After receiving Boker's response, the function call method will be executed.
In actual development, the synchronization method is generally used. If you want to improve the performance of RocketMQ, you usually modify the parameters on the Borker side, especially the disk brushing strategy and the replication strategy.
Retry sending messages
When sending messages, if MessageQueueSelector is used, the retry mechanism for message sending will be invalid.
The response to sending a message may be the following four:
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}复制代码Except for the first one, the other situations are problematic. In order to ensure that the message is not lost, you need to set the Producer parameters: RetryAnotherBrokerWhenNotStoreOK is true.
Fault avoidance mechanism
If the message fails to be sent, it will still be sent to the Borker when retrying, so there is a high probability that the sending will still fail. The ingenious design of RockteMQ is that the retry time, it will automatically avoid this Borker and choose other Borkers. However, so far, asynchronous sending is not so smart and will only retry on one Borker, so it is strongly recommended to choose the synchronous sending method.
RocketMQ provides two fault avoidance mechanisms. Use parameter SendLatencyFaultEnable to control.
- false: Default value. The fault avoidance mechanism will be enabled only when retrying. For example, if sending a message to BorkerA fails, BorkerB will be selected when retrying, but the message will be sent next time. , will still choose to send it to BorkerA.
- true: Turn on the delay backoff mechanism. Once a message fails to be sent to BorkerA, it will pessimistically think that BorkerA will be unavailable for a period of time, and no more messages will be sent to BorkerA for a period of time in the future.
The delayed backoff mechanism seems to be very useful, but generally speaking, the Borker end is busy, causing the Borker to be unavailable or the network to be unavailable. It only takes a moment and can be restored immediately. If delayed backoff is turned on Mechanism, the Borker that was originally available was circumvented for a period of time, and other Borkers were busier, which may make the situation worse.
Let’s talk about Consumer
Consumer thread considerations
Consumer has two parameters, the degree of parallelism that can be consumed, namely ConsumeThreadMin, ConsumeThreadMax, it seems that if there are relatively few messages accumulated on the Consumer side, the number of consumer threads is ConsumeThreadMin; if there are more messages accumulated on the Consumer side, a new thread will be automatically opened for consumption. Until the number of consumer threads is ConsumeThreadMax. But this is not the case. The Consumer holds a thread pool internally and uses an unbounded queue, that is, the ConsumeThreadMax parameter is invalid, so in actual development, ConsumeThreadMin, ConsumeThreadMax is often set to the same value.
ConsumeFromWhere
If the consumption progress cannot be queried, where does the Consumer start consuming? RocketMQ supports consumption in three ways: the latest message, the earliest message, and the specified timestamp.
Consumption message retry
RocketMQ will set up a retry queue with a Topic name of %RETRY% consumerGroup for each ConsumerGroup to save the retry queue that needs to be sent to the ConsumerGroup. Retry message, but retry requires a certain delay time. RocketMQ processes the retry message by first saving it to the delay queue with the Topic name SCHEDULE_TOPIC_XXXX, and then the background scheduled task is Delayed according to the corresponding time. Resave it in the retry queue of %RETRY% consumerGroup.
What should I do if messages accumulate and consumption capacity is insufficient?
- This is the best way to improve the consumption progress.
- Add queue and add Consumer.
- The original Consumer acts as a brick mover and "moves" messages to multiple new Topics according to certain rules, and then opens several ConsumerGroups to consume different Topics.
- Open a new ConsumerGroup for consumption, that is, two ConsumerGroups consume a Topic at the same time, but you need to pay attention to the judgment of offset. For example, a ConsumerGroup consumes messages with an odd number, and a ConsumerGroup consumes messages with an even number.
I originally thought that I would be able to write smoothly if I wrote literacy text, but I still overthought it. Because it is a literacy text, it is aimed at friends who have not had much contact with RocketMQ, but is RocketMQ that good? It is simple. It is impossible to use a blog to let friends who have not had much contact with RocketMQ get started smoothly. So when writing the blog, I have been thinking, is this thing important and does it need to be described carefully? This thing can be ignored or not. Introduction, etc. You can see that this article basically introduces various concepts and almost does not involve the API level, because once the API is involved, it is estimated that it will not be finished in two weeks.
End
Related free learning recommendations: java basic tutorial
The above is the detailed content of Finally here...RocketMQ Literacy Chapter. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How does SpringBoot integrate RocketMQ?
May 14, 2023 am 10:19 AM
How does SpringBoot integrate RocketMQ?
May 14, 2023 am 10:19 AM
1. SpringBoot integrates RocketMQ. Integrating RocketMQ in SpringBoot only requires four simple steps: 1. Introduce the relevant dependency org.apache.rocketmqrocketmq-spring-boot-starter2. Add the relevant configuration of RocketMQ rocketmq:consumer:group:springboot_consumer_group# pull once The maximum value of the message. Note that it is the maximum value of the message pulled, not the maximum value consumed. pull-batch-size:10name-server:10.5.103.6:9876pr
 Alibaba's second page: RocketMQ consumer pulls a batch of messages, but some of them fail to consume. How to update the offset?
Apr 12, 2023 pm 11:28 PM
Alibaba's second page: RocketMQ consumer pulls a batch of messages, but some of them fail to consume. How to update the offset?
Apr 12, 2023 pm 11:28 PM
Hello everyone, I am Brother Jun. Recently, a reader was asked a question during an interview. If a consumer pulls a batch of messages, such as 100 messages, and the 100th message is successfully consumed, but the 50th message fails, how will the offset be updated? Regarding this issue, let’s talk today about how to save the offset if a batch of messages fails to be consumed. 1 Pulling messages 1.1 Encapsulating pull requests Taking RocketMQ push mode as an example, the RocketMQ consumer startup code is as follows: public static void main(String[] args) throws InterruptedException, MQClie
 Common environment deployment—Docker installation RocketMQ tutorial!
Mar 07, 2024 am 09:30 AM
Common environment deployment—Docker installation RocketMQ tutorial!
Mar 07, 2024 am 09:30 AM
The process of installing RocketMQ in Docker is as follows: Create a Docker network: Execute the following command in the terminal to create a Docker network for communication between containers: dockernetworkcreaterocketmq-network Download the RocketMQ image: Execute the following command in the terminal to download RocketMQ Docker image: dockerpullrocketmqinc/rocketmq Start the NameServer container: Execute the following command in the terminal to start the NameServer container: dockerrun -d --namermqnamesrv --
 How to solve the pitfalls encountered when integrating RocketMQ with SpringBoot
May 19, 2023 am 11:25 AM
How to solve the pitfalls encountered when integrating RocketMQ with SpringBoot
May 19, 2023 am 11:25 AM
Application scenarios When implementing RocketMQ consumption, the @RocketMQMessageListener annotation is generally used to define Group, Topic, and selectorExpression (data filtering and selection rules). In order to support dynamic filtering of data, expressions are generally used, and then dynamic switching is performed through apollo or cloudconfig. . Introduce dependency org.apache.rocketmqrocketmq-spring-boot-starter2.0.4 consumer code @RocketMQMessageListener(consumerGroup=&qu
 Analysis of Java development RocketMQ producer high availability example
Apr 23, 2023 pm 11:28 PM
Analysis of Java development RocketMQ producer high availability example
Apr 23, 2023 pm 11:28 PM
1 message publicclassMessageimplementsSerializable{privatestaticfinallongserialVersionUID=8445773977080406428L;//Topic name privateStringtopic;//Message extension information, Tag, keys, delay level all exist here privateMappproperties;//Message body, byte array privatebyte[]body;//Set the key of the message , publicvoidsetKeys(Stringkeys){}//Set
 How to implement broadcast messages in RocketMQ in Springboot
May 11, 2023 pm 08:13 PM
How to implement broadcast messages in RocketMQ in Springboot
May 11, 2023 pm 08:13 PM
There are two main RocketMQ message modes: broadcast mode and cluster mode (load balancing mode). The broadcast mode means that each consumer will consume messages; the load balancing mode means that each consumption will only be consumed once by a certain consumer; in our business The load balancing mode is generally used. Of course, some special scenarios require the broadcast mode, such as sending a message to a mailbox, mobile phone, or in-site prompt; we can set it through the messageModel attribute value of @RocketMQMessageListener. MessageModel.BROADCASTING is the broadcast mode. MessageModel .CLUSTERING is the default cluster load balancing mode.
 How does RocketMQ implement message sending and receiving in Springboot?
May 18, 2023 pm 05:19 PM
How does RocketMQ implement message sending and receiving in Springboot?
May 18, 2023 pm 05:19 PM
Springboot+rockermq implements simple message sending and receiving. There are three ways to send ordinary messages: one-way sending, synchronous sending and asynchronous sending. Let's introduce the integration of springboot+rockermq to realize the sending and receiving of ordinary messages. Create a Springboot project and add rockermq dependency org.apache.rocketmqrocketmq-spring-boot-starter2.2.1 configure rocketmq#portserver:port:8083#configuration rocketmqrocketmq:name- server:127.0.0.1:98
 How SpringBoot integrates RocketMQ transactions, broadcasts and sequential messages
May 18, 2023 am 10:04 AM
How SpringBoot integrates RocketMQ transactions, broadcasts and sequential messages
May 18, 2023 am 10:04 AM
Environment: springboot2.3.9RELEASE+RocketMQ4.8.0 depends on org.springframework.bootspring-boot-starter-weborg.apache.rocketmqrocketmq-spring-boot-starter2.2.0 configuration file server:port:8080---rocketmq:nameServer:localhost: 9876producer:group:demo-mq ordinary message is sent @ResourceprivateRocketMQT
