


Free recommendation: python video tutorial
It has been a long time since I last wrote a crawler article. I wrote a 20-line Python code to crawl the skins of all heroes of Honor of Kings
, and the response was strong. Many students wanted me to write another article to crawl the skins of the official League of Legends website, but due to the many things, I kept putting it off. , has been delayed until now, so in this article we will learn how to crawl all hero skins in League of Legends.
Crawling the code is very simple. You may only need to write about 30 lines from top to bottom to complete, but the important thing is the analysis process. Before that, let’s first understand what is needed in this article. module.
The first is the requests module, which is a module that simulates browser requests. We can use it to obtain information on the web page, such as Baidu:
import requests url = 'http://www.baidu.com'response = requests.get(url)print(response.text)
Run result: 
Through the get function, you can send a request to the URL with specified parameters. The response object obtained encapsulates a lot of response information, among which text is the response content. It is noted that there are garbled characters in the obtained content. This is caused by inconsistent encoding and decoding. You only need to obtain the binary data first and then re-decode it:
import requests url = 'http://www.baidu.com'response = requests.get(url)print(response.content.decode())
Running results: 
The json module can convert json strings and Python data types to and from each other, such as converting json to Python objects:
import json
json_str = '{"name":"zhangsan","age":"20"}'rs = json.loads(json_str)print(type(rs))print(rs)Use# The ##loads function can convert a json string into a dictionary type. The running result is:
<class>
{'name': 'zhangsan', 'age': '20'}</class>import json
str_dict = {'name': 'zhangsan', 'age': '20'}json_str = json.dumps(str_dict)print(type(json_str))print(json_str)dumps function. The running result is:
<class>
{"name": "zhangsan", "age": "20"}</class> Before officially starting to write code, we first need to analyze the data source, go to the official website: https://lol.qq.com/main.shtml, scroll down to find the hero list:  We click on a hero at random to check:
We click on a hero at random to check:  Right-click on the skin picture to check:
Right-click on the skin picture to check: 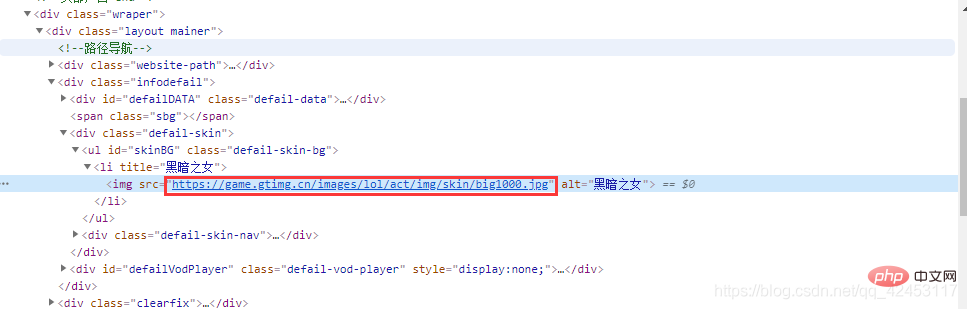 In this way, we find the url of this skin. Let’s select the second skin and take a look. Its URL:
In this way, we find the url of this skin. Let’s select the second skin and take a look. Its URL: 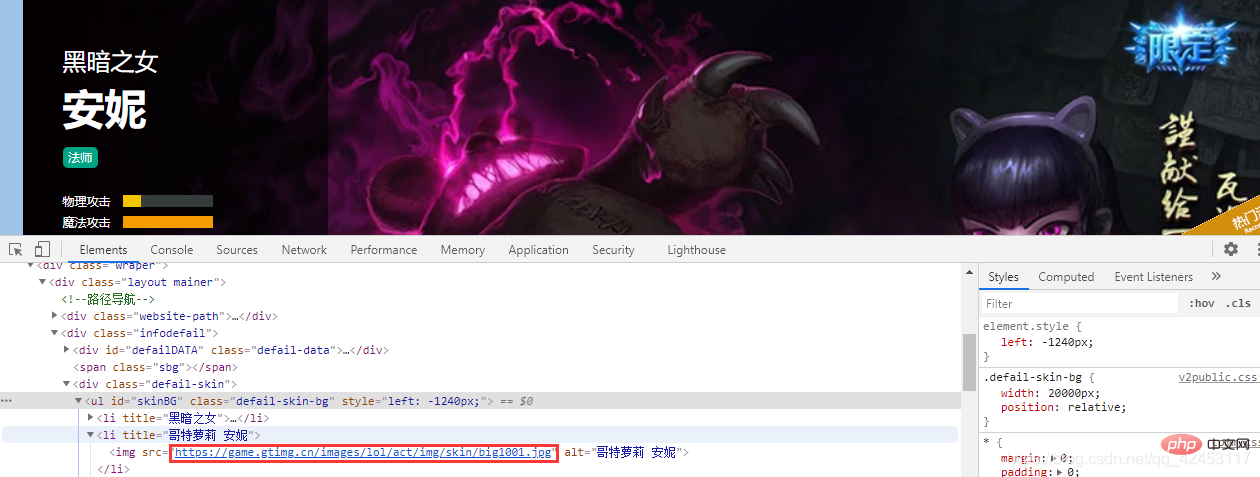 Let’s take a look at all the URLs for Annie’s skins:
Let’s take a look at all the URLs for Annie’s skins:
https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1001.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1002.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1003.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1004.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1005.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1006.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1007.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1008.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1009.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1010.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1011.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1012.jpg
big1000.jpg, and each skin picture adds 1 to the URL.
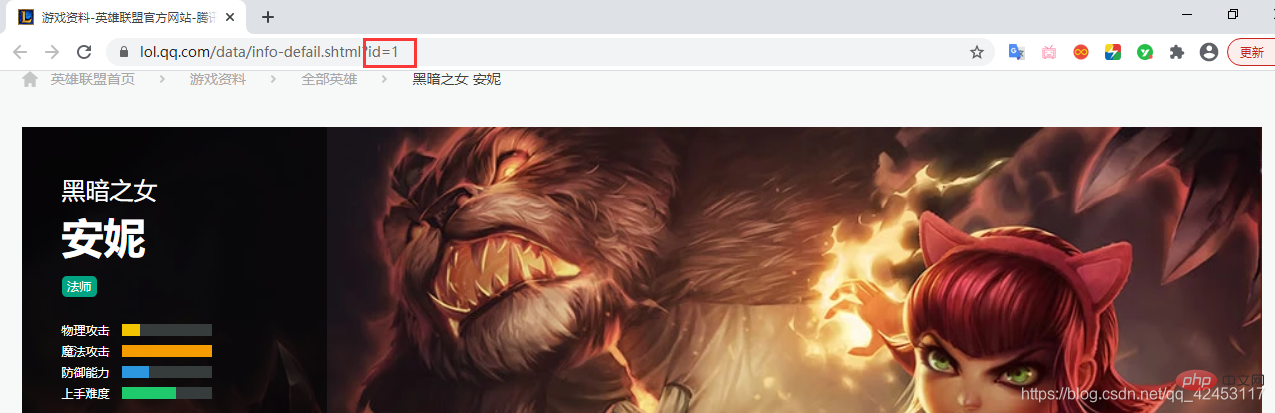 There is an attribute value id on the address, so we can guess whether
There is an attribute value id on the address, so we can guess whether
big1000.jpg in the skin picture URL is made by What is the combination of hero ID and skin ID?
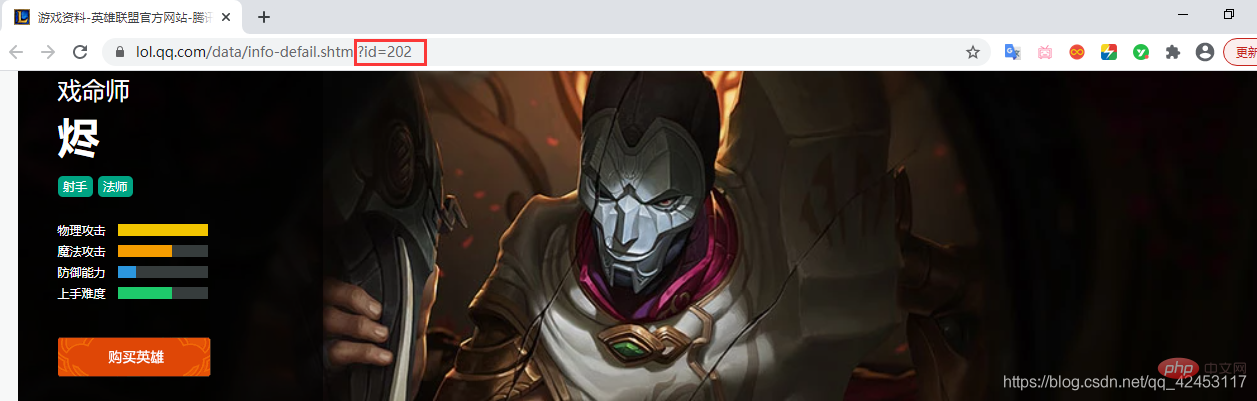 Open Jhin’s details page, its ID is 202, Therefore, the last part of Jhin's skin picture URL should be:
Open Jhin’s details page, its ID is 202, Therefore, the last part of Jhin's skin picture URL should be:
big ' 202 ' skin number.jpg, so its URL should be:
https://game.gtimg.cn/images/lol/act/img/skin/big202000.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202001.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202002.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202003.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202004.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202005.jpg
事实是不是如此呢?检查一下便知: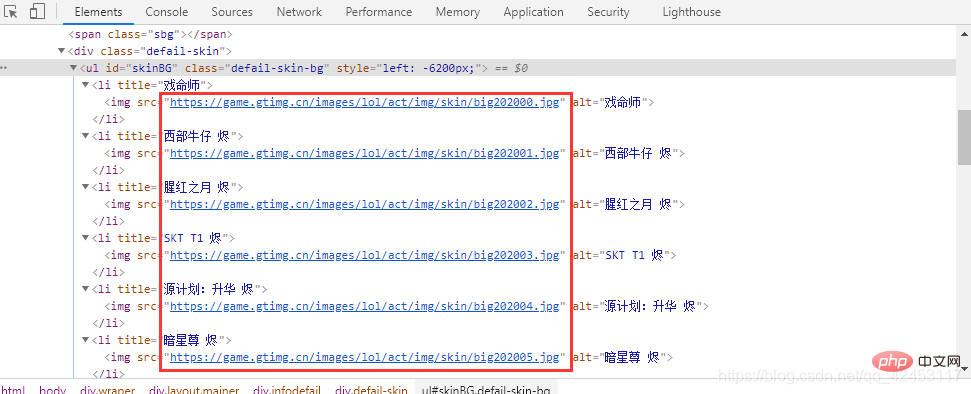
规律已经找到,但是我们还面临着诸多问题,比如每个英雄对应的id是多少呢?每个英雄又分别有多少个皮肤呢?
先来解决第一个问题,每个英雄对应的id是多少?我们只能从官网首页中找找线索,在首页位置打开网络调试台: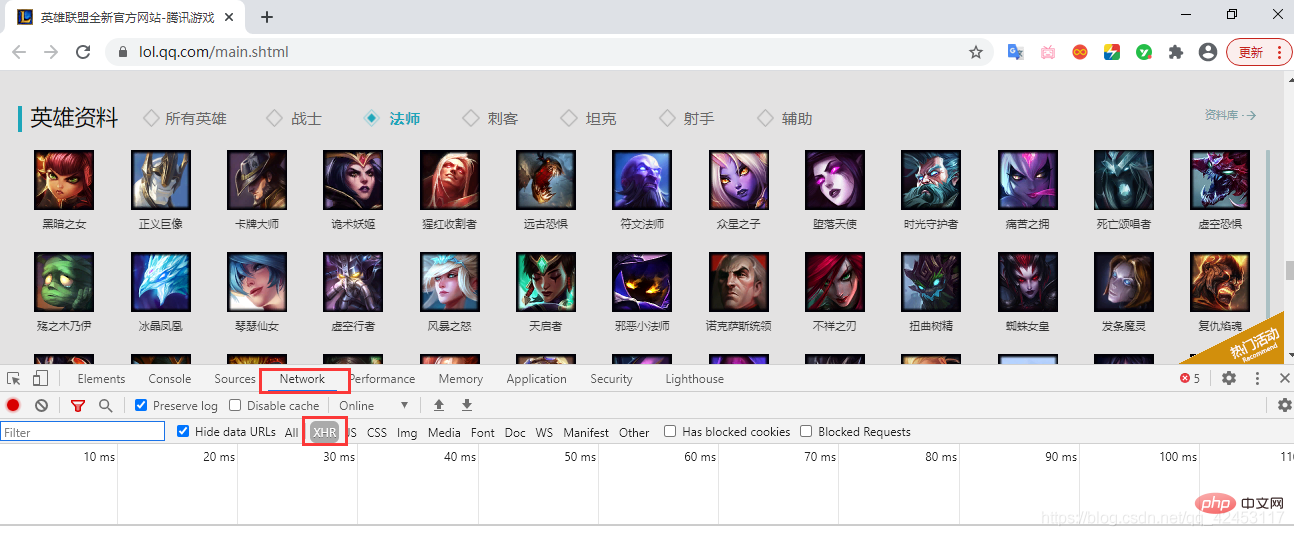
点击Network,并选中XHR,XHR是浏览器与服务器请求数据所依赖的对象,所以通过它便能筛选出一些服务器的响应数据。
此时我们刷新页面,在筛选出的内容发现了这么一个东西: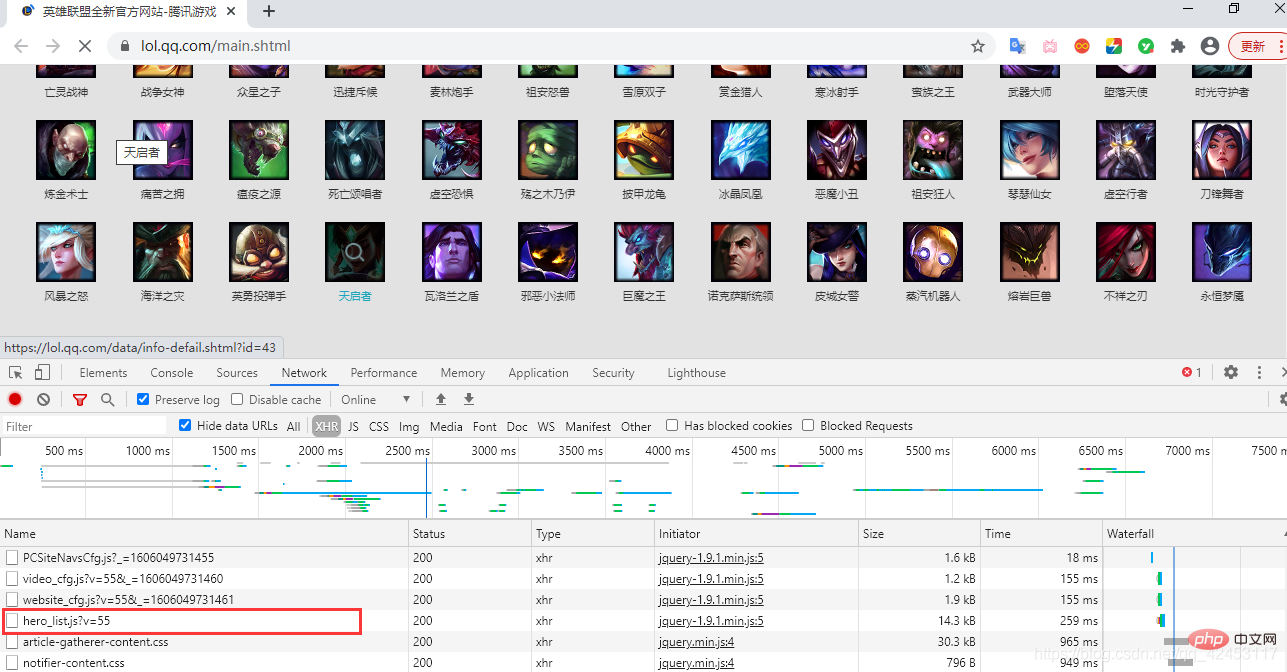
hero_list,英雄列表?这里面会不会存储着所有英雄的信息呢?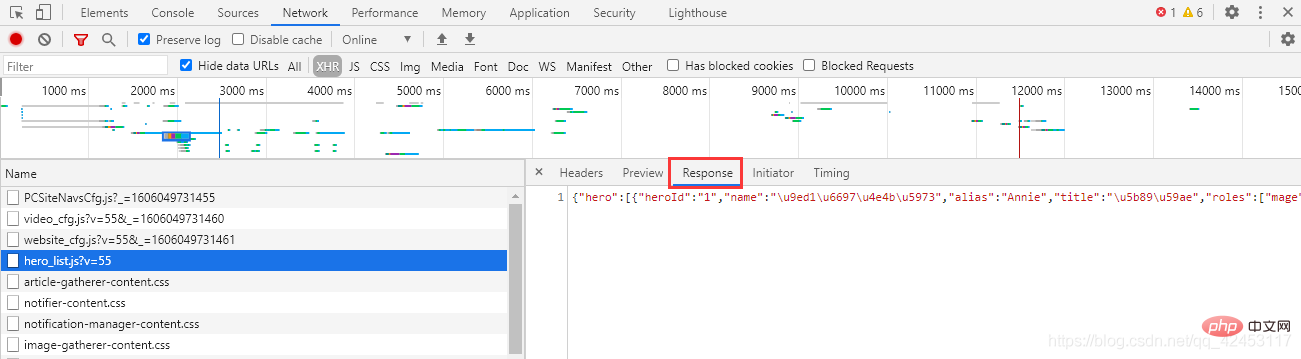
点击右侧的Response,得到了一串json字符串,我们将其解析一下: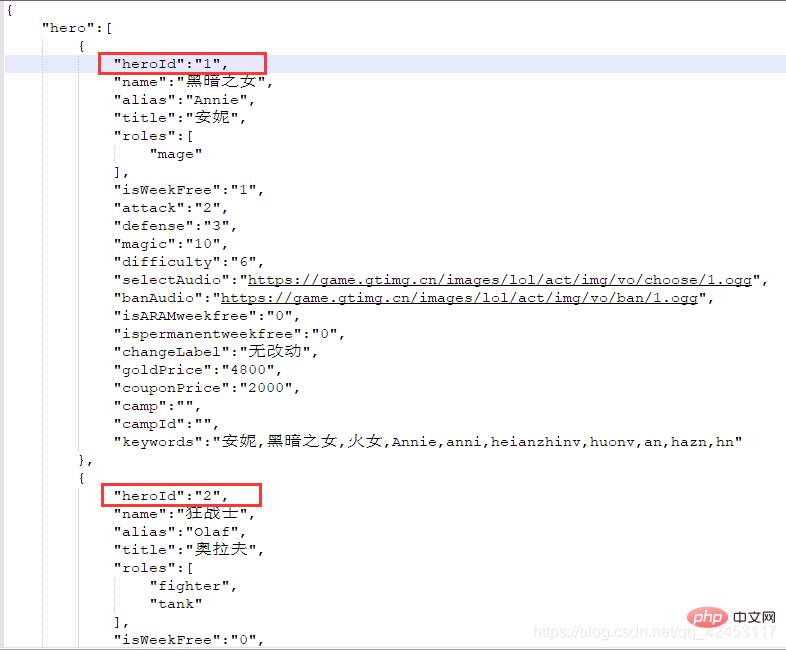
这些数据里果然存储的是英雄的信息,包括名字、id、介绍等等,那么接下来我们的任务就是将英雄名字和id单独提取出来,过滤掉其它信息。
忘了告诉你们了,这个文件的url在这里可以找到: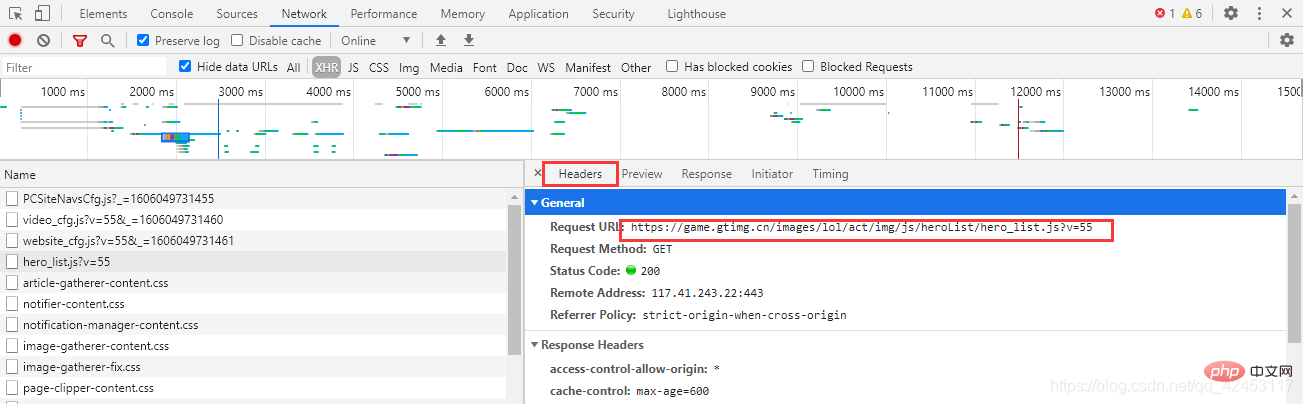
接下来开始写代码:
import jsonimport requests# 定义一个列表,用于存放英雄名称和对应的idhero_id = []url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'response = requests.get(url)text = response.text# 将json字符串转为列表hero_list = json.loads(text)['hero']# 遍历列表for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)print(hero_id)首先通过requests模块请求该url,就能够获取到一个json字符串,然后使用json模块将该字符串转为Python中的列表,最后循环取出每个英雄的name和heroid属性,放入新定义的列表中,这个程序就完成了英雄id的提取。
接下来解决第二个问题,如何知晓某个英雄究竟有多少个皮肤,按照刚才的思路,我们可以猜测一下,对于皮肤也应该会有一个文件存储着皮肤信息,在某个英雄的皮肤页面打开网络调试台,并选中XHR,刷新页面,找找线索: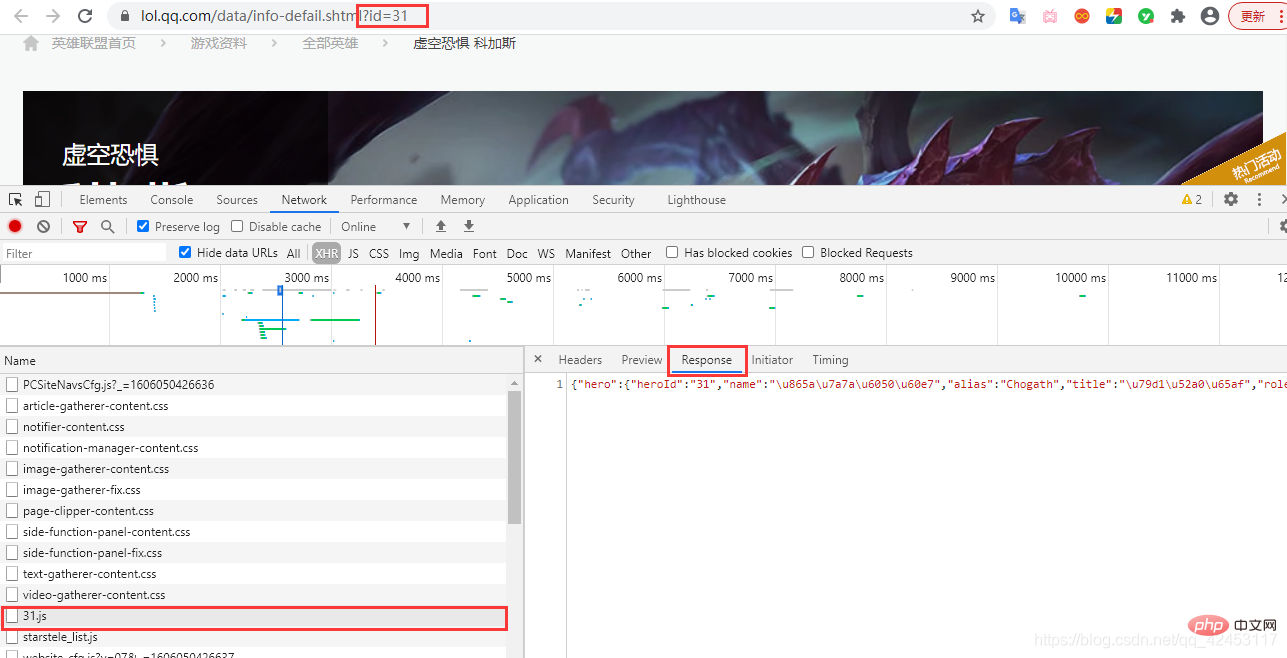
找来找去确实找不到有哪个文件是跟皮肤有关系的,但是这里发现了一个31.js文件,而当前英雄的id也为31,这真的是巧合吗?我们将右边的json字符串解析一下: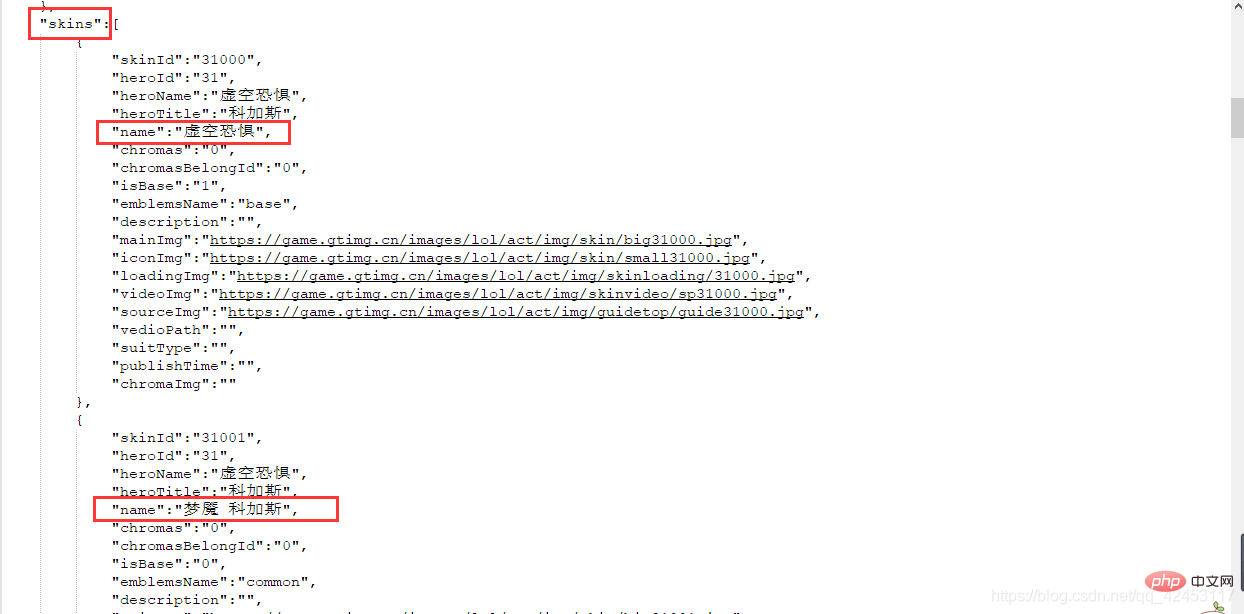
该json数据中有一个skins属性,该属性值即为当前英雄的皮肤信息,既然找到了数据,那接下来就好办了,开始写代码:
import jsonimport requests url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/31.js'response = requests.get(url)text = response.text# 将json字符串转为列表skins_list = json.loads(text)['skins']skin_num = len(skins_list)
准备工作已经完成了我们所有的前置任务,接下来就是在此基础上编写代码了:
import requestsimport jsonimport osimport tracebackfrom tqdm import tqdmdef spider_lol():
# 定义一个列表,用于存放英雄名称和对应的id
hero_id = []
skins = []
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'
response = requests.get(url)
text = response.text # 将json字符串转为列表
hero_list = json.loads(text)['hero']
# 遍历列表
for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)
# 得到每个英雄对应的id后,即可获得英雄对应皮肤的url
# 英雄id + 001
# 遍历列表
for hero in hero_id:
# 得到英雄名字
hero_name = hero['name']
# 得到英雄id
hero_id = hero['id']
# 创建文件夹
os.mkdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 进入文件夹
os.chdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 得到id后即可拼接存储该英雄信息的url
hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/' + hero_id + '.js'
# 通过访问该url获取英雄的皮肤数量
text = requests.get(hero_info_url).text
info_list = json.loads(text)
# 得到皮肤名称
skin_info_list = info_list['skins']
skins.clear()
for skin in skin_info_list:
skins.append(skin['name'])
# 获得皮肤数量
skins_num = len(skin_info_list)
# 获得皮肤数量后,即可拼接皮肤的url,如:安妮的皮肤url为:
# https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg ~ https://game.gtimg.cn/images/lol/act/img/skin/big1012
s = ''
for i in tqdm(range(skins_num), '正在爬取' + hero_name + '的皮肤'):
if len(str(i)) == 1:
s = '00' + str(i)
elif len(str(i)) == 2:
s = '0' + str(i)
elif len(str(i)) == 3:
pass
try:
# 拼接皮肤url
skin_url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + hero_id + '' + s + '.jpg'
# 访问当前皮肤url
im = requests.get(skin_url)
except:
# 某些英雄的炫彩皮肤没有url,所以直接终止当前url的爬取,进入下一个
continue
# 保存图片
if im.status_code == 200:
# 判断图片名称中是否带有'/'、'\'
if '/' in skins[i] or '\\' in skins[i]:
skins[i] = skins[i].replace('/', '')
skins[i] = skins[i].replace('\\', '')
with open(skins[i] + '.jpg', 'wb') as f:
f.write(im.content)def main():
try:
spider_lol()
except Exception as e:
# 打印异常信息
print(e)if __name__ == '__main__':
main()运行效果: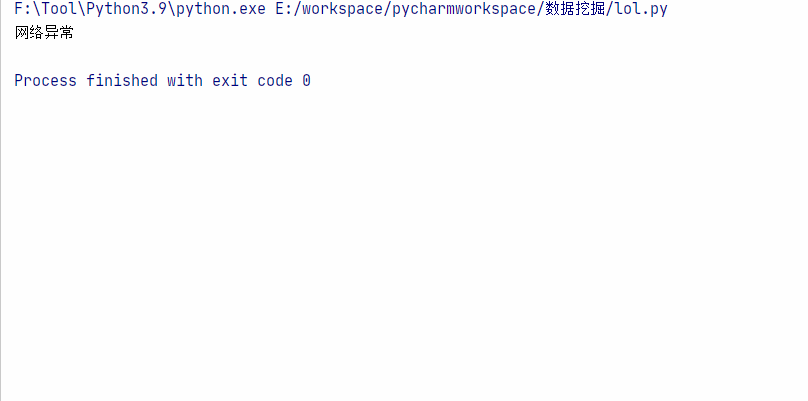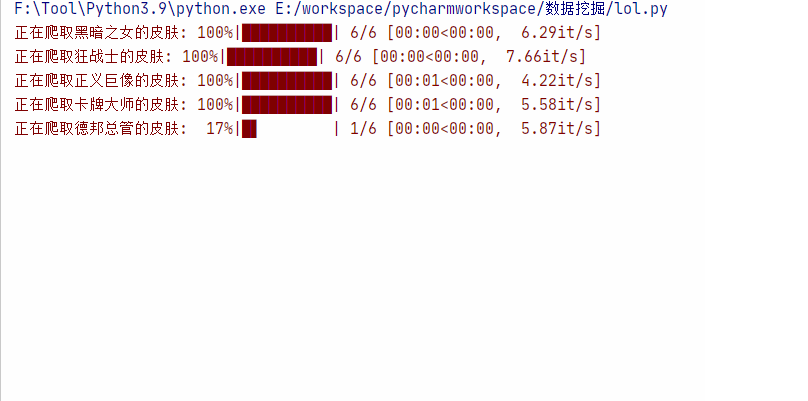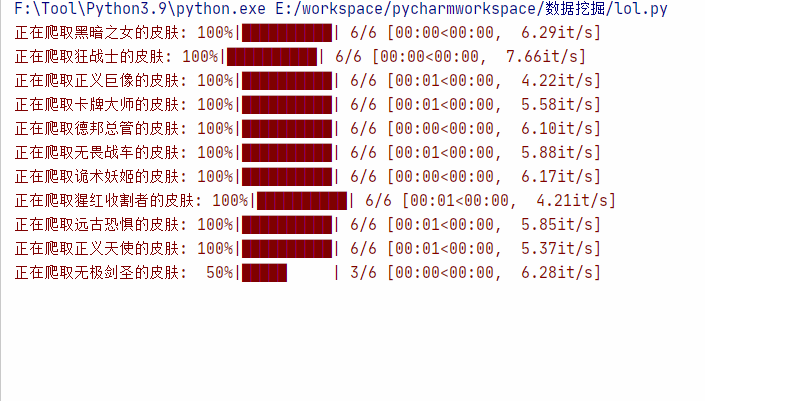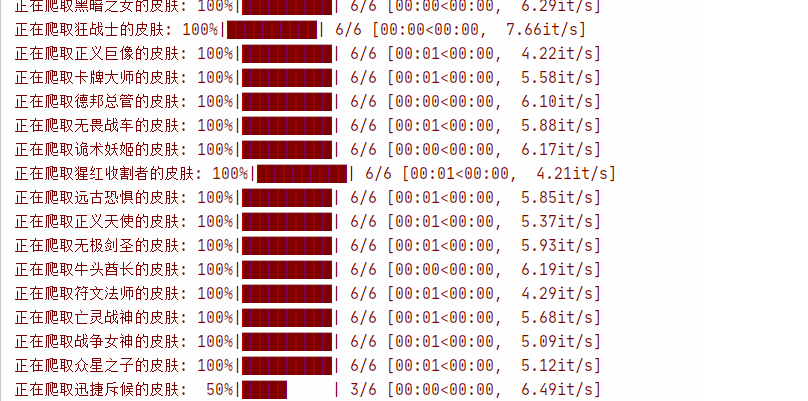
运行之前记得在桌面上创建一个lol文件夹,如果想改动的话也可以修改程序: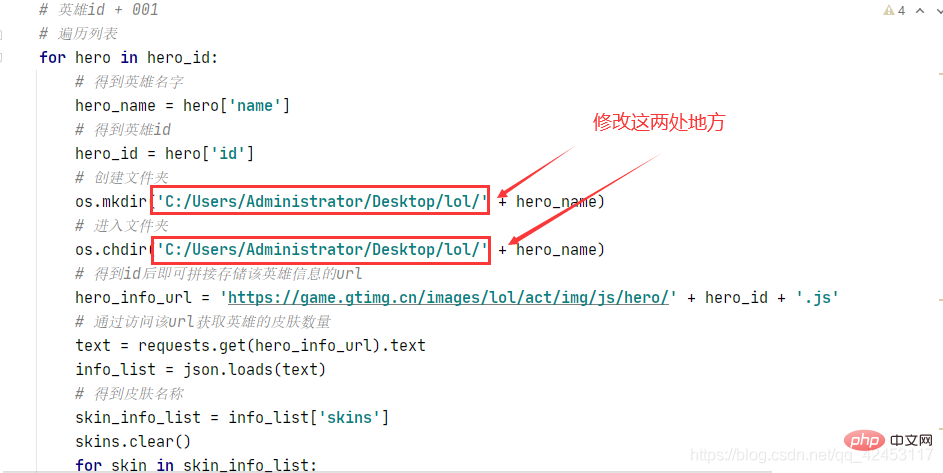
程序中还考虑到了一些其它情况,比如在爬取这个皮肤的时候会出现问题:
因为图片路径是以皮肤名字命名的,然而这个皮肤的名字中竟然有个/,它是会影响到我们的图片保存操作的,所以在保存前将斜杠替换成空字符即可。
还有一个问题就是即使是第一个皮肤,其编号也应该为000而不是0,所以还需要对其进行一个转化,让其始终是三位数。
本篇文章同样继承了上篇文章精简的特点,抛去注释的话总共30行代码左右,程序当然还有一些其它地方可以进一步优化,这就交给大家自由发挥了。
The above is the detailed content of Awesome, 30 lines of python code to crawl all hero skins in League of Legends. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



