mysql tutorial column introduces the life cycle of sql in relational databases.

MYSQL Query Processing
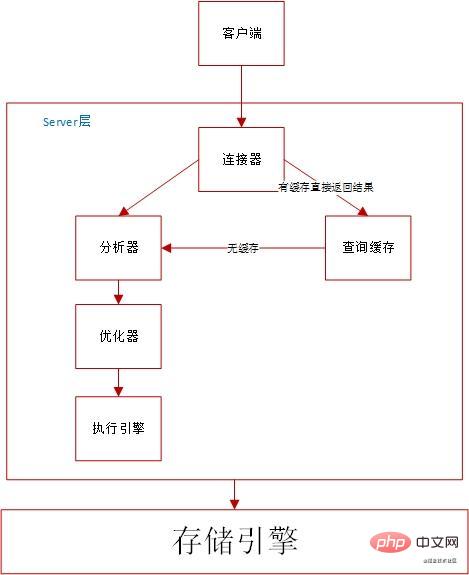
The execution process of sql is basically the same as the mysql architecture
Execution process:
Connector:
Connector:
Establish a connection with MySQL, used to query SQL statements and determine permissions.
Query cache:
If the statement is not in the query cache, the subsequent execution phase will continue. After the execution is completed, the execution results will be stored in the query cache
If the query hits the cache, MySQL can directly return the results without performing subsequent complex operations, improving efficiency
Analyzer: - Performs hard parsing on SQL statements. The analyzer will first perform lexical analysis. Analyze the components of SQL statements. Determine whether the entered SQL statement satisfies the syntax rules.
- Optimizer:
The optimizer determines which index to use when there are multiple indexes in the table; or when a statement has multiple table associations (joins), it determines each table connection sequence. The logical results of different execution methods are the same, but the execution efficiency will be different, and the role of the optimizer is to decide which solution to use.
Executor:
With index: The first call is to get the interface of the first line that meets the condition, and then loop to get the interface of the next line that meets the condition, and finally Query results are returned to the client
No index: Call the InnoDB engine interface to get the first row of this table, judge the SQL query conditions, if not, skip it, if so, store this row in the result set; Call the engine interface Get the next row and repeat the same judgment logic until you get the last row of the table. The executor returns a record set composed of all rows that meet the conditions during the above traversal process as a result set to the client
Understand the execution plan-
- What will the EXPLAIN command output MySQL Execute your SQL statement, but will not return data
How to use
[root@localhost][(none)]> explain select * from 表名 where project_id = 36;
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | 表名 | NULL | ref | project_id | project_id | 4 | const | 797964 | 100.00 | NULL |
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+复制代码
Copy after login
id-
- id same execution order from top to bottom
- The id is different. The larger the id value, the higher the priority and the earlier it is executed.
- select_type
-
- SIMPLE: Simple select query, the query does not contain subtitles Query or union
- PRIMARY: The query contains subparts, and the outermost query is marked as primary
- DERIVED: It is part of the subquery from
DEPENDENT SUBQUERY: Sub The first SELECT in the query, the subquery depends on the result of the outer query
SUBQUERY means that the subquery is included in the select or where list,
- MATERIALIZED: means the in condition after where Subquery
UNION: Represents the second or subsequent select statement in union
UNION RESULT: The result of union
table###### ###Table object#########type########system > const > eq_ref > ref > range > index > ALL (query efficiency)###
- system:表中只有一条数据,这个类型是特殊的const类型
- const:针对于主键或唯一索引的等值查询扫描,最多只返回一个行数据。速度非常快,因为只读取一次即可。
- eq_ref:此类型通常出现在多表的join查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果,并且查询的比较操作通常是=,查询效率较高
- ref:此类型通常出现在多表的join查询,针对于非唯一或非主键索引,或者是使用了最左前缀规则索引的查询
- range:范围扫描 这个类型通常出现在 <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中
- index:索引树扫描
- ALL:全表扫描(full table scan)
possible_keys
- 可能使用的索引,注意不一定会使用
- 查询涉及到的字段上若存在索引,则该索引将被列出来
- 当该列为NULL时就要考虑当前的SQL是否需要优化了
key
- 显示MySQL在查询中实际使用的索引,若没有使用索引,显示NULL。
- 查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
key_length
ref
- 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
filtered
- 示返回结果的行数占需读取行数的百分比, filtered 的值越大越好
extra
- Using where:表示优化器需要通过索引回表,之后到server层进行过滤查询数据
- Using index:表示直接访问索引就足够获取到所需要的数据,不需要回表
- Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown)
- Using index for group-by:使用了索引来进行GROUP BY或者DISTINCT的查询
- Using filesort:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
- Using temporary 临时表被使用,时常出现在GROUP BY和ORDER BY子句情况下。(sort buffer或者磁盘被使用)
光看 filesort 字面意思,可能以为是要利用磁盘文件进行排序,实则不全然。 当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个 数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必 须将查询的结果集生成一个临时表,在连接完成之后行行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
提高查询效率
正确使用索引
为解释方便,来一个demo:
DROP TABLE IF EXISTS user;
CREATE TABLE user(
id int AUTO_INCREMENT PRIMARY KEY,
user_name varchar(30) NOT NULL,
gender bit(1) NOT NULL DEFAULT b’1’,
city varchar(50) NOT NULL,
age int NOT NULL
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE user ADD INDEX idx_user(user_name , city , age);
复制代码
Copy after login
什么样的索引可以被使用?
- **全匹配:**SELECT * FROM user WHERE user_name='JueJin'AND age='5' AND city='上海';(与where后查询条件的顺序无关)
-
匹配最左前缀:(user_name )、(user_name, city)、(user_name , city , age)(满足最左前缀查询条件的顺序与索引列的顺序无关,如:(city, user_name)、(age, city, user_name))
- **匹配列前缀:**SELECT * FROM user WHERE user_name LIKE 'W%'
- **匹配范围值:**SELECT * FROM user WHERE user_name BETWEEN 'W%' AND 'Z%'
什么样的索引无法被使用?
- **where查询条件中不包含索引列中的最左索引列,则无法使用到索引: **
SELECT * FROM user WHERE city='上海';
SELECT * FROM user WHERE age='26';
SELECT * FROM user WHERE age='26' AND city=‘上海';
- **Even if the query condition of where is the leftmost index column, you cannot use the index to query users whose username ends with N: **
SELECT * FROM user WHERE user_name LIKE '%N';
- **If there is a range query of a certain column in the where query condition, all columns to the right cannot use index optimization query: **
SELECT * FROM user WHERE user_name='JueJin' AND city LIKE '上%' AND age=31;
- **Index columns cannot be part of an expression, nor can they be used as parameters of a function , otherwise the index query cannot be used: **
SELECT * FROM user WHERE user_name=concat(user_name,'PLUS');
Select the appropriate index column order
- The order of index columns is very important in the creation of a composite index. The correct index order depends on the query method of the query using the index.
- For the index order of the composite index, the most selective index can be The column is placed at the front of the index. This rule is consistent with the selective method of prefix index. It does not mean that the order of all combined indexes can be determined using this rule. It also needs to be determined according to the specific query scenario. Index order
- Covering index conditions
If an index contains the values of all the fields to be queried, it is called a covering index
-
SELECT user_name, city, age FROM user WHERE user_name='Tony' AND age='28' AND city='Shanghai';
Because the fields to be queried (user_name, city, age ) are included in the index columns of the combined index, so a covering index query is used. To check whether a covering index is used, the value of Extra in the execution plan is
Using index, which proves that a covering index is used. , covering index can greatly improve access performance.
Use index for sorting
If the index can be used for sorting during the sorting operation, the speed of sorting can be greatly improved. To use the index for sorting, the following two points must be met That’s it:
The column order after the ORDER BY clause must be consistent with the column order of the combined index, and the sorting direction (forward/reverse order) of all sorting columns must be consistent
- The queried field value needs to be included in the index column and satisfy the covering index
- Sorting available demo:
SELECT user_name, city, age FROM user_test ORDER BY user_name;
- SELECT user_name, city, age FROM user_test ORDER BY user_name,city;
- SELECT user_name, city, age FROM user_test ORDER BY user_name DESC,city DESC;
- SELECT user_name , city, age FROM user_test WHERE user_name='Tony' ORDER BY city;
- Sort not availabledemo:
SELECT user_name, city, age FROM user_test ORDER BY user_name
gender- ; SELECT user_name, city, age,
gender- FROM user_test ORDER BY user_name; SELECT user_name, city, age FROM user_test ORDER BY user_name
ASC- ,city DESC; SELECT user_name, city, age FROM user_test WHERE user_name LIKE
'W%'- ORDER BY city;
Data acquisition suggestions
Do not return data limits that are not required by the user program
LIMIT
: MySQL cannot return the amount of data as required, that is, MySQL will always query all the data. Using the LIMIT clause is actually to reduce the pressure of network data transmission and will not reduce the number of rows of data read.
Remove unnecessary columns
The SELECT * statement removes all fields in the table, regardless of whether the data in the field is useful to the calling application. It will cause a waste of server resources and even have a certain impact on the performance of the server
- If the structure of the table changes in the future, the SELECT * statement may obtain incorrect data
- When executing a SELECT * statement, you must first find out which columns are in the table, and then you can start executing the SELECT * statement. This will cause performance problems in some cases
- Using the SELECT * statement will not cause overwriting Indexes are not conducive to query performance optimization
-
Advantages of using indexes correctly
- When querying a single table, a full table scan needs to query each row
- When querying multiple tables, a full table scan requires at least Retrieve every row in all tables
- You can quickly locate the first row of the result set
- Exclude irrelevant The result
- No need to check each row for MIN() or MAX() values
- Improve the efficiency of sorting and grouping
- You can use covering index Avoid row loop-up
The cost of indexing
- If there are too many indexes, data modification will become slow
- The affected index needs to be updated
- It is very stressful for write-intensive environments
- The index consumes too much disk space
- InnoDB storage engine stores indexes and data together
- Needs to monitor disk space
Index best practices
Consider using indexes for the following columns
- Columns in the WHERE clause
- Columns in the ORDER BY or GROUP BY clause
- Table join condition columns
Consider using prefix indexes for string columns
- allows for faster comparison and loop up
- Reduces disk I/O
The SELECT statement is inefficient Consider
- Avoid full table scan
- Try to add index
##WHERE statement - Table connection conditions
-
Use ANALYZE TABLE to collect statistical information - Consider the optimization of the storage engine layer
-
Tuning the table connection method
Add an index on the column of the ON or USING clause - Use SELECT STRAIGHT_JOIN to force the table connection order
- Add an index on the column of ORDER BY and GROUP BY
- join Connections are not necessarily more efficient than subqueries
-
More related free learning recommendations:mysql tutorial (video)
The above is the detailed content of Relational database mysql three: starting from the life cycle of a sql. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



