
 Database
Mysql Tutorial
Pinterest MySQL practice uses sharding to solve the storage problem of tens of billions of data
Database
Mysql Tutorial
Pinterest MySQL practice uses sharding to solve the storage problem of tens of billions of data
Pinterest MySQL practice uses sharding to solve the storage problem of tens of billions of data

mysql video tutorialThe column introduces the use of sharding to solve the storage of tens of billions of data

Recommended (free): mysql video tutorial
This is a technical study on how we split data across multiple MySQL servers. We completed this sharding approach in early 2012, and it is still the system we use to store core data today.
Before we discuss how to split the data, let’s first understand our data. Mood lighting, chocolate covered strawberries, Star Trek quotes...
Pinteres is the discovery engine for everything that interests you. From a data perspective, Pinterest is the largest collection of human interest images in the world. There are more than 50 billion Pins saved by Pinners on 1 billion boards. The user pins again, likes other people's Pins (roughly a shallow copy), follows other Pinners, boards and interests, and then views all of the subscribed Pinrs' posts on the home page. Very good! Now let it scale up!
Growing Pains
In 2011 we achieved success. In some evaluation reports, we are growing much faster than other startups. In September 2011, every one of our infrastructure facilities was exceeded. We applied a number of NoSQL technologies, all of which resulted in disastrous results. At the same time, the large number of MySQL slave servers used for reading created a lot of annoying bugs, especially caching. We restructured the entire data storage model. To make this effective, we carefully formulate our requirements.
Business Requirements
- All our systems need to be very stable, easy to operate and easy to expand. We hope that the supported database can start with a small storage capacity and be able to expand as the business develops.
- All Pin-generated content must be readily accessible on the site.
- Supports requesting access to N Pins to be displayed in the artboard in a certain order (such as according to the creation time, or in a user-specific order). Liked Pin friends and Pin lists of Pin friends can also be displayed in a specific order.
- For the sake of simplicity, updates generally ensure the best results. To get eventual consistency, you need something extra like a distributed transaction log. This is an interesting and (not) simple thing.
Solution ideas and key points
The solution requires distributing massive data slices to multiple database instances, so connections to relational databases cannot be used. Methods such as foreign keys or indexes integrate the entire data. If you think about it, correlated subqueries cannot span different database instances.
Our solution requires load balancing data access. We hate data migration, especially record-by-record migration, which is very error-prone and adds unnecessary complexity to the system due to the complexity of relationships. If data must be migrated, it is best to migrate the entire set of logical nodes.
In order to achieve reliable and rapid implementation of the solution, we need to use the easiest to implement and most robust technical solution on our distributed data platform.
All data on each instance will be completely copied to a slave instance as a data backup. We are using S3, a highly available MapReduce (distributed computing environment). Our front-end business logic accesses background data and only accesses the main instance of the database. Never let your front-end business have read and write access from the instance . Because there is a delay in data synchronization with the main instance, it will cause inexplicable errors. Once the data is sliced and distributed, there is no reason for your front-end business to read and write data from the slave instance.
Finally, we need to carefully design an excellent solution to generate and parse the Globally unique identifier (UUID) of all our data objects.
Our slicing solution
No matter what, we need to design a data distribution solution that meets our needs, is robust, has good performance and is maintainable. In other words, it cannot be naive (without extensive validation). Therefore, our basic design is built on MySQL, see we chose a mature technology. At the beginning of the design, we would naturally shy away from those database products that claim to have the new capabilities of auto-scaling, such as MongoDB, Cassandra and Membase, because they seem to be simple to implement but have poor applicability (often An inexplicable error occurred causing a crash).
Narration: It is strongly recommended to start with the basics and avoid the trendy and new stuff - learn and use MySQL well in a down-to-earth manner. Believe me, every word is filled with tears.
MySQL is a mature, stable and easy-to-use relational database product. Not only do we use it, but many well-known large companies also use it as back-end data support to store massive amounts of data. (Annotation: About a few years ago, because MySQL was acquired by Oracle along with SUN, it came under the name of Oracle. Many companies, such as Google, Facebook, etc., were worried about MySQL’s open source issues and switched to another database developed by the original author of MySQL. The open source database MariaDB (under) MySQL supports our technical requirements for sequential data requests to the database, querying specified range of data and transaction processing at the row (record) level. MySQL has a bunch of features, but we don't need those. Since MySQL itself is a monolithic solution, we have to slice our data. (Annotation: The meaning here is that a single instance manages massive amounts of data, which will inevitably cause performance problems. Now slicing a massive overall data into individual data sets requires a powerful technical solution to separate each individual data set. The monoliths are integrated into a whole, improving performance without going wrong) The following is our design plan:
We started with 8 EC2 servers, each server running a MySQL instance:


Each MySQL server uses master-master replicated to a redundant host for disaster recovery. Our front-end business only reads/writes data from the main service instance. I recommend you do the same, it simplifies many things and avoids delayed glitches. (Annotation: Master-master replicated) is a function provided by the MySQL database itself. It refers to a mode in which two machines backup each other. Compared with other modes, such as master-slave backup, two machines The data of each machine is completely consistent and synchronized in the background. Each machine has its own independent IP and can be accessed concurrently for read/write access. However, the author of the original article has repeatedly emphasized that although the two machines are redundant with each other and use master-master backup, both machines can be accessed. Access. But you logically distinguish master-slave, and always read/write from one of them. For example, as shown in the figure, there is a master-master backup between MySQL001A and MySQL001B, but you only perform read/write access from MySQL001A. Another: They used 16 machines, and the other 8 slave machines may not be EC2 or not)
Each MySQL instance can have multiple databases:

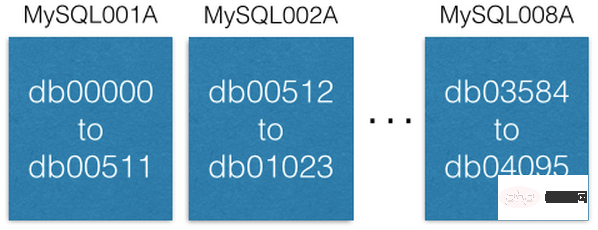
Notice how each database is uniquely named db00000, db00001, up to dbNNNN. Each database is a shard of our database. We made a design so that once a piece of data is allocated to a shard, it will not be moved out of that shard. However, you can get more capacity by moving shards to other machines (we'll discuss this later).
We maintain a configuration database table, which records which machine the slice database is on:
[
{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”},
{“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”},
...
{“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}
]This configuration table is only modified when the slice database is migrated or the host is replaced. For example, if a master instance host goes down, we will promote its slave instance host to the master instance and then replace it with a new machine as the slave instance host as soon as possible. The configuration script is retained on ZooKeeper. When the above modification occurs, the script is sent to the machine that maintains the slicing service for configuration changes. (Annotation: You can find the advantage that the original author has always emphasized that the front-end business only reads and writes data from the logical master instance).
Each slice database maintains the same database table and table structure, such as pins, boards, users_has_pins, users_likes_pins, pin_liked_by_user and other database tables. Build synchronously at deployment time.
Design scheme for distributing data to slice servers
We combine shard ID (shard ID), data type identification and local ID (local ID) Form a 64-bit global unique identification (ID). Slice ID (shard ID) occupies 16 bits (bit), data type identification occupies 10 bits (bit), local ID (local ID) occupies 36 bits (bit) . Anyone with a discerning eye will immediately notice that this is only 62 bits. My past experience in distributing and integrating data tells me that retaining a few for expansion is priceless. Therefore, I kept 2 bits (set to 0). (Annotation: Let me explain here. According to the following operations and explanations, the unique identification ID of any object is 64 bits. The highest 2 bits are always 0, followed by a 36-bit local identification, followed by a 10-bit type identification, and finally 16 bits. The slice identifier. The local identifier can represent 2^36 up to more than 60 billion IDs. The data type can represent 2^10 up to 1024 object types, and the slice identifier can be subdivided into 2^16 up to 65536 slice databases. The solution mentioned earlier 4096 sliced database)
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Take Pin: https://www.pinterest.com/pin/241294492511... as an example, let us deconstruct the global ID of this Pin object 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
可知这个 Pin 对象在3429切片数据库里。 假设 Pin 对象 数据类型标识为 1,它的记录在3429切片数据库里的 pin 数据表中的 7075733 记录行中。举例,假设切片3429数据库在 MySQL012A中,我们可利用下面语句得到其数据记录:(译注:这里原作者泛泛举例,若按其前面方案例子来说,3429应在MySQL007A 上)
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
有两种类型的数据:对象或关系。对象包含对象本身细节。 如 Pin 。
存储对象的数据库表
对象库表中的每个记录,表示我们前端业务中的一个对象,诸如:Pins(钉便签), users(用户),boards(白板)和 comments(注释),每个这样的记录在数据库表中设计一个标识 ID 字段(这个字段在表中作为记录的 自增主键「auto-incrementing primary key」 ,也就是我们前面提到的 局部 ID「 local ID」 ),和一个 blob 数据字段 -- 使用 JSON 保存对象的具体数据 --。
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
举例,一个 Pin 对象形状如下:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}创建一个 Pin 对象,收集所有的数据构成 JSON blob 数据。然后,确定它的 切片 ID「 shard ID」 (我们更乐意把 Pin 对象的切片数据放到跟其所在 白板「 board」 对象相同的切片数据库里,这不是强制设计规则)。Pin 对象的数据类型标识为 1。连接到 切片 ID 指示的切片数据库,插入(insert)Pin 对象的 JOSON 数据到 Pin 对象数据库表中,MySQL 操作成功后将会返回 自增主键「auto-incrementing primary key」 给你,这个作为此 Pin 对象的 局部 ID「 local ID」。现在,我们有了 shard 、类型值、local ID 这些必要信息,就可以构建出此 Pin 对象的64位 ID 。(译注:原作者提到的,他们的前端业务所用到的每种对象都保存在一个对象数据库表里,每个对象记录都通过一个全局唯一 ID去找到它,但这个全局唯一 ID并不是数据库表中的 局部ID,由于切片的缘故。原作者一直在讲这个设计及其原理。这样设计的目的为了海量数据切片提高性能,还要易用,可维护,可扩展。后面,作者会依次讲解到)
编辑一个 Pin 对象,使用 MySQL 事务「transaction」 在 Pin 对象的数据记录上 读出--修改--写回「read-modify-write」 Pin 对象的 JOSON 数据字段:
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [修改 json blob] > UPDATE db03429.pins SET blob=’<修改后的 blob>’ WHERE local_id=7075733 > COMMIT
编辑一个 Pin 对象,您当然可以直接删除这个对象在 MySQL 数据库表中的数据记录。但是,请仔细想一下,是否在对象的 JSON 数据上加个叫做「 active」的域,把剔除工作交由前端中间业务逻辑去处理或许会更好呢。
(译注:学过关系数据库的应知道,自增主键在记录表中是固实,在里面删除记录,会造成孔洞。当多了,势必造成数据库性能下降。数据库只负责保存数据和高性能地查询、读写数据,其数据间的关系完全靠设计精良的对象全局ID通过中间件逻辑去维护 这样的设计理念一直贯穿在作者的行文中。只有理解了这点您才能抓住这篇文章的核心)
关系映射数据库表
关系映射表表示的是前端业务对象间的关系。诸如:一个白板(board)上有哪些钉便签(Pin), 一个钉便签(Pin)在哪些白板(board)上等等。表示这种关系的 MySQL 数据库表包括3个字段:一个64位的「from」ID, 一个64位的「to」ID和一个顺序号。每个字段上都做索引方便快速查询。其记录保存在根据「from」字段 ID 解构出来的切片 ID 指示出的切片数据库上。
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
(译注:这里的关系映射指前端业务对象间的关系用数据库表来运维,并不指我上节注释中说到的关系数据库的关系映射。作者开篇就讲到,由于切片,不能做关系数据库表间的关系映射的,如一对一,一对多,多对多等关系关联)
关系映射表是单向的,如 board_has_pins(板含便签)表方便根据 board (白板)ID查询其上有多少 Pin(钉便签)。若您需要根据 Pin(钉便签)ID查询其都在哪些 board(白板)上,您可另建个表 pin_owned_by_board(便签属于哪些白板)表,其中 sequence 字段表示 Pin 在 board 上的顺序号。(由于数据分布在切片数据库上,我们的 ID 本身无法表示其顺序)我们通常将一个新的 Pin 对象加到 board 上时,将其 sequence 设为当时的系统时间。sequence 可被设为任意整数,设为当时的系统时间,保证新建的对象的 sequence 总是大于旧对象的。这是个方便易行的方法。您可通过下面的语句从关系映射表中查询对象数据集:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
语句会查出50个 pin_ids(便签 ID ),随后可用这些对象 ID 查询其具体信息。
我们只在业务应用层进行这些关系的映射,如 board_id -> pin_ids -> pin objects (从 白板 ID -> 便签 IDs -> 便签对象)。 这种设计一个非常棒的特性是,您可以分开缓存这些关系映射对。例如,我们缓存 pin_id -> pin object (便签 ID -> 便签对象)关系映射在 memcache(内存缓存)集群服务器上,board_id -> pin_ids (白板 ID -> 便签 IDs)关系映射缓存在 redis 集群服务器上。这样,可以非常适合我们优化缓存技术策略。
增大服务能力
在我们的系统中,提升服务处理能力主要三个途径。最容易的是升级机器(更大的空间,更快的硬盘速度,更多的内存,无论什么解决系统瓶颈的升级都算)
另一个途径,扩大切片范围。最初,我们设计只切片了4096个数据库,相比我们设计的16位的切片 ID,还有许多空间,因为16位可表示65536个数。某些时间节点,若我们再提供8台机器运行8个 MySQL 数据库实例,提供从 4096 到 8192 的切片数据库,之后,新的数据将只往这个区间的切片数据库上存放。并行计算的数据库有16台,服务能力必然提升。
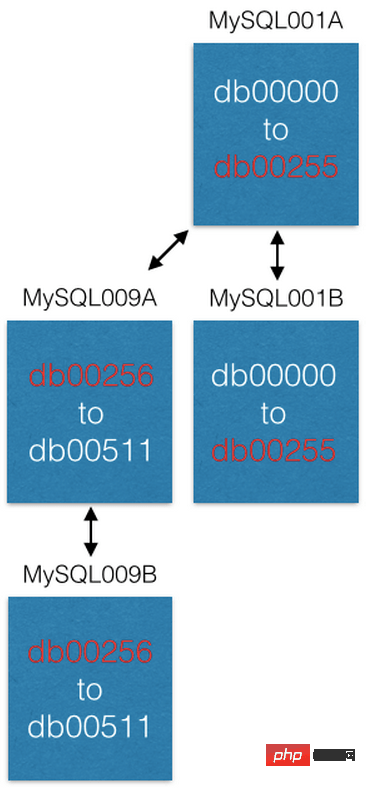
最后的途径,迁移切片数据库主机到新切片主机(局部切片扩容)以提升能力。例如,我们想将前例中的 MySQL001A 切片主机(其上是 0 到 511 编号的切片数据库)扩展分布到2台切片主机上。同我们设计地,我们创建一个新的 master-master 互备份主机对作为新切片主机(命名为 MySQL009A 和 B)并从 MySQL001A 上整体复制数据。

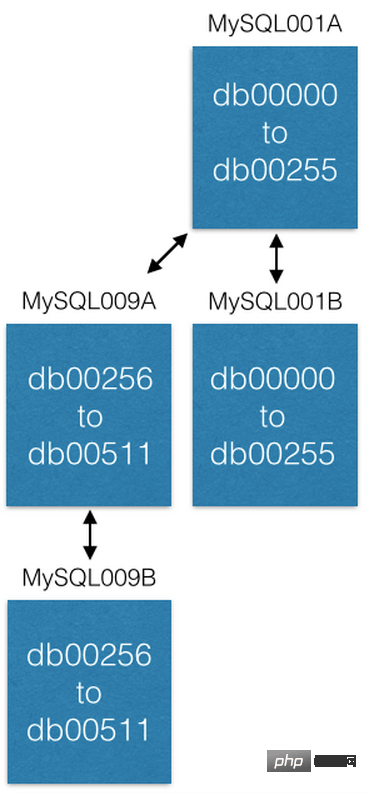
当数据复制完成后,我们修改切片配置,MySQL001A 只负责 0 到 255 的切片数据库,MySQL009A 只负责 256 到 511 的切片数据库。现在2台中每台主机只负责过去主机负责的一半的任务,服务能力提升。
一些特性说明
对于旧系统已产生的业务对象数据,要根据设计,对业务对象要生成它们在新系统中的 UUIDs,你应意识到它们放到哪儿(哪个切片数据库)由你决定。(译注:你可以规划旧数据在切片数据库上的分布)但是,在放入到切片数据库时,只有在插入记录时,数据库才会返回插入对象的 local ID,有了这个,才能构建对象的 UUID。
(译注:在迁移时要考虑好业务对象间关系的建立,通过UUID)
对于那些在已有大量数据的数据库表,曾使用过修改表结构类命令 (ALTERs)--诸如添加个字段之类的 -- 的人来说,您知道那是一个 非常 漫长和痛苦的过程。我们的设计是绝不使用 MySQL 上 ALTERs 级别的命令(当已有数据时)。在我们的业务系统 Pinterest 上,我们使用最后一个 ALTER 语句大概是在3年前了。 对于对象表中对象,如果您需要添加个对象属性字段,您添加到对象数据的 JOSON blob 字段里。您可以给新对象属性设定个默认值,当访问到旧对象的数据时,若旧对象没有新属性,您可以给其添加上新属性默认值。对于关系映射表来说,干脆,直接建立新的关系映射表以符合您的需要。这些您都清楚了!让您的系统扬帆起行吧!
模转(mod)数据库的切片
模转数据切片(mod shard)名称仅仅是像 Mod Squad,实则完全不同。
一些业务对象需要通过非 ID (non-ID)的方式查询访问。(译注: 此 ID 指之前设计说明中的64位 UUID)举例来说,如果一名 Pin友(Pinner)是以他(她)的 facebook 注册帐号注册登录我们的业务平台上的。我们需将其 facebook ID 与我们的 Pin友(Pinner)的 ID 映射。 facebook ID 对于我们系统只是一串二进制位的数。(译注:暗示我们不能像我们系统平台的设计那样解构别的平台的 ID,也谈不上如何设计切片,只是把它们保存起来,并设计使之与我们的 ID 映射)因此,我们需要保存它们,也需要把它们分别保存在切片数据库上。我们称之为模转数据切片(mod shard)其它的例子还包括 IP 地址、用户名和用户电子邮件等。
模转数据切片(mod shard)类似前述我们业务系统的数据切片设计。但是,你需要按照其输入的原样进行查询。如何确定其切片位置,需要用到哈希和模数运算。哈希函数将任意字串转换成定长数值,而模数设为系统已有切片数据库的切片数量,取模后,其必然落在某个切片数据库上。结果是其数据将保存在已有切片数据库上。举例:
shard = md5(“1.2.3.4") % 4096
(译注:mod shard 这个词,我网上找遍了,试图找到一个较准确权威的中文翻译!无果,因为 mod 这个词有几种意思,最近的是module 模块、模组,同时它也是模运算符(%)。我根据原文意思,翻译为 模转 。或可翻译为 模式,但个人感觉意思模糊。不当之处,请指正。另,原作者举的例子是以 IP 地址举例的,哈希使用的是 md5,相比其它,虽老但性能最好)
在这个例子中分片是1524。 我们维护一个类似于ID分片的配置文件:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”},
{“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”},
{“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”},
…]因此,为了找到 IP 为1.2.3.4的数据,我们将这样做:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
你失去了一些分片好的属性,例如空间位置。你必须从一开始就设置分片的密钥(它不会为你制作密钥)。最好使用不变的id来表示系统中的对象。这样,当用户更改其用户名时,您就不必更新许多引用。
最后的提醒
这个系统作为 Pinterest 的数据支撑已良好运行了3.5年,现在看来还会继续运行下去。设计实现这样的系统是直观、容易的。但是让它运行起来,尤其迁移旧数据却太不易了。若您的业务平台面临着急速增长的痛苦且您想切片自己的数据库。建议您考虑建立一个后端集群服务器(优先建议 pyres)脚本化您迁移旧数据到切片数据库的逻辑,自动化处理。我保证无论您想得多周到,多努力,您一定会丢数据或丢失数据之间的关联。我真的恨死隐藏在复杂数据关系中的那些捣蛋鬼。因此,您需要不断地迁移,修正,再迁移... 你需要极大的耐心和努力。直到您确定您不再需要为了旧数据迁移而往您的切片数据库中再操作数据为止。
这个系统的设计为了数据的分布切片,已尽最大的努力做到最好。它本身不能提供给你数据库事务 ACID 四要素中的 Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)哇呕!听起来很坏呀,不用担心。您可能不能利用数据库本身提供的功能很好地保证这些。但是,我提醒您,一切尽在您的掌握中,您只是让它运行起来,满足您的需要就好。设计简单直接就是王道,(译注:也许需要您做许多底层工作,但一切都在您的控制之中)主要是它运行起来超快! 如果您担心 A(原子性)、I(隔离性)和 C(一致性),写信给我,我有成堆的经验让您克服这些问题。
还有最后的问题,如何灾难恢复,啊哈? 我们创建另外的服务去维护着切片数据库,我们保存切片配置在 ZooKeeper 上。当单点主服务器宕掉时,我们有脚本自动地提升主服务器对应的从服务器立即顶上。之后,以最快的速度运行新机器顶上从服务器的缺。直至今日,我们从未使用过类似自动灾难恢复的服务。
The above is the detailed content of Pinterest MySQL practice uses sharding to solve the storage problem of tens of billions of data. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Why can't localstorage successfully save data?
Jan 03, 2024 pm 01:41 PM
Why can't localstorage successfully save data?
Jan 03, 2024 pm 01:41 PM
Why does storing data to localstorage always fail? Need specific code examples In front-end development, we often need to store data on the browser side to improve user experience and facilitate subsequent data access. Localstorage is a technology provided by HTML5 for client-side data storage. It provides a simple way to store data and maintain data persistence after the page is refreshed or closed. However, when we use localstorage for data storage, sometimes
 How to implement image storage and processing functions of data in MongoDB
Sep 22, 2023 am 10:30 AM
How to implement image storage and processing functions of data in MongoDB
Sep 22, 2023 am 10:30 AM
Overview of how to implement image storage and processing functions of data in MongoDB: In the development of modern data applications, image processing and storage is a common requirement. MongoDB, a popular NoSQL database, provides features and tools that enable developers to implement image storage and processing on its platform. This article will introduce how to implement image storage and processing functions of data in MongoDB, and provide specific code examples. Image storage: In MongoDB, you can use GridFS
 Learn about Aerospike caching technology
Jun 20, 2023 am 11:28 AM
Learn about Aerospike caching technology
Jun 20, 2023 am 11:28 AM
With the advent of the digital age, big data has become an indispensable part of all walks of life. As a solution for processing large-scale data, the importance of caching technology has become increasingly prominent. Aerospike is a high-performance caching technology. In this article, we will learn in detail about the principles, characteristics and application scenarios of Aerospike caching technology. 1. The principle of Aerospike caching technology Aerospike is a Key-Value database based on memory and flash memory. It uses
 How to implement polymorphic storage and multidimensional query of data in MySQL?
Jul 31, 2023 pm 09:12 PM
How to implement polymorphic storage and multidimensional query of data in MySQL?
Jul 31, 2023 pm 09:12 PM
How to implement polymorphic storage and multidimensional query of data in MySQL? In practical application development, polymorphic storage and multidimensional query of data are a very common requirement. As a commonly used relational database management system, MySQL provides a variety of ways to implement polymorphic storage and multidimensional queries. This article will introduce the method of using MySQL to implement polymorphic storage and multi-dimensional query of data, and provide corresponding code examples to help readers quickly understand and use it. 1. Polymorphic storage Polymorphic storage refers to the technology of storing different types of data in the same field.
 Yii framework middleware: providing multiple data storage support for applications
Jul 28, 2023 pm 12:43 PM
Yii framework middleware: providing multiple data storage support for applications
Jul 28, 2023 pm 12:43 PM
Yii framework middleware: providing multiple data storage support for applications Introduction Middleware (middleware) is an important concept in the Yii framework, which provides multiple data storage support for applications. Middleware acts like a filter, inserting custom code between an application's requests and responses. Through middleware, we can process, verify, filter requests, and then pass the processed results to the next middleware or final handler. Middleware in the Yii framework is very easy to use
 Interaction between Redis and Golang: How to achieve fast data storage and retrieval
Jul 30, 2023 pm 05:18 PM
Interaction between Redis and Golang: How to achieve fast data storage and retrieval
Jul 30, 2023 pm 05:18 PM
Interaction between Redis and Golang: How to achieve fast data storage and retrieval Introduction: With the rapid development of the Internet, data storage and retrieval have become important needs in various application fields. In this context, Redis has become an important data storage middleware, and Golang has become the choice of more and more developers because of its efficient performance and simplicity of use. This article will introduce readers to how to interact with Golang through Redis to achieve fast data storage and retrieval. 1.Re
 In the era of large AI models, new data storage bases promote the digital intelligence transition of education, scientific research
Jul 21, 2023 pm 09:53 PM
In the era of large AI models, new data storage bases promote the digital intelligence transition of education, scientific research
Jul 21, 2023 pm 09:53 PM
Generative AI (AIGC) has opened a new era of generalization of artificial intelligence. The competition around large models has become spectacular. Computing infrastructure is the primary focus of competition, and the awakening of power has increasingly become an industry consensus. In the new era, large models are moving from single-modality to multi-modality, the size of parameters and training data sets is growing exponentially, and massive unstructured data requires the support of high-performance mixed load capabilities; at the same time, data-intensive The new paradigm is gaining popularity, and application scenarios such as supercomputing and high-performance computing (HPC) are moving in depth. Existing data storage bases are no longer able to meet the ever-upgrading needs. If computing power, algorithms, and data are the "troika" driving the development of artificial intelligence, then in the context of huge changes in the external environment, the three urgently need to regain dynamic
 How to use C++ for efficient data compression and data storage?
Aug 25, 2023 am 10:24 AM
How to use C++ for efficient data compression and data storage?
Aug 25, 2023 am 10:24 AM
How to use C++ for efficient data compression and data storage? Introduction: As the amount of data increases, data compression and data storage become increasingly important. In C++, there are many ways to achieve efficient data compression and storage. This article will introduce some common data compression algorithms and data storage technologies in C++, and provide corresponding code examples. 1. Data compression algorithm 1.1 Compression algorithm based on Huffman coding Huffman coding is a data compression algorithm based on variable length coding. It does this by pairing characters with higher frequency
