
 Database
Mysql Tutorial
Understand the paging query after tens of billions of data are divided into tables
Database
Mysql Tutorial
Understand the paging query after tens of billions of data are divided into tables
Understand the paging query after tens of billions of data are divided into tables

mysql video tutorial column introduces paging query of tens of billions of data.

#When the business scale reaches a certain scale, Taobao’s daily order volume is more than 50 million orders, and Meituan’s daily order volume is more than 30 million orders. When the database is faced with massive data pressure, sub-database and table sub-operation are necessary. After the database is divided into tables, some regular queries may cause problems. The most common ones are paging queries. Generally, we call the fields of sharding tables as shardingkey. For example, the order table uses user ID as shardingkey. So how to do paging if the query condition does not include user ID? For example, how can more multi-dimensional queries be queried if there is no sharding key?
Unique Primary Key
Generally, the primary keys of our database are auto-incremented, so the problem of primary key conflict after splitting the table is an unavoidable problem. The simplest way is to use a unique business The field serves as the only primary key. For example, the order number of the order table must be globally unique.
There are many common distributed ways to generate unique IDs, the most common ones are Snowflake algorithm, Didi Tinyid, and Meituan Leaf. Taking the snowflake algorithm as an example, multiple IDs can be generated in one millisecond.
The first bitis not used, the default is 0, 41 digit timestamp is accurate to milliseconds, can accommodate 69 years, 10 digits work The high 5 digits of the machine ID are the data center ID, the low 5 digits are the node ID, 12-digit serial number Each node accumulates every millisecond, and the total can reach 2^12 4096 IDs.
 Partitioning
Partitioning
The first step is to ensure that the order number is unique after dividing the table. Now consider the issue of dividing the table. First, consider the size of the sub-table based on its own business volume and increment.
For example, our daily order volume is now 100,000 orders, and it is estimated that it will reach 1 million orders per day in one year. According to business attributes, we generally support querying orders within half a year, and orders that exceed half a year. Archiving is required.
So based on the order of 1 million orders per day for half a year, without separate tables, our order volume will reach 1 million , even if you can handle RT's time, you simply can't accept it. According to experience, there is no pressure on the database if the number of a single table is in the millions, so it is enough to divide it into 256 tables, 180 million/256 ≈ 700,000. If you are on the safe side, you can also divide it into 512 tables. Then think about it, if the business volume increases another 10 times to 10 million orders per day, sub-table 1024 is a more suitable choice.
After splitting tables and archiving data for more than half a year, 700,000 data in a single table is enough to cope with most scenarios. Next, hash the order number, and then take the modulo of 256 to determine which table it falls on.
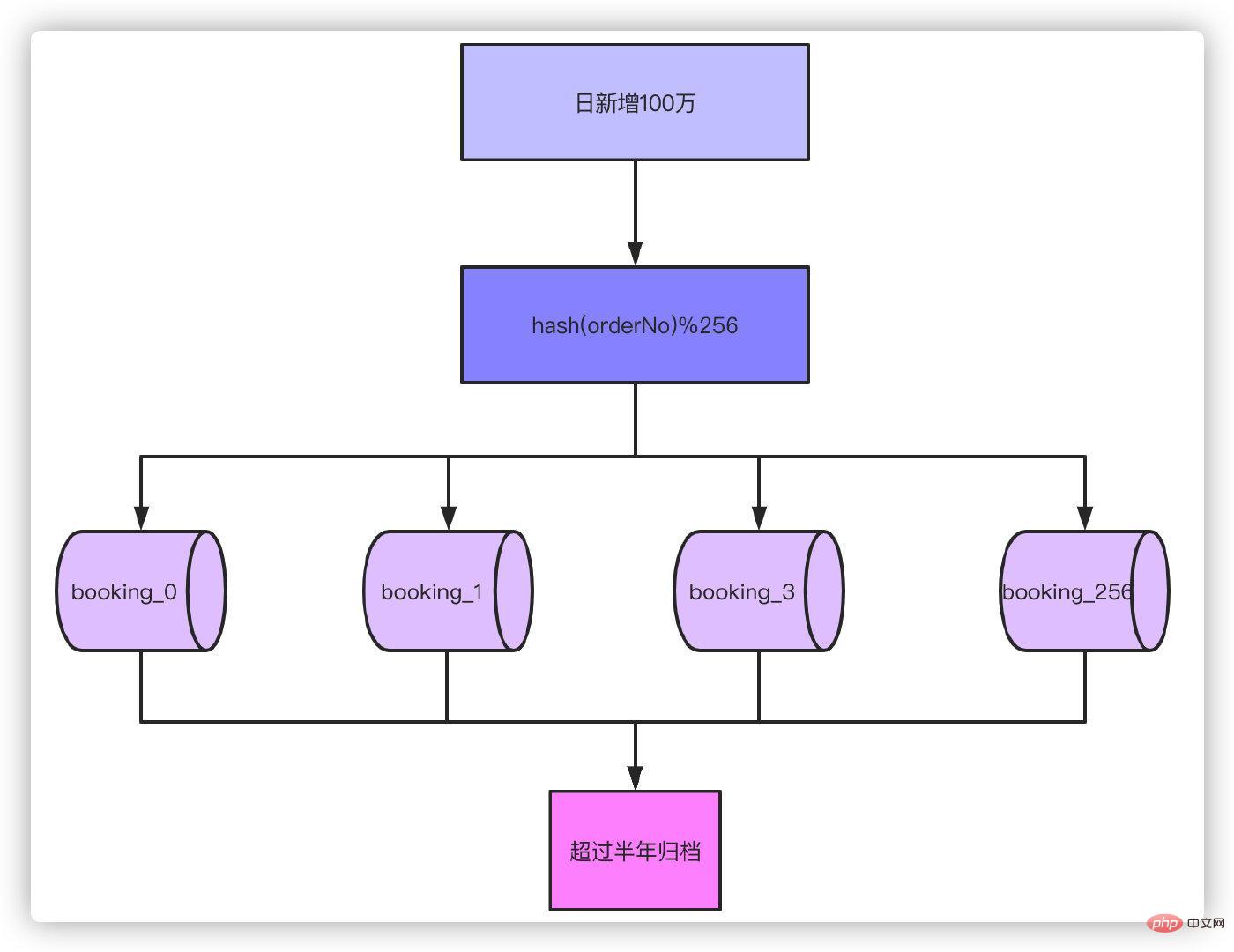 Well, because the only primary key is based on the order number, the queries you wrote based on the primary key ID in the past cannot be used. This involves some history. Modifications to query functionality. But this is not a problem, right? Just change it to check by the order number. None of this is a problem, the problem is what our title says.
Well, because the only primary key is based on the order number, the queries you wrote based on the primary key ID in the past cannot be used. This involves some history. Modifications to query functionality. But this is not a problem, right? Just change it to check by the order number. None of this is a problem, the problem is what our title says.
C-side query
After talking for a long time, I finally got to the point. So how to solve the problems of query and paging query after table partitioning?
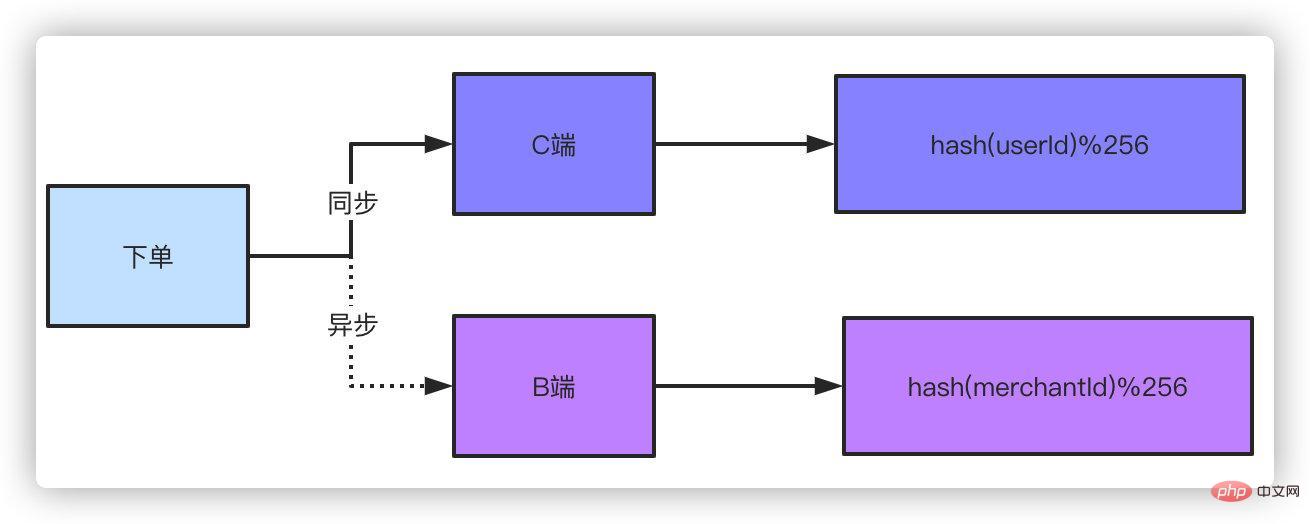
First of all, let’s talk about the query with sharding key. For example, query by order number. No matter what you do, you can directly locate the specific table for query. Obviously, there will be no problem with the query.
If it is not the sharding key, if the order number is used as the sharding key in the example above, APPs and small programs are generally queried through the user ID. So what should we do with the sharding done through the order number? Many companies' order tables directly use the user ID as the sharding key, which is very simple and can be checked directly. So what to do with the order number? A very simple way is to add the user ID attribute to the order number. To give a very simple example, you think you can’t use up the original 41-digit timestamp. The user ID is 10 digits. The order number generation rule contains the user ID. When entering the specific table, the 10-digit user ID hash in the order number is used. Take the modulus so that the query effect is the same regardless of the order number or user ID.
Of course, this method is just an example. The specific order number generation rules, how many digits, and what factors are included are determined according to your own business and implementation mechanism.
Okay, then whether you use the order number or user ID as the sharding key, you can solve the problem by following the above two methods. Then there is another question: What should I do if it is neither an order number nor a user ID query? The most intuitive example is the query from the merchant side or the backend. The merchant side uses the ID of the merchant or seller as the query condition. The query conditions in the background may be more complicated, like some background query conditions I encountered. There could be dozens of them. How to check? ? ? Don't worry, let's talk about the complex queries on the B-side and the backend separately.
In reality, most of the real traffic comes from the user-side C-side, so it essentially solves the problem on the user-side. This problem is mostly solved, and the rest comes from the merchant-seller-side B-side and the backend support operation business. The query traffic is not very large, so this problem is easy to solve.
Other side query
There are two ways to solve the non-shardingkey query on the B side.
Double writing. Double writing means that the order data is stored in two copies. The C side and the B side each save one copy. For C side, you can use the order number and user ID as the sharding key. OK, the B-side can just use the merchant's seller's ID as the sharding key. Some classmates will say, will it not affect performance if you double-write? Because a slight delay is acceptable for the B-side, an asynchronous method can be used to place the B-side order. Think about it, if you go to Taobao to buy something and place an order, does it matter if the seller delays receiving the order message for a second or two? Does it have any big impact on the takeaway merchant you ordered to receive the order a second or two late?
This is a solution. Another solution is to use the offline data warehouse or ES query. After the order data is dropped into the database, whether you use binlog or MQ messages are all in the form of synchronizing data to a data warehouse or ES. The order of magnitude they support is very simple for this kind of query conditions. There is definitely a slight delay in this method, but this controllable delay is acceptable.
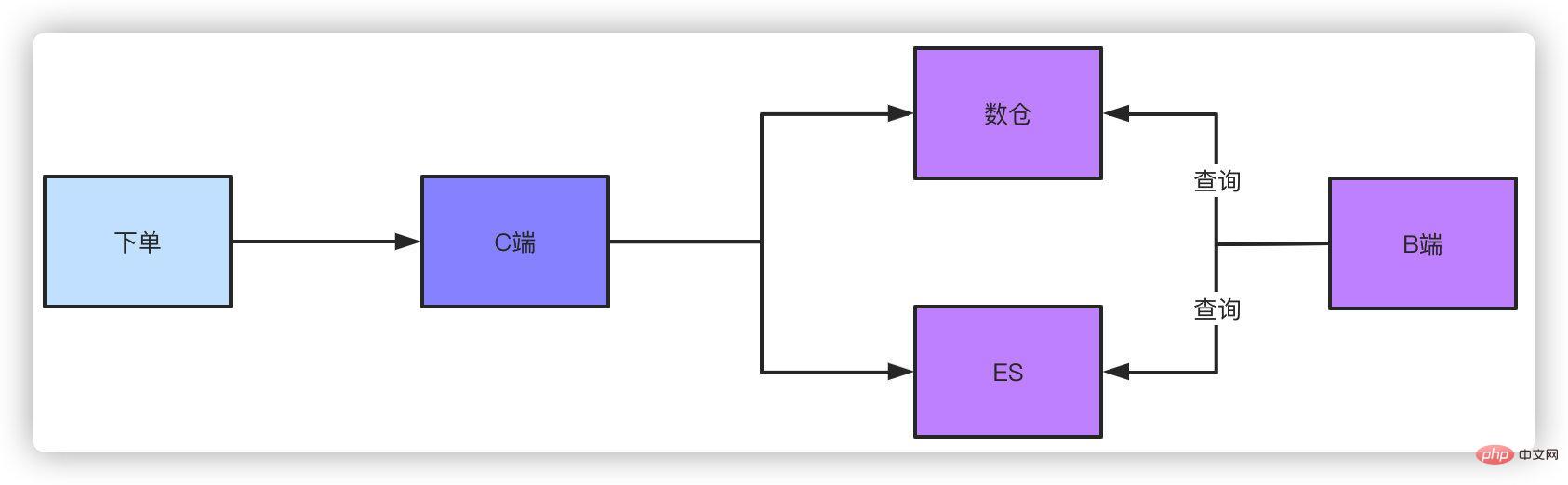
For queries on the management backend, such as operations, business, and products that need to look at data, they naturally require complex query conditions, which can also be done through ES or data warehouse. . If you don't use this solution and do paging query without shardingkey, brother, you can only scan the entire table to query the aggregated data, and then do paging manually, but the results found in this way are limited.
For example, if you have 256 shards, when querying, you scan all shards cyclically, fetch 20 pieces of data from each shard, and finally aggregate the data and manually page it, it will be impossible to find the full amount of data.
Summary
The query problem after database and table partitioning is actually known to experienced students, but I believe that most students may not have done the business yet. At this order of magnitude, sub-databases and tables may still be in the conceptual stage. After being asked about it in the interview, I feel at a loss because I don’t know what to do because I have no experience.
Sub-database and sub-table are first judged based on the existing business volume and future increment. For example, if Pinduoduo has a daily order volume of 50 million, the data in half a year must be in the tens of billions. That’s all The score is 4096 tables, right? But the actual operation is the same. For your business, it is not necessary to score 4096. Make a reasonable choice based on the business.
We can easily solve queries based on shardingkey. Querying on non-shardingkey can be solved by dropping double copies of data, data warehouse, and ES. Of course, if the amount of data after splitting is small, , it is not a problem to build the index and scan the entire table to query.
Related free learning recommendations: mysql video tutorial
The above is the detailed content of Understand the paging query after tens of billions of data are divided into tables. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to use PHP database connection to implement paging query
Sep 08, 2023 pm 02:28 PM
How to use PHP database connection to implement paging query
Sep 08, 2023 pm 02:28 PM
How to use PHP database connection to implement paging query. When developing web applications, it often involves the need to query the database and perform paging display. As a commonly used server-side scripting language, PHP has powerful database connection functions and can easily implement paging queries. This article will introduce in detail how to use PHP database connection to implement paging query, and attach corresponding code examples. Prepare the database Before we start, we need to prepare a database containing the data to be queried. Here we take the MySQL database as an example,
 PHP and PDO: How to perform paging queries and display data
Jul 29, 2023 pm 04:10 PM
PHP and PDO: How to perform paging queries and display data
Jul 29, 2023 pm 04:10 PM
PHP and PDO: How to query and display data in pages When developing web applications, querying and displaying data in pages is a very common requirement. Through paging, we can display a certain amount of data at a time, improving page loading speed and user experience. In PHP, the functions of paging query and display of data can be easily realized using the PHP Data Object (PDO) library. This article will introduce how to use PDO in PHP to query and display data by page, and provide corresponding code examples. 1. Create database and data tables
 How to create high-performance MySQL data paging queries using Go language
Jun 17, 2023 am 09:09 AM
How to create high-performance MySQL data paging queries using Go language
Jun 17, 2023 am 09:09 AM
With the rapid development of the Internet, data processing has become an important skill in enterprise application development. MySQL database is often one of the most commonly used data stores in many applications. In MySQL, data paging query is a common data retrieval operation. This article will introduce how to use Go language to implement high-performance MySQL data paging query. 1. What is data paging query? Data paging query is a commonly used data retrieval technology, which allows users to browse only a small amount of data on a page without loading it all at once.
 Paging query skills for PHP and Oracle database
Jul 11, 2023 pm 11:09 PM
Paging query skills for PHP and Oracle database
Jul 11, 2023 pm 11:09 PM
Paging query techniques for PHP and Oracle database When developing a dynamic web page, if you need to display a large amount of data, you need to perform paging query. Paginated query is a technique that divides data into smaller pages so that users can browse and navigate easily. In this article, we will discuss how to implement paginated queries using PHP and Oracle database, and provide relevant code examples. 1. Preparation Before starting, we need to make sure that we have installed and configured PHP and Oracle database. If still
 How to use Mysql for paging query in ThinkPHP6
Jun 20, 2023 pm 02:01 PM
How to use Mysql for paging query in ThinkPHP6
Jun 20, 2023 pm 02:01 PM
With the rapid development of the Internet, the development of web applications is becoming more and more complex. And paging query is one of the common functions in web applications. ThinkPHP6 is a web framework that helps developers develop applications quickly. In this article, we will discuss how to perform paginated queries using MySQL in ThinkPHP6. First, we need to create the database in ThinkPHP6. The statement to create a database in MySQL is as follows: CREATEDATABASE
 How to use MongoDB with PHP for paginated query
Jul 07, 2023 pm 09:28 PM
How to use MongoDB with PHP for paginated query
Jul 07, 2023 pm 09:28 PM
Overview of how PHP uses MongoDB for paginated queries: MongoDB is a non-relational database often used to store large amounts of document data, while PHP is a popular server-side scripting language. In this article, we will introduce how to use PHP to connect to MongoDB and implement paging query function. Step 1: Install the MongoDB extension. To interact with MongoDB in PHP, you need to install the MongoDB extension. The MongoDB extension can be installed with the following command: p
 MySql paging query: How to deal with performance issues of paging in large databases
Jun 15, 2023 pm 03:28 PM
MySql paging query: How to deal with performance issues of paging in large databases
Jun 15, 2023 pm 03:28 PM
In modern applications, most data needs to be displayed in pages. When applications need to process large amounts of data, this puts pressure on servers and databases, causing queries to take longer. Mysql is currently one of the most popular relational databases. This article will discuss how to optimize the performance of Mysql paging queries. Principle of paging Before starting optimization, we must first understand the principle of paging. The main principle of paging query is to divide the table data into several pages, and then query the data one by one. For example, if we need to
 How to use thinkorm to easily implement paging query function
Jul 31, 2023 pm 10:41 PM
How to use thinkorm to easily implement paging query function
Jul 31, 2023 pm 10:41 PM
Overview of how to use thinkorm to easily implement paging query function: When developing a website or application, it is often necessary to perform paging query on the data in the database in order to display part of the data on the page and provide page turning function. This article will introduce how to use the thinkorm framework to easily implement the paging query function, and provide relevant code examples. Step 1: Install thinkorm First, you need to install the thinkorm framework in the project. You can use the following command to install it: composerrequi
