

Summary of 2020 new Java basic interview questions


The difference between ==, equals and hashCode in java
(More interview question recommendations: java interview questions and answers)
1, ==
Data types in Java can be divided into two categories:
Basic data types, also called primitive data types To compare byte, short, char, int, long, float, double, boolean, use the double equal sign (==), and compare their values.
Reference type (class, interface, array) When they compare using (==), they compare their storage addresses in memory. Therefore, unless they are the same new object, the result of their comparison is true, otherwise the result of the comparison is false. Objects are placed on the heap, and the reference (address) of the object is stored on the stack. First look at the virtual machine memory map and code:
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}The result is:
false
true

Both s1 and s2 store the addresses of the corresponding objects. Therefore, if s1== s2 is used, the address values of the two objects are compared (that is, whether the references are the same), which is false. When calling the equals direction, the value in the corresponding address is compared, so the value is true. Here we need to describe equals() in detail.
2. Detailed explanation of equals() method
The equals() method is used to determine whether other objects are equal to this object. It is defined in Object, so any object has the equals() method. The difference is whether the method is overridden or not.
Let’s take a look at the source code first:
public boolean equals(Object obj) { return (this == obj);
}Obviously, Object defines a comparison of the address values of two objects (that is, comparing whether the references are the same). But why does calling equals() in String compare not the address but the value in the heap memory address? Here is the key point. When encapsulation classes such as String, Math, Integer, Double, etc. use the equals() method, they have already covered the equals() method of the object class. Take a look at the rewritten equals() in String:
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}After rewriting, this is the content comparison, and it is no longer the comparison of the previous address. By analogy, classes such as Math, Integer, Double, etc. all override the equals() method to compare contents. Of course, basic types perform value comparisons.
It should be noted that when the equals() method is overridden, hashCode() will also be overridden. According to the implementation of the general hashCode() method, equal objects must have equal hashcodes. Why is this so? Here we briefly mention hashcode.
3. A brief discussion of hashcode()
It is obviously a question about the difference between ==, equals and hashCode in Java, but why is it suddenly related to hashcode(). You must be very depressed, okay, let me give a simple example and you will know why hashCode is involved when == or equals.
For example: If you want to find out whether a collection contains an object, how should you write the program? If you don't use the indexOf method, just traverse the collection and compare whether you think of it. What if there are 10,000 elements in the collection, it would be tiring, right? So in order to improve efficiency, the hash algorithm was born. The core idea is to divide the collection into several storage areas (can be seen as buckets). Each object can calculate a hash code and can be grouped according to the hash code. Each group corresponds to a certain storage area. In this way, an object can be grouped according to the hash code. Its hash code can be divided into different storage areas (different areas).
So when comparing elements, the hashcode is actually compared first, and if they are equal, the equal method is compared.
Look at the hashcode diagram:

#An object generally has a key and a value, and its hashCode value can be calculated based on the key. Then it is stored in different storage areas according to its hashCode value, as shown in the figure above. Multiple values can be stored in different areas because hash conflicts are involved. Simple: If the hashCode of two different objects is the same, this phenomenon is called a hash conflict. Simply put, it means the hashCode is the same but equals is a different value. For comparing 10,000 elements, there is no need to traverse the entire collection. You only need to calculate the hashCode of the key of the object you want to find, and then find the storage area corresponding to the hashCode. The search is over.

大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。
总结:
- hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
- equals重写的时候hashCode也跟着重写
- 两对象equals如果相等那么hashCode也一定相等,反之不一定。
2. int、char、long 各占多少字节数
byte 是 字节
bit 是 位
1 byte = 8 bit
char在java中是2个字节,java采用unicode,2个字节来表示一个字符
short 2个字节
int 4个字节
long 8个字节
float 4个字节
double 8个字节
3. int和Integer的区别
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
延伸: 关于Integer和int的比较
- 由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
- Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
- 非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
- 对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true
Integer i = 128; Integer j = 128; System.out.print(i == j); //false
对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <p>java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了</p><h2 id="java多态的理解">4. java多态的理解</h2><h3 id="多态概述">1.多态概述</h3><ol>
<li><p>多态是继封装、继承之后,面向对象的第三大特性。</p></li>
<li><p>多态现实意义理解:</p></li>
</ol>现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态。
Java作为面向对象的语言,同样可以描述一个事物的多种形态。如Student类继承了Person类,一个Student的对象便既是Student,又是Person。
多态体现为父类引用变量可以指向子类对象。
前提条件:必须有子父类关系。
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
- 多态的定义与使用格式
定义格式:父类类型 变量名=new 子类类型();
2.多态中成员的特点
- 多态成员变量:编译运行看左边
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
- 多态成员方法:编译看左边,运行看右边
Fu f1=new Zi();
System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。
3.instanceof关键字
作用:用来判断某个对象是否属于某种数据类型。
* 注意: 返回类型为布尔类型
使用案例:
Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的类型");
}else{
System.out.println("f1是Son的类型");
}4.多态的转型
多态的转型分为向上转型和向下转型两种
-
向上转型:多态本身就是向上转型过的过程
使用格式:父类类型 变量名=new 子类类型();
适用场景:当不需要面对子类类型时,通过提高扩展性,或者使用父类的功能就能完成相应的操作。
-
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用类型转为子类引用各类型
使用格式:子类类型 变量名=(子类类型)父类类型的变量;
适用场景:当要使用子类特有功能时。
5.多态案例:
例1:
package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//调用特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃饭");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好学习");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃樱桃");
}
public void teach(){
System.out.println("认真授课");
}
}答案:吃水煮肉片 好好学习
例2:
请问题目运行结果是什么?
package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}答案:A B
5. String、StringBuffer和StringBuilder区别
1、长度是否可变
- String 是被 final 修饰的,他的长度是不可变的,就算调用 String 的concat 方法,那也是把字符串拼接起来并重新创建一个对象,把拼接后的 String 的值赋给新创建的对象
- StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象,StringBuffer 与 StringBuilder 中的方法和功能完全是等价的。调用StringBuffer 的 append 方法,来改变 StringBuffer 的长度,并且,相比较于 StringBuffer,String 一旦发生长度变化,是非常耗费内存的!
2、执行效率
- 三者在执行速度方面的比较:StringBuilder > StringBuffer > String
3、应用场景
- 如果要操作少量的数据用 = String
- 单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
- 多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
StringBuffer和StringBuilder区别
1、是否线程安全
- StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问),StringBuffer是线程安全的。只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
2、应用场景
- 由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。
- 然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。 append方法与直接使用+串联相比,减少常量池的浪费。
6. 什么是内部类?内部类的作用
内部类的定义
将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
内部类的作用:
成员内部类 成员内部类可以无条件访问外部类的所有成员属性和成员方法(包括private成员和静态成员)。 当成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。
局部内部类 局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
匿名内部类 匿名内部类就是没有名字的内部类
静态内部类 指被声明为static的内部类,他可以不依赖内部类而实例,而通常的内部类需要实例化外部类,从而实例化。静态内部类不可以有与外部类有相同的类名。不能访问外部类的普通成员变量,但是可以访问静态成员变量和静态方法(包括私有类型) 一个 静态内部类去掉static 就是成员内部类,他可以自由的引用外部类的属性和方法,无论是静态还是非静态。但是不可以有静态属性和方法
(学习视频推荐:java课程)
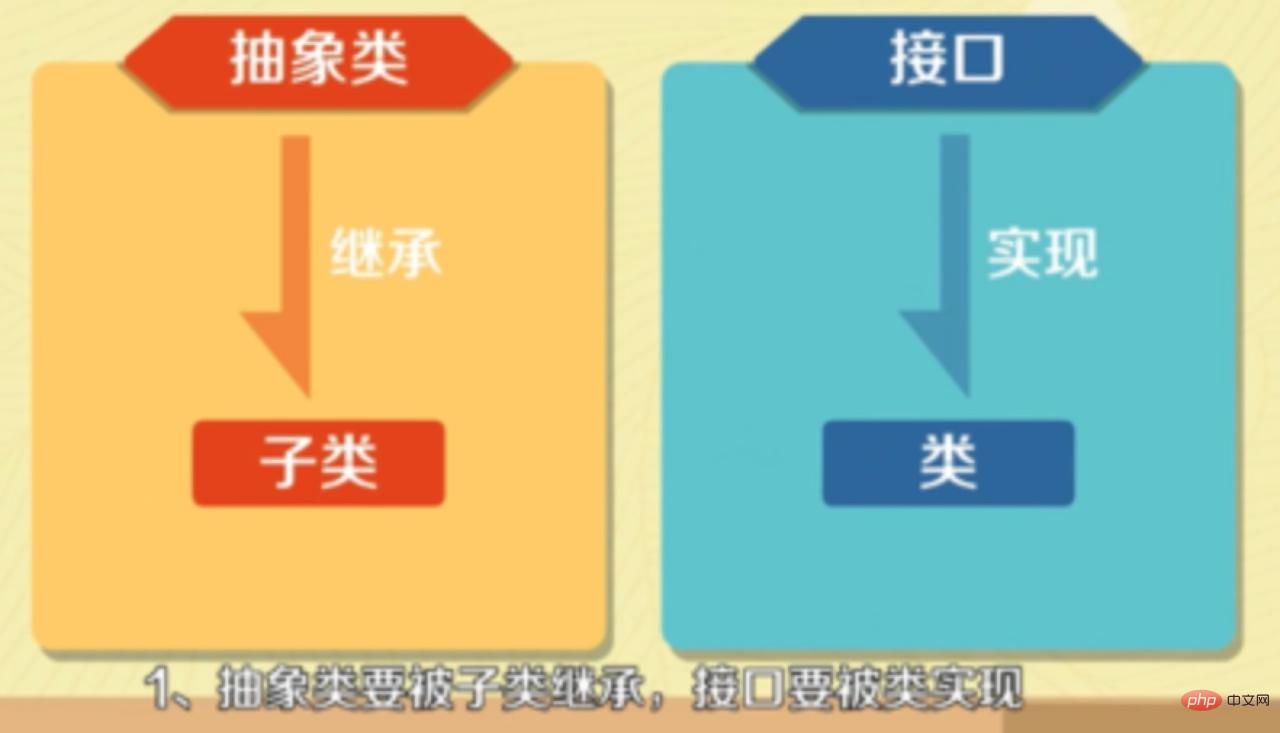
7. The difference between abstract classes and interfaces
- Abstract classes must be inherited by subclasses, and interfaces must be implemented by classes.

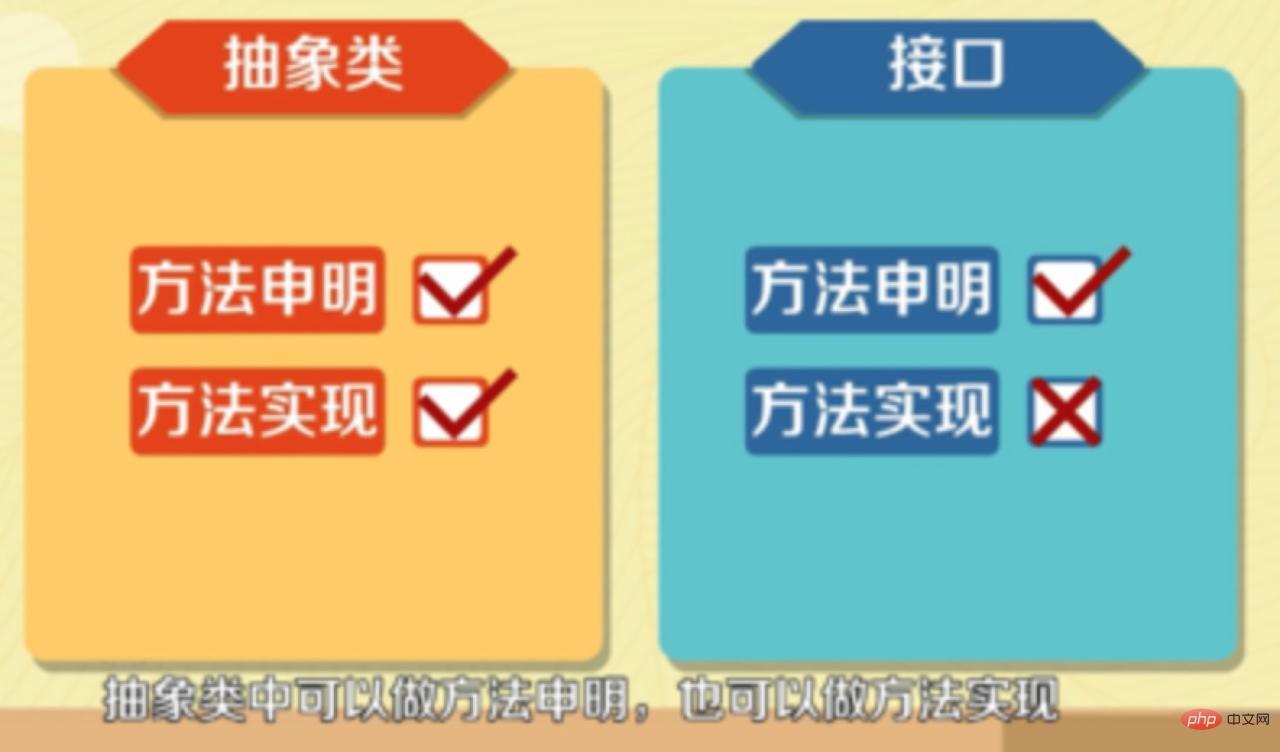
- Interfaces can only make method declarations, while abstract classes can make method declarations and method implementations.
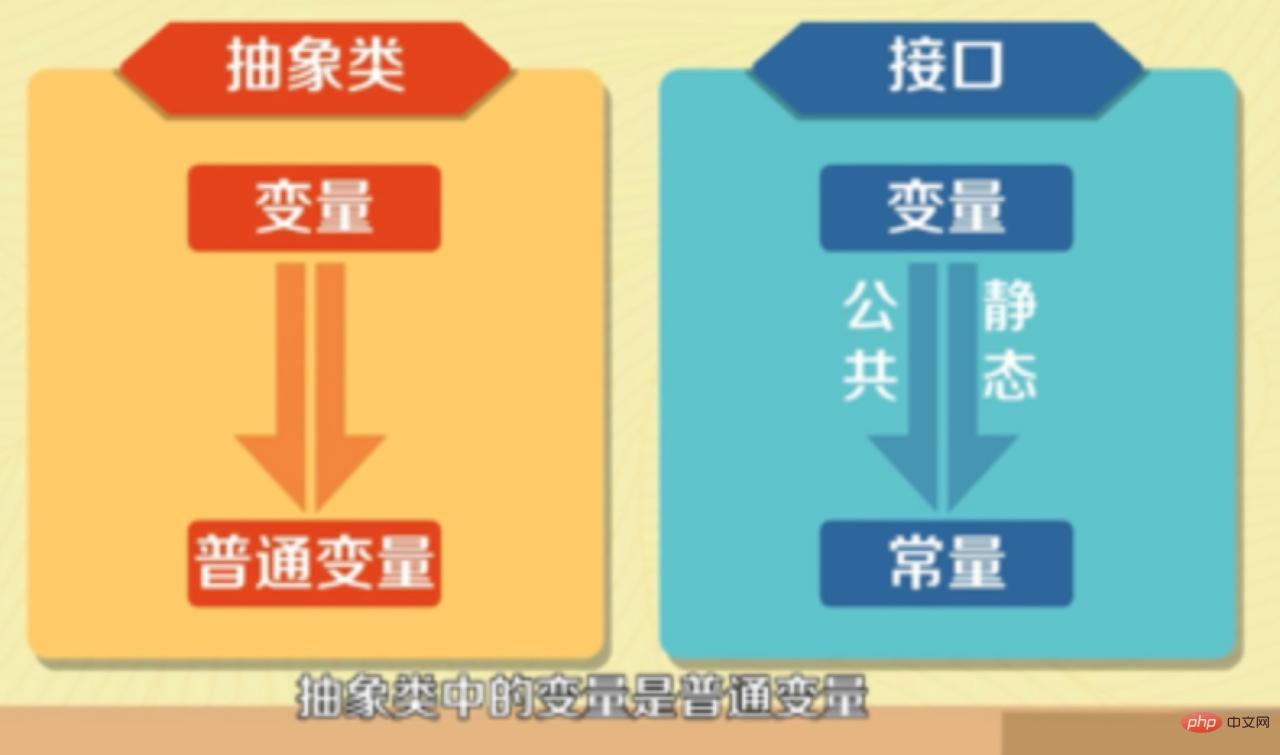
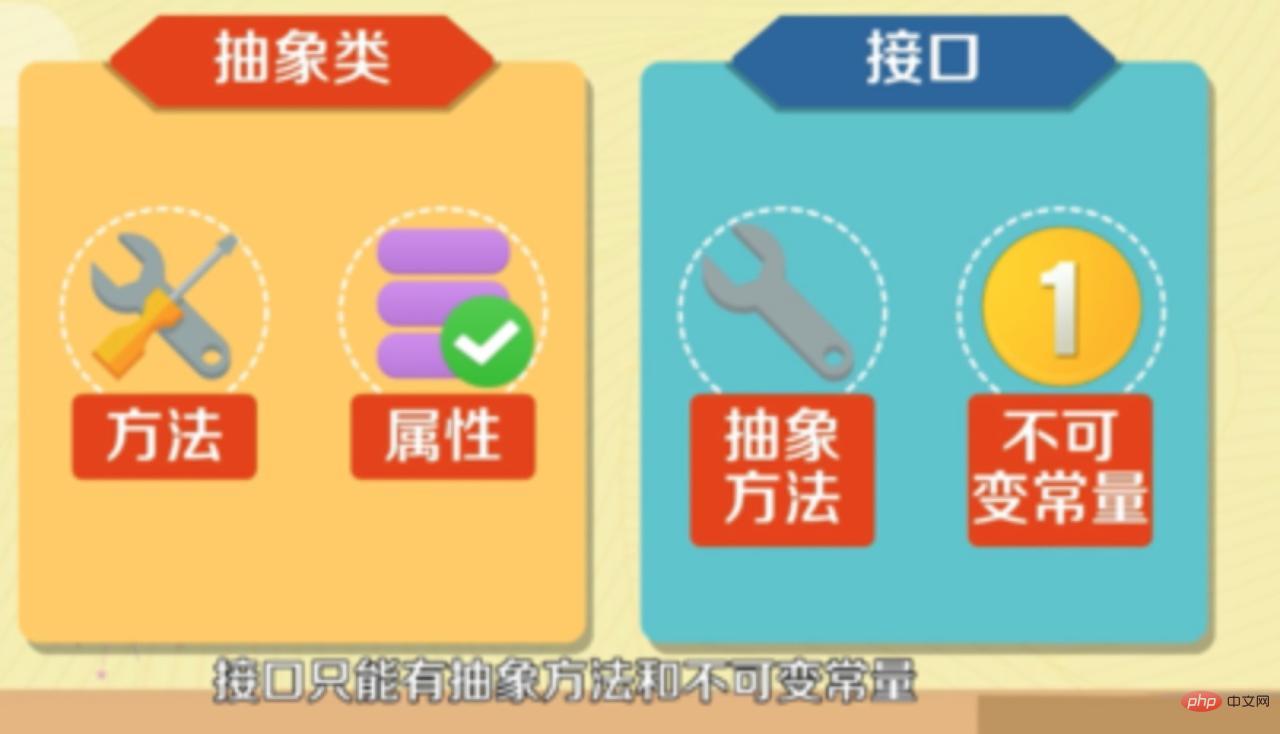
- The variables defined in the interface can only be public static constants, and the variables in the abstract class are ordinary variables.
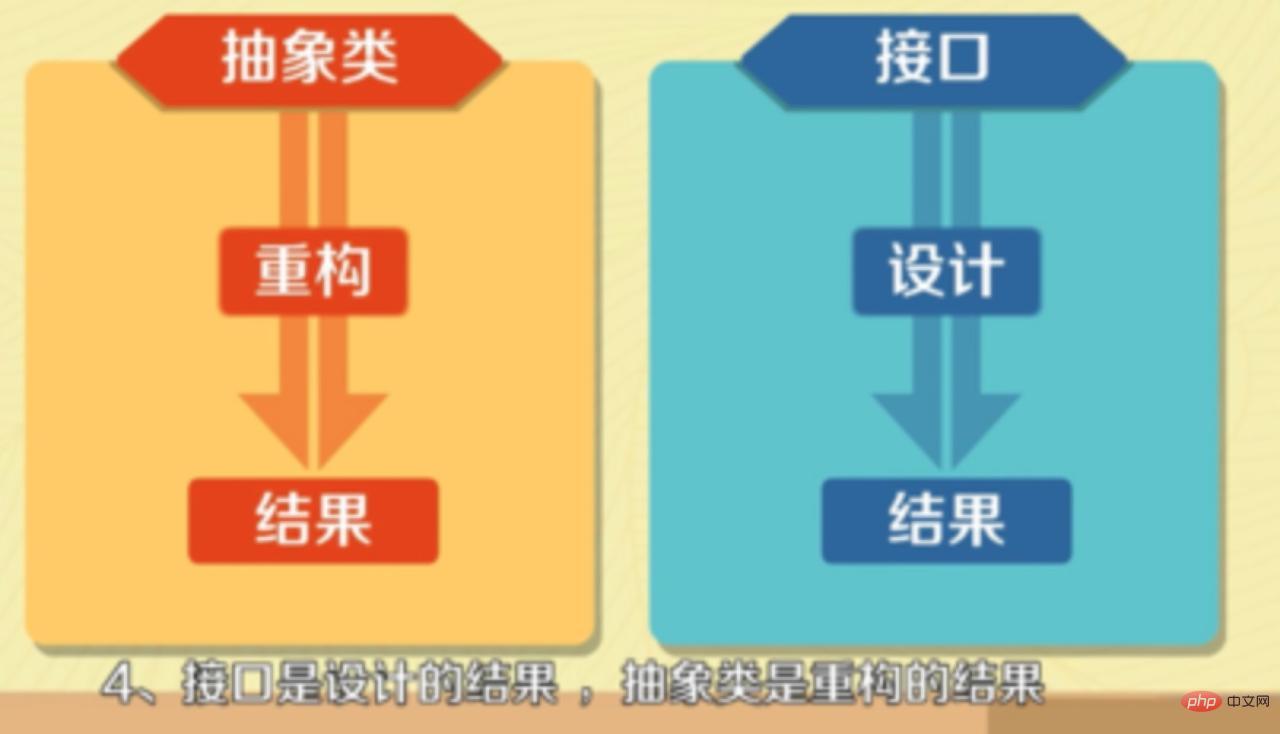
- Interface is the result of design, and abstract class is the result of refactoring.
- Abstract classes and interfaces are used to abstract specific objects, but interfaces have the highest abstraction level.
- Abstract classes can have specific methods and properties, while interfaces can only have abstract methods and immutable constants.
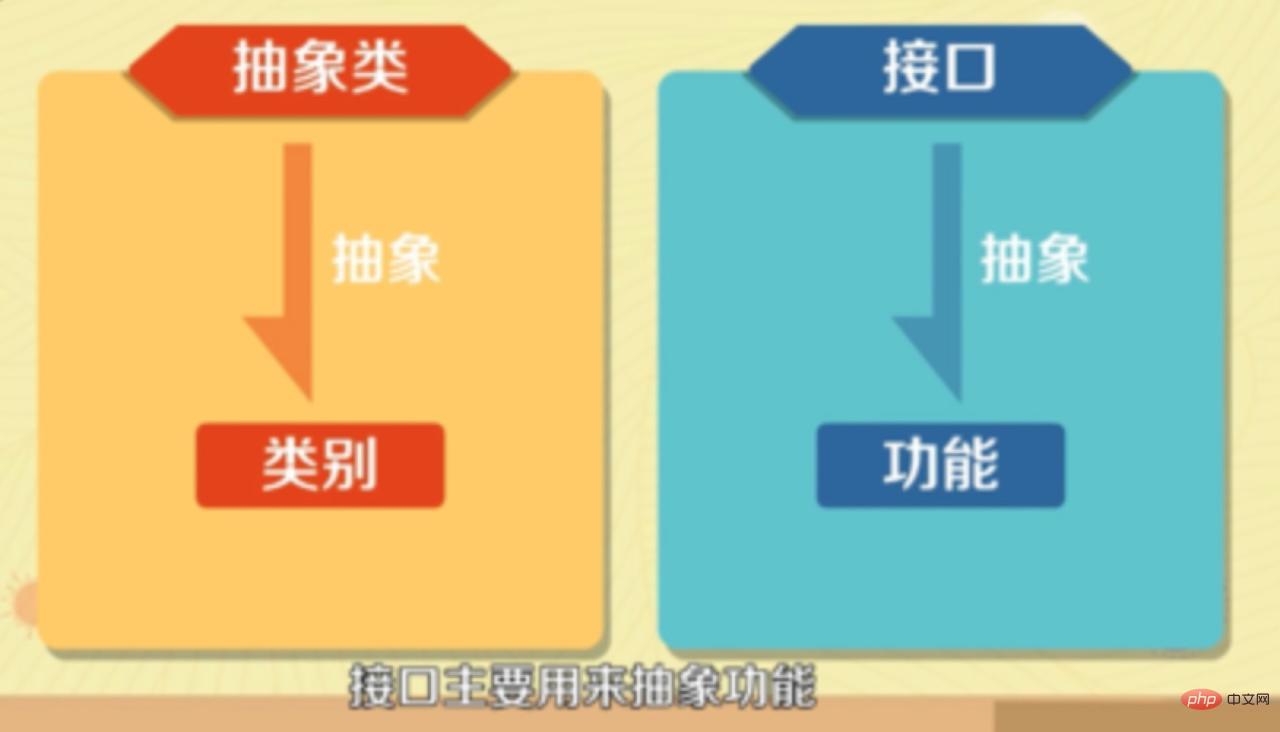
- Abstract classes are mainly used to abstract categories, and interfaces are mainly used to abstract functions.
8. The meaning of abstract class
Abstract class: If a class contains abstract methods, the class should be declared as an abstract class using the abstract keyword.
Meaning:
- Provides a public type for subclasses;
- encapsulates repeated content (member variables and methods) in subclasses ;
- defines an abstract method. Although subclasses have different implementations, the definition of this method is consistent.
9. Application scenarios of abstract classes and interfaces
1. Application scenarios of interfaces:
- Necessary specificity between classes interface, regardless of how it is implemented.
- Exists as an identifier that can implement a specific function, or it can be a pure identifier without any interface methods.
- It is necessary to treat a group of classes as a single class, and the caller only contacts this group of classes through the interface.
- Need to implement specific multiple functions, and these functions may have no connection at all.
2. Application occasions of abstract class (abstract.class):
In a word, when both a unified interface and instance variables or default methods are needed , you can use it. The most common ones are:
- defines a set of interfaces, but does not want to force each implementation class to implement all interfaces. You can use abstract.class to define a set of method bodies, or even empty method bodies, and then the subclass can choose the methods it is interested in to cover.
- In some cases, pure interfaces alone cannot satisfy the coordination between classes. Variables representing states in the class must also be used to distinguish different relationships. The intermediary role of abstract can satisfy this very well.
- Specifies a set of mutually coordinated methods, some of which are common, independent of state, and can be shared without the need for subclasses to implement them separately; while other methods require each subclass to implement it according to its own specific State to achieve specific functions
10. Can an abstract class have no methods and attributes?
The answer is: Yes
There can be no abstract methods in abstract classes, but those with abstract methods must be abstract classes. Therefore, there can be no abstract methods in abstract classes in Java. Note that even abstract classes without abstract methods and properties cannot be instantiated.
11. 接口的意义
- 定义接口的重要性:在Java编程,abstract class 和interface是支持抽象类定义的两种机制。正是由于这两种机制的存在,才使得Java成为面向对象的编程语言。
- 定义接口有利于代码的规范:对于一个大型项目而言,架构师往往会对一些主要的接口来进行定义,或者清理一些没有必要的接口。这样做的目的一方面是为了给开发人员一个清晰的指示,告诉他们哪些业务需要实现;同时也能防止由于开发人员随意命名而导致的命名不清晰和代码混乱,影响开发效率。
- 有利于对代码进行维护:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。可是在不久将来,你突然发现现有的类已经不能够满足需要,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
- 保证代码的安全和严密:一个好的程序一定符合高内聚低耦合的特征,那么实现低耦合,定义接口是一个很好的方法,能够让系统的功能较好地实现,而不涉及任何具体的实现细节。这样就比较安全、严密一些,这一思想一般在软件开发中较为常见。
12. Java泛型中的extends和super理解
在平时看源码的时候我们经常看到泛型,且经常会看到extends和super的使用,看过其他的文章里也有讲到上界通配符和下届通配符,总感觉讲的不够明白。这里备注一下,以免忘记。
- extends也成为上界通配符,就是指定上边界。即泛型中的类必须为当前类的子类或当前类。
- super也称为下届通配符,就是指定下边界。即泛型中的类必须为当前类或者其父类。
这两点不难理解,extends修饰的只能取,不能放,这是为什么呢? 先看一个列子:
public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List extends Fruit> list){
//报错,extends为上界通配符,只能取值,不能放.
//因为Fruit的子类不只有Apple还有Banana,这里不能确定具体的泛型到底是Apple还是Banana,所以放入任何一种类型都会报错
//list.add(new Apple());
//可以正常获取
Fruit fruit = list.get(1);
}
public void testSuper(List super Fruit> list){
//super为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲,
//无法确定Fruit的父类是否只有Food一个(Object是超级父类)
//因此放入Food的实例编译不通过
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}在testExtends方法中,因为泛型中用的是extends,在向list中存放元素的时候,我们并不能确定List中的元素的具体类型,即可能是Apple也可能是Banana。因此调用add方法时,不论传入new Apple()还是new Banana(),都会出现编译错误。
理解了extends之后,再看super就很容易理解了,即我们不能确定testSuper方法的参数中的泛型是Fruit的哪个父类,因此在调用get方法时只能返回Object类型。结合extends可见,在获取泛型元素时,使用extends获取到的是泛型中的上边界的类型(本例子中为Fruit),范围更小。
总结:在使用泛型时,存取元素时用super,获取元素时,用extends。
13. 父类的静态方法能否被子类重写
不能,父类的静态方法能够被子类继承,但是不能够被子类重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。
class Fruit{
static String color = "五颜六色";
static public void call() {
System.out.println("这是一个水果");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五颜六色
fruit.call(); //这是一个水果
}
}如代码所示,如果能够被重写,则输出的应该是这是一个香蕉。与此类似的是,静态变量也不能够被重写。如果想要调用父类的静态方法,应该使用类来调用。 那为什么会出现这种情况呢? 我们要从重写的定义来说:
重写指的是根据运行时对象的类型来决定调用哪个方法,而不是根据编译时的类型。
对于静态方法和静态变量来说,虽然在上述代码中使用对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。
静态属性和静态方法是否可以被继承
可以被继承,如果子类中有相同的静态方法和静态变量,那么父类的方法以及变量就会被覆盖。要想调用就就必须使用父类来调用。
class Fruit{
static String color = "五颜六色";
static String xingzhuang = "奇形怪状";
static public void call() {
System.out.println("这是一个水果");
}
static public void test() {
System.out.println("这是没有被子类覆盖的方法");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //这是没有被子类覆盖的方法
banana.call(); //调用Banana类中的call方法 这是一个香蕉
Fruit.call(); //调用Fruit类中的方法 这是一个水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪状 黄色
}
}从上述代码可以看出,子类中覆盖了父类的静态方法的话,调用的是子类的方法,这个时候要是还想调用父类的静态方法,应该是用父类直接调用。如果子类没有覆盖,则调用的是父类的方法。静态变量与此相似。
14. The difference between threads and processes
- Definition: A process is a running activity of a program on a certain data collection; a thread is an execution path in a process. (A process can create multiple threads)
- Role aspect: In a system that supports the thread mechanism, the process is the unit of system resource allocation, and the thread is the unit of CPU scheduling.
- Resource sharing: Resources cannot be shared between processes, but threads share the address space and other resources of the process in which they are located. At the same time, the thread also has its own stack, stack pointer, program counter and other registers.
- In terms of independence: The process has its own independent address space, but the thread does not. The thread must depend on the process to exist.
- In terms of overhead. Process switching is expensive. Threads are relatively small. (As mentioned before, the introduction of threads is also due to cost considerations.)
You can read this article: juejin.im/post/684490…
15. The difference between final, finally, and finalize
- final is used to declare properties, methods and classes, which respectively means that properties are immutable, methods cannot be overridden, and classes cannot be inherited.
- finally is exception handling Part of the statement structure, indicating that it is always executed.
- finalize is a method of the Object class. This method of the recycled object will be called when the garbage collector is executed. This method can be overridden to provide other functions during garbage collection. Resource recycling, such as closing files, etc.
16. The difference between serialization Serializable and Parcelable
If Intent in Android wants to transfer class objects, it can be achieved in two ways.
Method 1: Serializable, the class to be passed implements the Serializable interface to pass the object, Method 2: Parcelable, the class to be transferred implements the Parcelable interface to transfer the object.
Serializable (comes with Java): Serializable means serialization, which means converting an object into a storable or transmittable state. Serialized objects can be transmitted over the network or stored locally. Serializable is a tagged interface, which means that Java can efficiently serialize this object without implementing methods.
Parcelable (Android-specific): The original design intention of Android's Parcelable is because Serializable is too slow (using reflection), in order to facilitate communication between different components in the program and between different Android programs (AIDL) Designed to efficiently transfer data that only exists in memory. The implementation principle of the Parcelable method is to decompose a complete object, and each part after decomposition is a data type supported by Intent, thus realizing the function of passing the object.
Efficiency and selection:
The performance of Parcelable is better than that of Serializable, because the latter frequently GCs during the reflection process, so it is recommended to use Parcelable when transferring data between memories, such as transferring data between activities. Serializable can persist data for easy storage, so choose Serializable when you need to save or transmit data over the network. Because Parcelable may be different in different versions of Android, it is not recommended to use Parcelable for data persistence. Parcelable cannot be used when data is to be stored on disk, because Parcelable cannot guarantee the persistence of data when the outside world changes. Although Serializable is less efficient, it is still recommended to use Serializable at this time.
When passing complex data types through intent, one of the two interfaces must be implemented first. The corresponding methods are getSerializableExtra() and getParcelableExtra().
17. Can static properties and static methods be inherited? Can it be rewritten? And why?
The static properties and methods of the parent class can be inherited by the subclass
cannot be overridden by the subclass : When the reference of the parent class points to the subclass When using an object to call a static method or static variable, the method or variable in the parent class is called. It is not overridden by subclasses.
Reason:
Because the static method has allocated memory since the program started running, which means it has been hard-coded. All objects that reference this method (either objects of the parent class or objects of the subclass) point to the same piece of data in memory, which is the static method.
If a static method with the same name is defined in a subclass, it will not be overridden. Instead, another static method in the memory should be allocated to the subclass, and there is no such thing as rewriting.
18 The design intention of static inner classes in .java
Inner classes
Inner classes are classes defined inside a class. Why are there inner classes?
We know that in Java, classes are single inheritance, and a class can only inherit another concrete class or abstract class (which can implement multiple interfaces). The purpose of this design is that in multiple inheritance, when there are duplicate attributes or methods in multiple parent classes, the call results of the subclass will be ambiguous, so single inheritance is used.
The reason for using inner classes is that each inner class can independently inherit an (interface) implementation, so whether the outer class has inherited an (interface) implementation, it has no effect on the inner class.
In our programming, sometimes there are some problems that are difficult to solve using interfaces. At this time, we can use the ability provided by internal classes to inherit multiple concrete or abstract classes to solve these programs. Design issues. It can be said that interfaces only solve part of the problem, and inner classes make the solution of multiple inheritance more complete.
Static inner classes
Before talking about static inner classes, first understand the member inner classes (non-static inner classes).
Member inner class
Member inner class is also the most common inner class. It is a member of the outer class, so it can have unlimited access to all the outer classes. Although the member attributes and methods are private, if the outer class wants to access the member attributes and methods of the inner class, it needs to access it through the inner class instance.
Two points should be noted in the member inner class:
There cannot be any static variables and methods in the member inner class;
-
The member inner class is attached to the outer class, so the inner class can only be created after the outer class is created first.
Static inner class
There is one biggest difference between static inner classes and non-static inner classes: non-static inner classes are compiled after they are compiled A reference is then implicitly held to the outside world in which it was created, but the static inner class does not.
The absence of this reference means:
Its creation does not need to depend on the peripheral class.
It cannot use non-static member variables and methods of any peripheral class.
The other two internal classes: local internal classes and anonymous internal classes
Local internal classes
Local internal classes are Nested within methods and scopes, the use of this class is mainly to apply and solve more complex problems. We want to create a class to assist our solutions, but by then we do not want this class to be publicly available, so we A local inner class is generated. The local inner class is compiled like the member inner class, but its scope changes. It can only be used in this method and attribute, and it will become invalid when the method and attribute are removed.
Anonymous inner classes
Anonymous inner classes have no access modifiers.
new Anonymous inner class, this class must exist first.
When the formal parameter of the method needs to be used by the anonymous inner class, then the formal parameter must be final.
Anonymous inner classes have no explicit constructor, and the compiler will automatically generate a constructor that references the outer class.
Related recommendations:Getting started with java
The above is the detailed content of Summary of 2020 new Java basic interview questions. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
