


正则表达式应用的场景也非常多。常见的比如:搜索引擎的搜索、爬虫结果的匹配、文本数据的提取等等都会用到,所以掌握甚至精通正则表达式是一个硬性技能,非常必要。
正则表达式是一个特殊的字符序列,由普通字符和元字符组成。元字符能帮助你方便的检查一个字符串是否与某种模式匹配。
Python中则提供了强大的正则表达式处理模块,即 re 模块, 为Python的内置模块。
下面,我带大家来一个入门demo例子,代码如下:
import rereg_string = "hello9527python@wangcai.@!:xiaoqiang" reg = "hello"result = re.findall(reg,reg_string) print(result)复制代码
这里reg_string就是我们的普通字符,reg就是我们的元字符。
我们使用 re 模块中的findall函数,进行匹配,返回的结果是列表数据类型。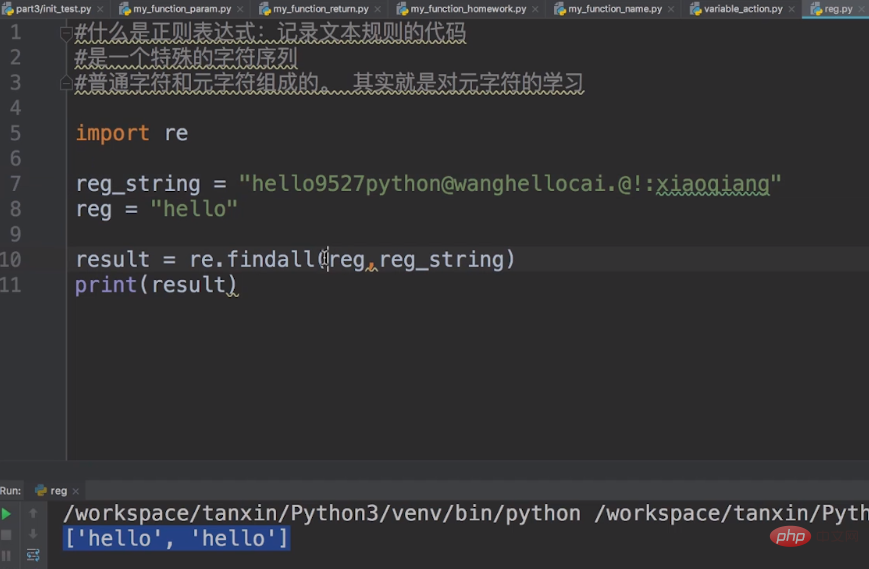
我们使用正则表达式,就是为了在很长的字符串中,找到我们需要的字符串片段。
Python中常见元字符及其含义如下:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \\\\w | 匹配数字字母下划线汉字 |
| \\\\s | 匹配任意空白符 |
| \\\\d | 匹配所有的数字 |
| \\\\b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的开始结束 |
| 下面,我们具体使用下Python中的常见的元字符。 |
我们还是使用上次的例子,这次我们需要在reg_string匹配出我们的数字,只需要将reg换成\\\\d,代码如下图所示。
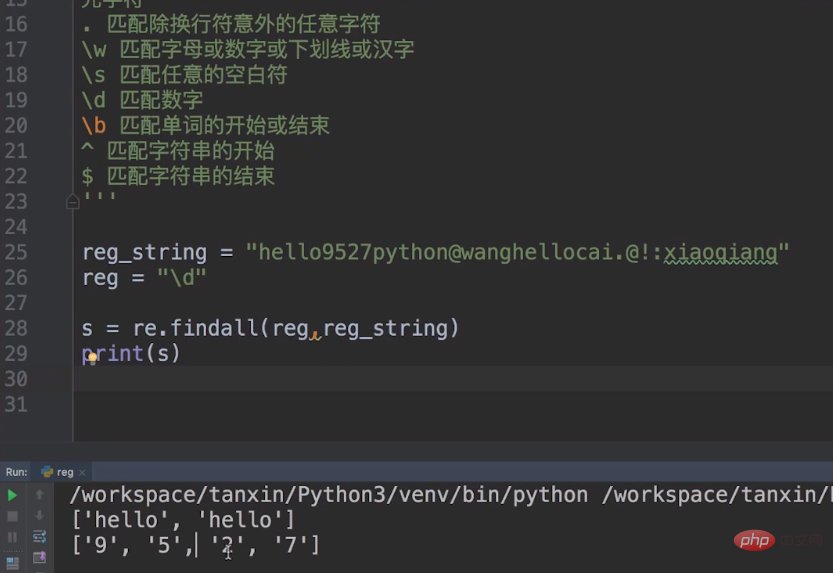 比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
如果,我们把reg换成\\\\w,代码如下图所示。
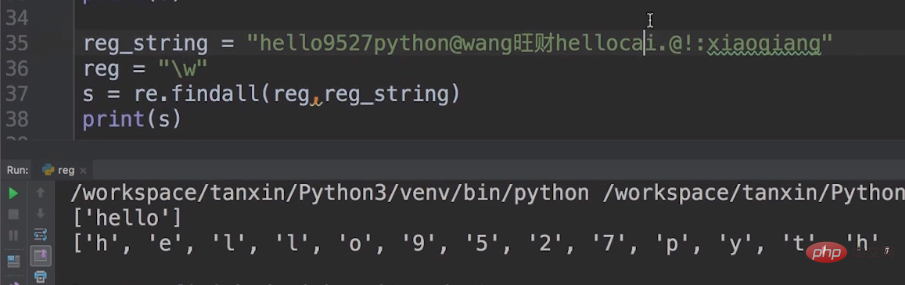
这样就是匹配数字字母下划线,包括我们的汉字。
Python中常见反义代码 及其含义如下:
| 反义代码 | 含义 |
|---|---|
| \\\\W | 匹配任意不是数字字母下划线汉字的字符 |
| \\\\S | 匹配任意不是空白符的字符 |
| \\\\D | 匹配非数字 |
| \\\\B | 匹配不是单词的开始或结束 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abcd] | 匹配除了abcd以外的任意字符 |
其实,记忆很简单,我们是不是知道\\\\d匹配数字,那么\\\\d的大写\\\\D就是匹配非数字,元字符[a]匹配a任意字符,那么[^a]就是匹配除了a以外的任意字符。
下面是具体例子
>>> import re>>> reg_string = "hello9527python@wangcai.@!:xiaoqiang" >>> reg = "\\\\D">>> re.findall(reg,reg_string) ['h', 'e', 'l', 'l', 'o', 'p', 'y', 't', 'h', 'o', 'n', '@', 'w', 'a', 'n', 'g', 'c', 'a', 'i', '.', '@', '!', ':', 'x', 'i', 'a', 'o', 'q', 'i', 'a', 'n', 'g'] >>> reg = "[^a-p]"['9', '5', '2', '7', 'y', 't', '@', 'w', '.', '@', '!', ':', 'x', 'q']复制代码
什么是限定符?就是限定我们匹配的个数的东西。
Python中常见限定符 及其含义如下:
| 限定符 | 含义 |
|---|---|
| * | 重复零次或多次 |
| + | 重复一次或多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n次到m次 {1,3} |
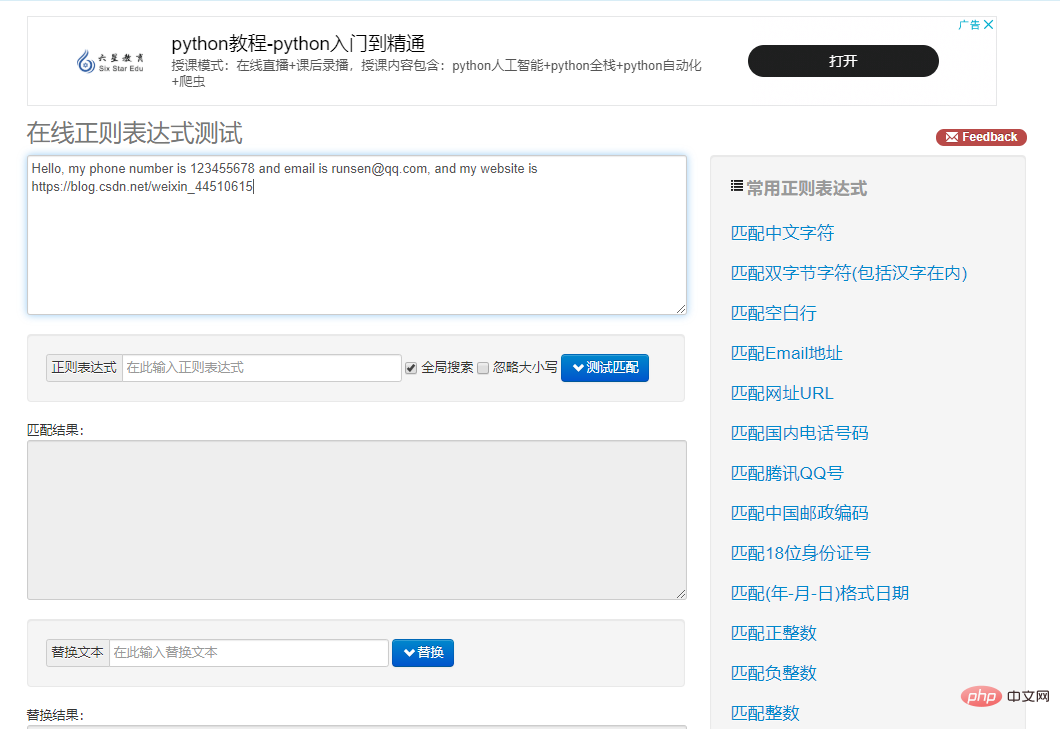
We still use our previous reg_string. This time we limit the metacharacter to \\\\d{4}, which means that our matching numbers must be 4.
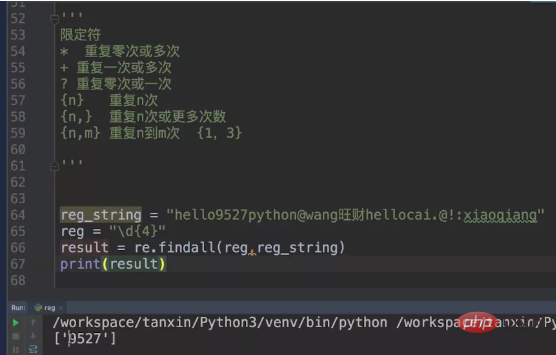
Next, let’s increase the difficulty and match letters and numbers, limiting the number to 4.
In this way we can use [0-9a-z]{4} as our metacharacter, [0-9a-z] represents the ten numbers from 0 to 9 and the lowercase 26 from a to z English letters. [0-9a-z]{4} limits the number to 4.
Let’s print the output.
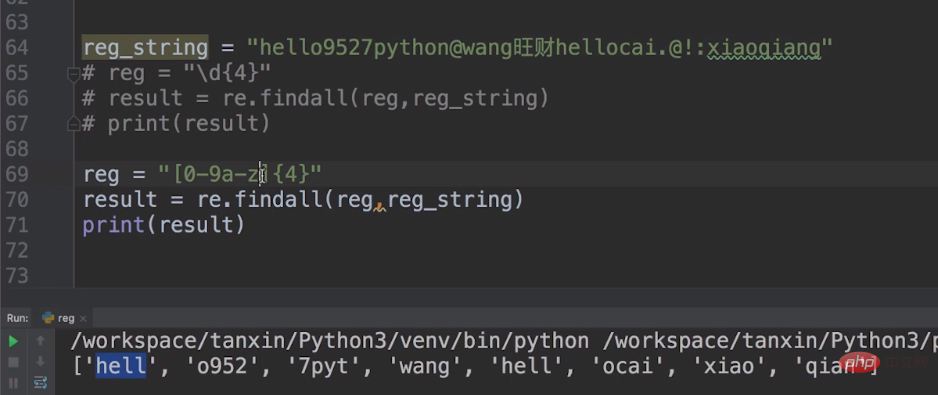
If it is not in the range of [0-9a-z], it will be skipped until the next 4 are in [0-9a-z] Print the output within the range.
In the Internet, a host has only one IP address. The IP address is used to mark the address of each computer in the TCP/IP communication protocol. It is usually expressed in decimal notation, such as 192.168.1.100.
In the window system, we can check our IP through ipconfig. In Linux systems, we can view our IP through ifconfig.
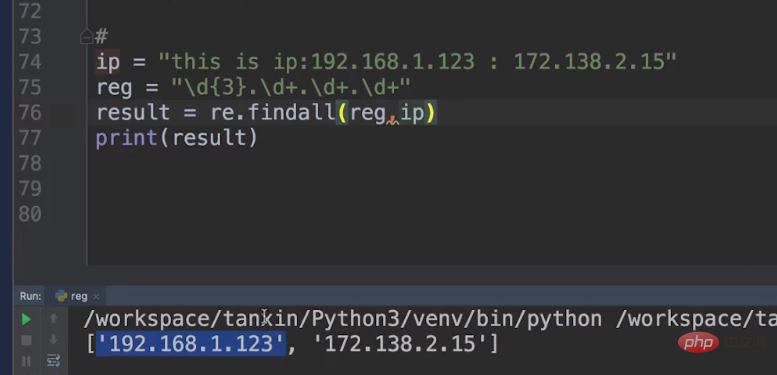
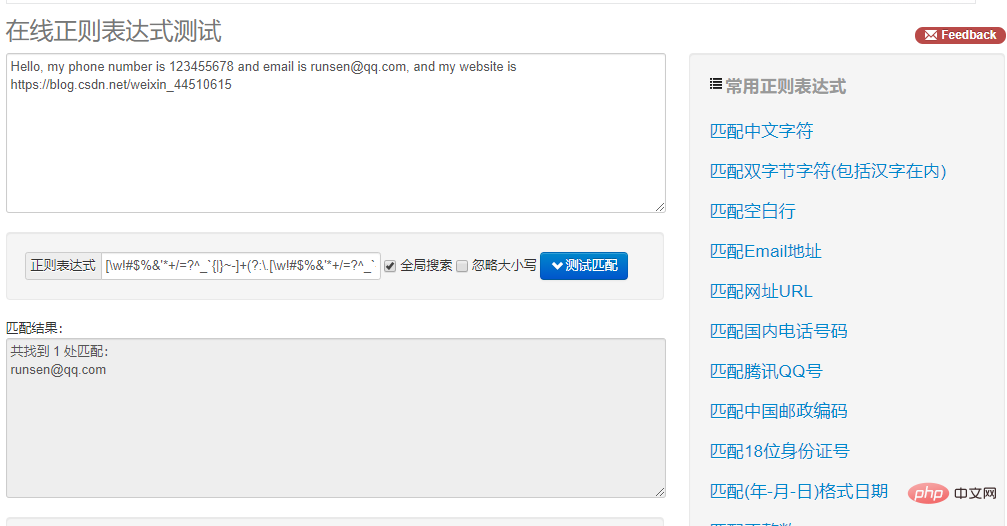
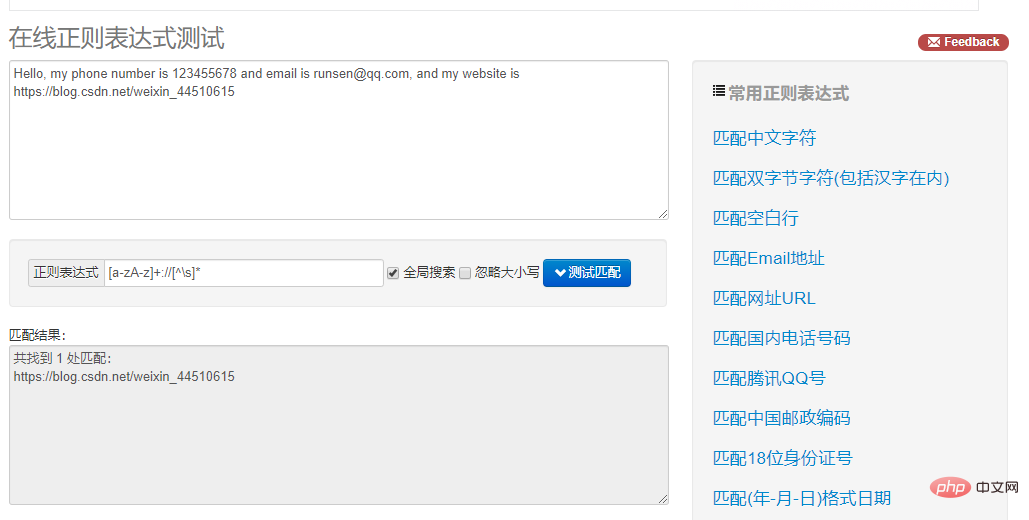
Our ip string looks like this: ip = "this is ip:192.168.1.123 :172.138.2.15"
The following requires the use of regular expressions, Match the ip.
In fact, we mainly write metacharacters. For example: reg = "\\\\d{3}.\\\\d .\\\\d .\\\\d ", because the first number must start with three digits , we can set \\\\d{3} to fix it.
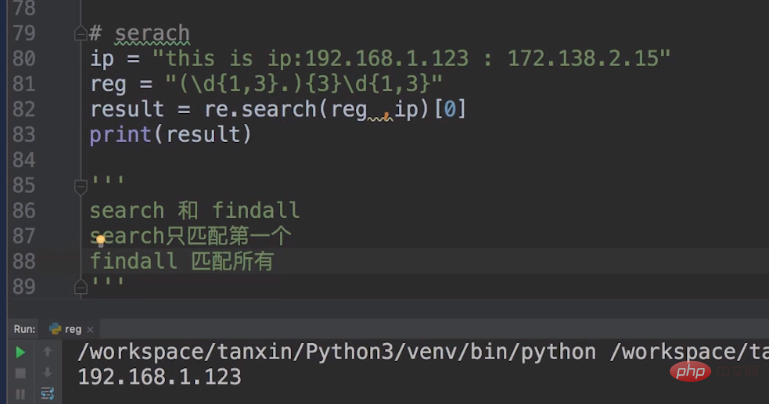
 In addition to using findall, we can also use search. We put the metacharacter
In addition to using findall, we can also use search. We put the metacharacter reg = "(\\\\d{1,3}.){3}\\\\ d{1,3}".
The \\\\d{1,3} in this metacharacter specifies the first three digits of our IP, and adding {3} after it is repeated. 3 times. \\\\d{1,3} refers to the last number of our IP.
But there is a difference between search and findall. Search can only match the first one. We need to use the list to remove the first one, while findall matches all.
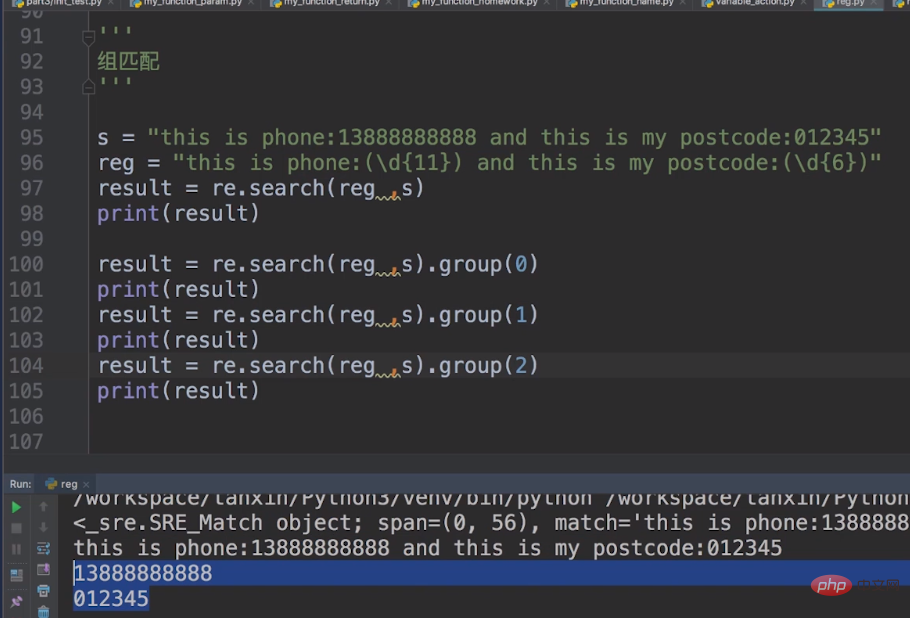
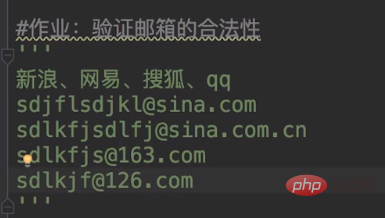
What is group matching? For example, I have a string heres = this is phone:13888888888 and this is my postcode:012345, I need you to match your mobile phone number with the verification code.
Because we need to match two, and the metacharacters of each are different. So, we need group matching.
The brackets in the regular expression indicate group matching, and the pattern in the brackets can be used to match the content of the group.
So our metacharacters become: reg = this is phone:(\\\\d{11}) and this is my postcode:(\\\\d{6})
We generally use search for group matching. Last time I said that search needs to be taken out using a list. The same is true for group matching here, but here group()method. group(1) represents our mobile phone number, group(2) represents our verification code, and group(0) represents our mobile phone number number and verification code. The code is as shown in the picture below.
In regular expressions, in addition to findall and search usage, there is also a match usage.
The match usage only matches the beginning, and it also needs to be taken out by group(). The following is an example of match.
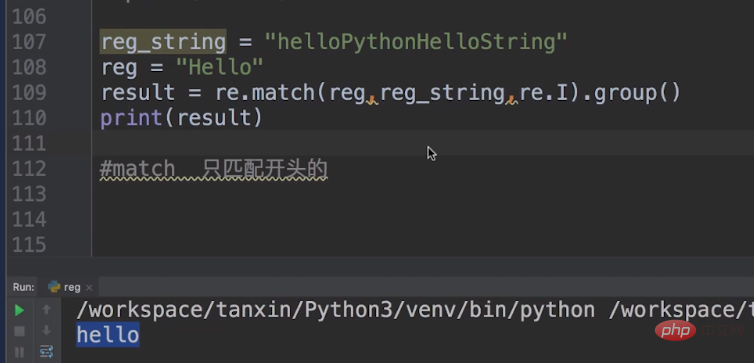 This is re.I means ignoring case.
This is re.I means ignoring case.
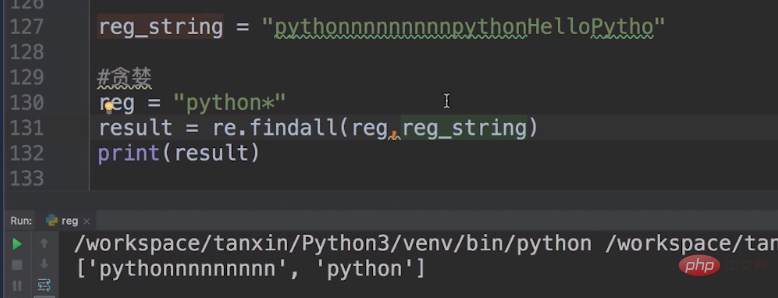
The greedy and non-greedy modes affect the matching behavior of sub-expressions modified by quantifiers. The greedy mode will match as many times as possible under the premise that the entire expression is successfully matched. The non-greedy mode matches as little as possible on the premise that the entire expression matches successfully.
There are several very important operators for greedy and non-greedy.
| Operator | Meaning |
|---|---|
| Duplicate Zero or more times | |
| repeated one or more times | |
| Repeat zero or once |
The above is the detailed content of Detailed explanation of regular expressions in Python. For more information, please follow other related articles on the PHP Chinese website!

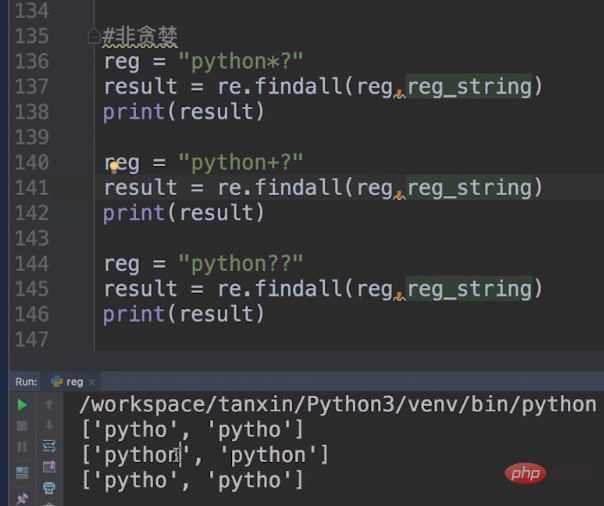 非贪婪模式下的
非贪婪模式下的
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



