
The following column will introduce to you Redis tutorialAnalysis of redis principle and implementation, I hope it will be helpful to friends who need it Helped!
redis is nosql (also a huge map) single-threaded, but can handle 100,000 concurrency in 1 second (data is all in memory)
Using java to operate redis is similar to the jdbc interface standard for mysql. There are various implementation classes that implement it. The one we commonly use is druid
For redis, we usually use Jedis (it also provides us with a connection pool JedisPool)
In redis, key is byte[](string)
redis data structure (value):
String,list,set,orderset,hash
First install redis, then run it, introduce dependencies in the pom file, and configure the fully qualified name of redis in the mapper.xml file of the class to be cached by redis. Introduce the redis.properties file of redis (you can use it if you want to change the configuration)
Application scenario:
String:
1Storage json type objects, 2Counters, 3Youku video likes, etc.
list (double linked list)
1 You can use redis's list to simulate queues, heaps, and stacks
2 Likes in the circle of friends (a content statement in the circle of friends, several like statements)
Provisions :The format of the content in the circle of friends:
1, content: user:x:post:x content to store;
2, likes: post:x:good list to store; (put The corresponding avatar is taken out and displayed)
hash(hashmap)
1 Save the object
2 Grouping
3 The data difference between string and hash
During network transmission, serialization must be carried out before network transmission can be carried out. Then when using the string type, related serialization is required, and hashing is also required. Related serialization, so there will be a lot of serialization. When storing, hash can be stored more abundantly, but when deserializing, the deserialization of string is relatively low, and the serialization and deserialization of hash are relatively low. It is more complex than the hash class, so depending on the business scenario, if the data is frequently modified, you can use string for performance. If the data is not frequently changed, you can use hash. Because hash is richer in storing data, Can store a variety of data types
4 Redis persistence method:
can write the data in the memory to the hard disk asynchronously, two methods : RDB (default) and AOF
RDB persistence principle: Triggered by the bgsave command, then the parent process performs a fork operation to create a child process, the child process creates an RDB file, and generates a temporary snapshot file based on the memory of the parent process. After completion Atomic replacement of the original file (scheduled one-time snapshot of all data to generate a copy and store it on the hard disk)
Advantages: It is a compact and compressed binary file. Redis loads RDB to restore data much faster than AOF way.
Disadvantages: Due to the large overhead of generating RDB each time, non-real-time persistence,
AOF persistence principle: After turning on, Redis will add this command every time it executes a command to modify data. into the AOF file.
Advantages: Real-time persistence.
Disadvantages: Therefore, the size of the AOF file gradually increases, and regular rewriting operations are required to reduce the file size and slow loading.
5 Why is redis single thread so fast?
Redis is single-threaded, but why is it still so fast?
Reason 1: Single-threaded to avoid competition between threads
Reason 2: It is in memory Yes, using memory can reduce disk io
Reason 3: The multiplexing model uses the concept of buffer and the selector model
redis provides sentinel mode. When the master hangs up, you can elect others to replace it. The implementation principle of sentinel mode is to monitor three scheduled tasks,
6.1 Every 10s, each The S node (sentinel node) will send the info command to the master node and the slave node to obtain the latest topology structure
6.2 Every 2s, each S node will send the S node’s judgment of the master node to a certain channel. As well as the information of the current Sl node,
At the same time, each Sentinel node will also subscribe to this channel to learn about other S nodes and their judgment of the master node (as an objective basis for offline)
6.3 Every 1s, each S node will send a ping command to the master node, slave node, and other S nodes for a heartbeat detection (heartbeat detection mechanism) to confirm whether these nodes are currently reachable
After three heartbeat detections, a vote will be held. When more than half of the votes are received, the node will be regarded as the master
The redis cluster provides ruby after 3.0 The script is built and the concept of roughness is introduced,
The nodes in the Redis cluster realize node communication through ping/pong messages. The messages can not only propagate node slot information, but also propagate other states such as master-slave status, node failure, etc. Therefore, fault discovery is also realized through the message propagation mechanism. The main links include: subjective offline (pfail) and objective offline (fail)
Subjective and objective offline:
Subjective offline: each person in the cluster Nodes regularly send ping messages to other nodes, and the receiving nodes reply with pong messages in response. If communication continues to fail, the sending node will mark the receiving node as subjectively offline (pfail).
Objective offline: More than half, the master node will be objectively offline
The master node elects a certain master node as the leader for failover.
Failover (elect the slave node as the new master node)
Redis’s memory elimination strategy refers to the cache used in Redis When there is insufficient memory, how to handle data that needs to be newly written and requires additional space application.
noeviction: When the memory is insufficient to accommodate the newly written data, the new write operation will report an error.
allkeys-lru: When the memory is insufficient to accommodate newly written data, in the key space, remove the least recently used key.
allkeys-random: When the memory is insufficient to accommodate newly written data, a key is randomly removed from the key space.
volatile-lru: When the memory is insufficient to accommodate newly written data, in the key space with an expiration time set, remove the least recently used key.
volatile-random: When the memory is insufficient to accommodate newly written data, a key is randomly removed from the key space with an expiration time set.
volatile-ttl: When the memory is insufficient to accommodate newly written data, in the key space with an expiration time set, keys with an earlier expiration time will be removed first. 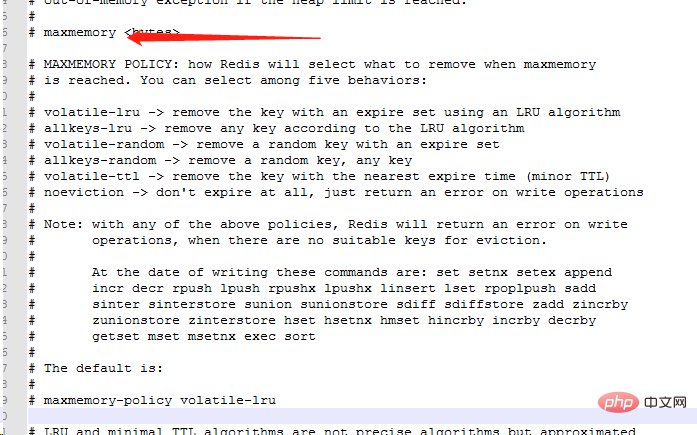
Reason: When others request data, a lot of data cannot be queried in the cache, so directly enter the data query,
The solution is to only query the cache when querying related data. If it is some special data, you can query the database.
You can also use Bloom filters to query
Cause of cache avalanche: too much data is added to the cache at one time, causing the memory to be too high, which affects memory usage and leads to service downtime
Solution:
1 redis cluster, placing data through clustering
2 Back-end service degradation and current limiting: When an interface is requested too many times, too much data will be added, and the service can be Limit the flow and limit the number of accesses, so as to reduce the occurrence of problems
The above is the detailed content of Analyze redis principle and implementation. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



