

mysql tutorial column introduces related index knowledge today.

The second article in the MySQL series mainly discusses some issues about indexing in MySQL, including index types, data models, index execution processes, and the leftmost prefix principle , index failure and index pushdown, etc.
The first time I learned about indexes was in the database principles course of my sophomore year. When a query statement is very slow, you can improve query efficiency by adding indexes to certain fields.
There is another very classic example: we can think of the database as a dictionary and the index as a directory. When we use the directory of the dictionary to query a word, the role of the index can be reflected.
In MySQL, based on the logic or field characteristics of the index, the index is roughly divided into the following types: ordinary index, unique index, primary key index, union Indexes and prefix indexes.
There is another index classification distinguished from physical storage: clustered index and non-clustered index.
To put it simply, the so-called clustered index means that the index key and the data row are together, and the value corresponding to the index key of the non-clustered index is the value of the clustered index.
Common data structures used to implement indexes include hash tables, ordered arrays and search trees.
A hash table is a container that stores data in the form of key-value. Like HashMap, a hash index will also calculate the key through a specific hash function. Get the index value, and then store the value corresponding to the key in the corresponding position of the array. If there are two keys with the same index value calculated by the hash function (a hash conflict occurs), then this position in the array will become a linked list. Store all values with the same hash value.
So in general, the time complexity of equivalent query in hash table can reach O(1), but in the case of hash conflict, all values in the linked list need to be traversed additionally. Only then can we find data that meets the conditions.
In addition, considering that the index calculated by the hash function is irregular - the hash table hopes that all keys can be fully hashed, so that the keys can be evenly distributed without wasting space - that is The keys of the hash table are non-sequential, so using the hash table for interval query is very slow. The same is true for sorting.
So, hash tables are only suitable for equivalent queries.
As the name suggests, an ordered array is an array arranged in the order of keys. Its time complexity for equivalent queries can reach O(logN) using binary queries. This is inferior to a hash table.
But range query through ordered array is more efficient: first find the minimum value (or maximum value) through binary query, and then traverse in reverse until another boundary.
As for sorting, ordered arrays are inherently ordered and naturally sorted. Of course, the sorting field is not an index field, so let’s talk about it separately.
But the ordered array has a disadvantage. Since the array elements are continuous and ordered, if a new data row is inserted at this time, in order to maintain the orderliness of the ordered array, it needs to be larger than the element key. All elements are moved back one unit to make room for them to be inserted. And the cost of this way of maintaining indexes is very high.
So, ordered arrays are suitable for storing data that will no longer be updated after clothes are initialized.
Those who know the data structure should know that the search tree is a query time complexity of O(logN), and the update time complexity is also O(logN) data structure. Therefore, compared with hash tables and ordered arrays, search trees take into account both query and update aspects. It is for this reason that the most commonly used data model in MySQL is the search tree.
Considering that the index is stored on the disk, if the search tree is a binary tree, then it can only have two left and right child nodes. When there is a lot of data comparison, the binary tree The high value may be very high. When MySQL performs a query, the tree height may cause excessive disk I/O times and slow down the query efficiency.
In addition, there is a full-text index, which solves the problem of determining whether a field is included by establishing an inverted index.
The inverted index is used to store the mapping of the storage location of a word in a document or a group of documents under full-text search. Through the inverted index, you can quickly obtain a list of documents containing this word based on the word.
When searching by keywords, full-text indexing will come in handy.
This is a relatively simple B-tree.
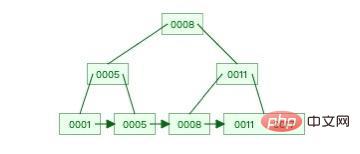
Image source: Data Structure Visualizations
You can also see from the above example picture that the bottom of this B tree The leaf nodes store all the elements and are stored in order, while the non-leaf nodes only store the value of the index column.
In InnoDB, the index model based on BTree is the most commonly used. Here is a practical example to illustrate the structure of BTree index in InnoDB.
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(36) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `nameIndex`(`name`) USING BTREE ) ENGINE = InnoDB;-- 插入数据insert into user1(id,name,age) values (1,'one',21),(2,'two',22),(3,'three',23),(4,'four',24),(5,'five',25);复制代码
There are only two fields in this table: the primary key id and the name field, and a BTree index with the name field as the index column is established.
An index based on the primary key id field is also called a primary key index. Its index tree structure is: the non-leaf stage of the index tree stores the value of the primary key id, and the value stored in the leaf node isThe entire data row corresponding to the primary key id, as shown in the following figure:
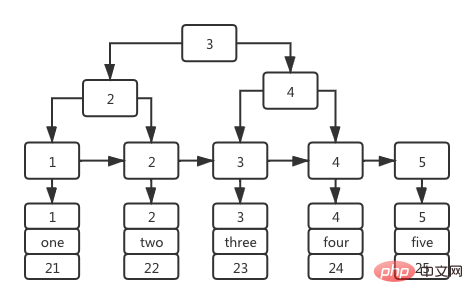
It is precisely because the leaf nodes of the primary key index store the corresponding primary key id The entire data row, the primary key index is also called a clustered index.
In the index tree with the name field as the column, the non-leaf nodes also store the value of the index column, and the value stored in the leaf stage is the value of the primary key id, as shown in the figure below Show.
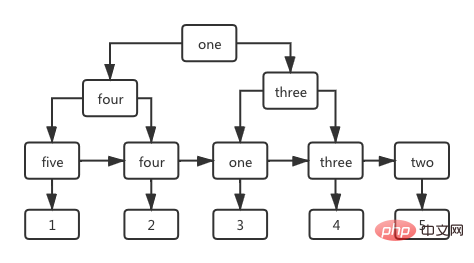
First look at the following SQL sentence to query the data row with id=1 in the user table.
select * from user where id=1;复制代码
The execution process of this SQL is very simple. The storage engine will go through the index tree of the primary key id. When it finds id=1, it will return the data row with id=1 on the index tree (due to the primary key The value is unique, so if a hit target is found, the search will stop and the result set will be returned directly).
Next, let’s look at the query using an ordinary index. Its situation is slightly different from the primary key index.
select * from user where name='one';复制代码
The process of the above SQL query statement is as follows: First, the storage engine will search the index tree of the ordinary index name column. When a record with name equal to one is hit, the storage engine needs to go through a very important step. :Return to table.
Since the sub-nodes of the index tree of ordinary indexes store primary key values, when the query statement needs to query other fields except the primary key id and index columns, it needs to return to the primary key index based on the value of the primary key id. Query in the tree to get the entire data row corresponding to the primary key id, and then add the row to the result set after obtaining the fields required by the client.
Then the storage engine will continue to search the index tree until it encounters the first record that does not satisfy name='one', and will finally return all hit records to the client. .
We call the process of querying the entire data row in the primary key index based on the primary key id value queried from the ordinary index as table return.
When the amount of data is very large, table return is a very time-consuming process, so we should try to avoid table return, which leads to the next question: use covering indexes to avoid table return.
I don’t know if you have noticed that there is such a description in the previous table return question: "When the query statement needs to query the primary key id and index column "Other fields other than..." In this scenario, you need to obtain other query fields by returning the table. In other words, if the query statement only needs to query the fields of the primary key id and index column, is there no need to return the table?
Let’s analyze this process. First, create a joint index.
alter table user add index name_age ('name','age');复制代码Then the structure diagram of this index tree should be as follows:

The order of the child nodes of the joint index index tree is according to the fields when the index is declared. To sort, it is similar to order by name, age, and the value corresponding to its index is the primary key value like a normal index.
select name,age from user where name='one';复制代码
上面这条 SQL 是查询所有 name='one' 记录的 name 和 age 字段,理想的执行计划应该是搜索刚刚建立的联合索引。
与普通索引一样,存储引擎会搜索联合索引,由于联合索引的顺序是先按照 name 再按照 age 进行排序的,所以当找到第一个 name 不是 one 的索引时,才会停止搜索。
而由于 SQL 语句查询的只是 name 和 age 字段,恰好存储引擎命中查询条件时得到的数据正是 name, age 和 id 字段,已经包含了客户端需要的字段了,所以就不需要再回表了。
我们把只需要在一棵索引树上就可以得到查询语句所需要的所有字段的索引成为覆盖索引,覆盖索引无须进行回表操作,速度会更快一些,所以我们在进行 SQL 优化时可以考虑使用覆盖索引来优化。
上面所举的例子都是使用索引的情况,事实上在项目中复杂的查询语句中,也可能存在不使用索引的情况。首先我们要知道,MySQL 在执行 SQL 语句的时候一张表只会选择一棵索引树进行搜索,所以一般在建立索引时需要尽可能覆盖所有的查询条件,建立联合索引。
而对于联合索引,MySQL 会遵循最左前缀原则:查询条件与联合索引的最左列或最左连续多列一致,那么就可以使用该索引。
为了详细说明最左前缀原则,同时说明最左前缀原则的一些特殊情况。
即便我们根据最左前缀的原则创建了联合索引,还是会有一些特殊的场景会导致索引失效,下面举例说明。
假设有一张 table 表,它有一个联合索引,索引列为 a,b,c 这三个字段,这三个字段的长度均为10。
CREATE TABLE `demo` ( `a` varchar(1) DEFAULT NULL, `b` varchar(1) DEFAULT NULL, `c` varchar(1) DEFAULT NULL, INDEX `abc_index`(`a`, `b`, `c`) USING BTREE ) ENGINE = InnoDB;复制代码
第一种情况是查询条件与索引字段全部一致,并且用的是等值查询,如:
select * from demo where a='1' and b='1' and c='1';select * from demo where c='1' and a='1' and b='1';复制代码
输出上述两条 SQL 的执行计划来看它们使用索引的情况。
mysql> explain select * from demo where a='1' and b='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where c='1' and a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)复制代码
第一条 SQL 很显然能够用到联合索引。
从执行计划中可以看到,第二条 SQL 与第一条 SQL 使用的索引以及索引长度是一致的,都是使用 abc_index 索引,索引长度为 18 个字节。
按理说查询条件与索引的顺序不一致,应该不会用到索引,但是由于 MySQL 有优化器存在,它会把第二条 SQL 优化成第一条 SQL 的样子,所以第二条 SQL 也使用到了联合索引 abc_index。
综上所述,全字段匹配且为等值查询的情况下,查询条件的顺序不一致也能使用到联合索引。
第二种情况是查询条件与索引字段部分保持一致,这里就需要遵循最左前缀的原则,如:
select * from demo where a='1' and b='1';select * from demo where a='1' and c='1';复制代码
上述的两条查询语句分别对应三个索引字段只用到两个字段的情况,它们的执行计划是:
mysql> explain select * from demo where a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 12 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where a='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 6 | const | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从它们的执行计划可以看到,这两条查询语句都使用到了 abc_index 索引,不同的是,它们使用到索引的长度分别是:12、6 字节。
在这里需要额外提一下索引长度的计算方式,对于本例中声明为 varchar(1) 类型的 a 字段,它的索引长度= 1 * (3) + 1 + 2 = 6。
所以这两条查询语句使用索引的情况是:
由此可见:最左前缀原则要求,查询条件必须是从索引最左列开始的连续几列。
第三种情况是查询条件用的是范围查询(,!=,=,between,like)时,如:
select * from demo where a='1' and b!='1' and c='1';复制代码
这两条查询语句的执行计划是:
mysql> EXPLAIN select * from demo where a='1' and b!='1' and c='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 12 | NULL | 2 | 10.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从执行计划可以看到,第一条 SQL 使用了联合索引,且索引长度为 12 字节,即用到了 a,b 两个字段;第二条 SQL 也使用了联合索引,索引长度为 6 字节,仅使用了联合索引中的 a 字段。
综上所述,在全字段匹配且为范围查询的情况下,也能使用联合索引,但只能使用到联合索引中第一个出现范围查询条件的字段。
需要注意的是:
第四种情况是查询条件中带有函数或特殊表达式的,比如:
select * from demo where id + 1 = 2;select * from demo where concat(a, '1') = '11';复制代码
可能由于数据的原因(空表),我输出的执行计划是使用了联合索引的,但是事实上,在查询条件中,等式不等式左侧的字段包含表达式或函数时,该字段是不会用到索引的。
至于原因,是因为使用函数或表达式的情况下,索引字段本身的值已不具备有序性。
上文中已经罗列了联合索引的实际结构、最左前缀原则以及索引失效的场景,这里再说一下索引下推这个重要的优化规则。
select * from demo where a > '1' and b='1'; mysql> explain select * from demo where a > '1' and b='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 6 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)复制代码
上面这条查询语句,从它的执行计划也可以看出,它使用的索引长度为 6 个字节,只用到了第一个字段。
所以 MySQL 在查询过程中,只会对第一个字段 a 进行 a > '1' 的条件判断,当满足条件后,存储引擎并不会进行 b=1 的判断, 而是通过回表拿到整个数据行之后再进行判断。
这好像很蠢,就算索引只用到了第一个字段,但明明索引树中就有 b 字段的数据,为什么不直接进行判断呢?
听上去好像是个 bug,其实在未使用索引下推之前整个查询逻辑是:由存储引擎检索索引树,就算索引树中存在 b 字段的值,但由于这条查询语句的执行计划使用了联合索引但没有用到 b 字段,所以也无法进行 b 字段的条件判断,当存储引擎拿到满足条件(a>'1')的数据后,再由 MySQL 服务器进行条件判断。
在 MySQL5.6 版本中对这样的情况进行优化,引入索引下推技术:在搜索索引树的过程中,就算没能用到联合索引的其他字段,也能优先对查询条件中包含且索引也包含的字段进行判断,减少回表次数,提高查询效率。
在使用索引下推优化之后,b 字段作为联合索引列,又存在于查询条件中,同时又没有在搜索索引树时被使用到,MySQL 服务器会把查询条件中关于 b 字段的部分也传给存储引擎,存储引擎会在搜索索引树命中数据之后再进行 b 字段查询条件的判断,满足的才会加入结果集。
Ps: 执行计划中 Extra 字段的值包含 Using index condition 就代表使用到了索引下推。
更多相关免费学习推荐:mysql教程(视频)
The above is the detailed content of My understanding of MySQL Part 2: Index. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



