

ThinkPHP database operation query method, query syntax, chain operation

The following tutorial column will introduce you to the query methods, query syntax, and chain operations of ThinkPHP database operations. I hope it will be helpful to friends in need! Query method
Conditional query method
where method
You can use the where method to perform AND condition query: Db::table('think_user') ->where('name','like','%thinkphp') ->where('status',1) ->find();
Db::table('think_user') ->where('name&title','like','%thinkphp') ->find();Use the whereOr method for OR query: Db::table('think_user') ->where('name','like','%thinkphp') ->whereOr('title','like','%thinkphp') ->find();
Db::table('think_user') ->where('name|title','like','%thinkphp') ->find();Mixed query
where method and whereOr method often need to be mixed together in complex query conditions. , here is an example: $result = Db::table('think_user')->where(function ($query) { $query->where('id', 1)->whereor('id', 2);
})->whereOr(function ($query) { $query->where('name', 'like', 'think')->whereOr('name', 'like', 'thinkphp');
})->select();
SELECT * FROM `think_user` WHERE ( `id` = 1 OR `id` = 2 ) OR ( `name` LIKE 'think' OR `name` LIKE 'thinkphp' )
Pay attention to the order in the closure query, and the first query method uses where or whereOr There is no difference.
getTableInfo method
Use getTableInfo to obtain table information. The information types include fields, type, bind, pk, and arrays. Format display, you can specify a certain information to obtain// 获取`think_user`表所有信息
Db::getTableInfo('think_user');
// 获取`think_user`表所有字段
Db::getTableInfo('think_user', 'fields');
// 获取`think_user`表所有字段的类型
Db::getTableInfo('think_user', 'type');
// 获取`think_user`表的主键
Db::getTableInfo('think_user', 'pk');
Query syntax
Query expression
Query expressions support most SQL query syntax and are the essence of ThinkPHP query language. The usage format of query expressions is: where('字段名','表达式','查询条件');
whereOr('字段名','表达式','查询条件');
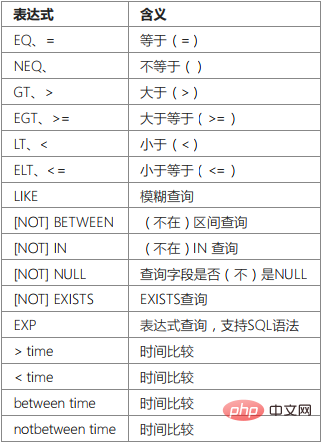
For example: where('id','eq',100);
where('id','=',100);
where('id',100);The query condition represented by
is id=100NEQ: not equal to ()
For example: where('id','neq',100);
where('id','<>',100);
##GET: greater than or equal to (>=)
For example: where('id','egt',100);
where('id','>=',100);
##LT: less than (< ;)
##For example: where('id','lt',100);
where('id','<',100);
##ELT: Less than or equal to (<=)
For example: where('id','elt',100);
where('id','<=',100);
[NOT] LIKE: Same as sql LIKE
##For example:
where('name','like','thinkphp%')
Query The condition becomes name like 'thinkphp%'Starting from version V5.0.5, like query supports using arrays
where('name','like',['%think','php%'],'OR');
For example:
where('id','between','1,8'); where('id','between',[1,8]);## 两条语句等效
The query condition becomes 'id BETWEEN 1 AND 8'
[NOT] IN: Same as sql [not] inFor example:
where('id','not in','1,5,8'); where('id','not in',[1,5,8]);## 两条语句等效
The query condition becomes 'id NOT IN (1,5,8)', '[NOT] IN' query supports the use of closure method
[NOT] NULL: Query whether the field is (not ) is `Null`
For example:
where('name', null); where('title','null'); where('name','not null');
where('title','=', 'null'); where('name','=', 'not null');
where('id','in','1,3,8');
where('id','exp',' IN (1,3,8) ');
`exp`查询的条件不会被当成字符串,所以后面的查询条件可以使用任何SQL支持的语法,包括使用函数和字段名称。
链式操作
数据库提供的链式操作方法,可以有效的提高数据存取的代码清晰度和开发效率,并且支持所有的CURD操作。
使用也比较简单,假如我们现在要查询一个User表的满足状态为1的前10条记录,并希望按照用户的创建时间 排序 ,代码如下:
Db::table('think_user') ->where('status',1) ->order('create_time') ->limit(10) ->select();这里的 where 、 order 和 limit 方法就被称之为链式操作方法,除了select方法必须放到最后一个外(因为select方法并不是链式操作方法),链式操作的方法调用顺序没有先后,例如,下面的代码和上面的等效:
Db::table('think_user') ->order('create_time') ->limit(10) ->where('status',1) ->select();其实不仅仅是查询方法可以使用连贯操作,包括所有的CURD方法都可以使用,例如:
Db::table('think_user') ->where('id',1) ->field('id,name,email') ->find();
Db::table('think_user') ->where('status',1) ->where('id',1) ->delete();链式操作在完成查询后会自动清空链式操作的所有传值。简而言之,链式操作的结果不会带入后面的其它查询。
系统支持的链式操作方法有:
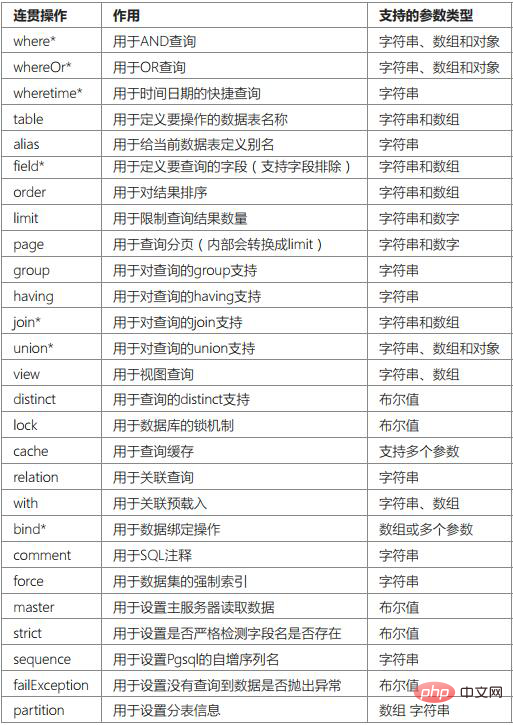
所有的连贯操作都返回当前的模型实例对象(this),其中带*标识的表示支持多次调用。
where
where方法的用法是ThinkPHP查询语言的精髓,也是ThinkPHP ORM的重要组成部分和亮点所在,可以完成包括普通查询、表达式查询、快捷查询、区间查询、组合查询在内的查询操作。where方法的参数支持字符串和数组,虽然也可以使用对象但并不建议。
表达式查询
新版的表达式查询采用全新的方式,查询表达式的使用格式:
Db::table('think_user') ->where('id','>',1) ->where('name','thinkphp') ->select();更多的表达式查询语法,可以参考查询语法部分。
数组条件
可以通过数组方式批量设置查询条件。
普通查询
最简单的数组查询方式如下:
$map['name'] = 'thinkphp';$map['status'] = 1;
// 把查询条件传入查询方法
Db::table('think_user')->where($map)->select();
// 助手函数
db('user')->where($map)->select();最后生成的SQL语句是
SELECT * FROM think_user WHERE `name`='thinkphp' AND status=1
表达式查询
可以在数组条件中使用查询表达式,例如:
$map['id'] = ['>',1];$map['mail'] = ['like','%thinkphp@qq.com%'];
Db::table('think_user')->where($map)->select();字符串条件
使用字符串条件直接查询和操作,例如:
Db::table('think_user')->where('type=1 AND status=1')->select();最后生成的SQL语句是
SELECT * FROM think_user WHERE type=1 AND status=1
使用字符串条件的时候,建议配合预处理机制,确保更加安全,例如:
Db::table('think_user')->where("id=:id and username=:name")->bind(['id'=>[1,\PDO::PARAM_INT],'name'=>'thinkphp'])->select();table
table方法主要用于指定操作的数据表。
一般情况下,操作模型的时候系统能够自动识别当前对应的数据表,所以,使用table方法的情况通常是为了:
1. 切换操作的数据表;
2. 对多表进行操作;
例如:
Db::table('think_user')->where('status>1')->select();也可以在table方法中指定数据库,例如:
Db::table('db_name.think_user')->where('status>1')->select();table方法指定的数据表需要完整的表名,但可以采用下面的方式简化数据表前缀的传入,例如:
Db::table('__USER__')->where('status>1')->select();会自动获取当前模型对应的数据表前缀来生成 think_user 数据表名称。
需要注意的是table方法不会改变数据库的连接,所以你要确保当前连接的用户有权限操作相应的数据库和数据表。 切换数据表后,系统会自动重新获取切换后的数据表的字段缓存信息。
如果需要对多表进行操作,可以这样使用:
Db::field('user.name,role.title')->table('think_user user,think_role role')->limit(10)->select();为了尽量避免和mysql的关键字冲突,可以建议使用数组方式定义,例如:
Db::field('user.name,role.title')->table(['think_user'=>'user','think_role'=>'role'])->limit(10)->select();使用数组方式定义的优势是可以避免因为表名和关键字冲突而出错的情况。
alias
alias用于设置当前数据表的别名,便于使用其他的连贯操作例如join方法等。
示例:
Db::table('think_user')->alias('a')->join('__DEPT__ b ','b.user_id= a.id')->select();最终生成的SQL语句类似于:
SELECT * FROM think_user a INNER JOIN think_dept b ON b.user_id= a.id
v5.0.2+ 版本开始,可以传入数组批量设置数据表以及别名,例如:
Db::table('think_user')->alias(['think_user'=>'user','think_dept'=>'dept'])->join('think_dept','dept.user_id= user.id')->select();最终生成的SQL语句类似于:
SELECT * FROM think_user user INNER JOIN think_dept dept ON dept.user_id= user.id
field
field方法属于模型的连贯操作方法之一,主要目的是标识要返回或者操作的字段,可以用于查询和写入操作。
用于查询
指定字段
在查询操作中field方法是使用最频繁的。
Db::table('think_user')->field('id,title,content')->select();这里使用field方法指定了查询的结果集中包含id,title,content三个字段的值。执行的SQL相当于:
SELECT id,title,content FROM table
可以给某个字段设置别名,例如:
Db::table('think_user')->field('id,nickname as name')->select();执行的SQL语句相当于:
SELECT id,nickname as name FROM table
使用SQL函数
可以在field方法中直接使用函数,例如:
Db::table('think_user')->field('id,SUM(score)')->select();执行的SQL相当于:
SELECT id,SUM(score) FROM table
除了select方法之外,所有的查询方法,包括find等都可以使用field方法。
使用数组参数
field方法的参数可以支持数组,例如:
Db::table('think_user')->field(['id','title','content'])->select();最终执行的SQL和前面用字符串方式是等效的。
数组方式的定义可以为某些字段定义别名,例如:
Db::table('think_user')->field(['id','nickname'=>'name'])->select();执行的SQL相当于:
SELECT id,nickname as name FROM table
对于一些更复杂的字段要求,数组的优势则更加明显,例如:
Db::table('think_user')->field(['id','concat(name,"-",id)'=>'truename','LEFT(title,7)'=>'sub_title'])->select();执行的SQL相当于:
SELECT id,concat(name,'-',id) as truename,LEFT(title,7) as sub_title FROM table
获取所有字段
如果有一个表有非常多的字段,需要获取所有的字段(这个也许很简单,因为不调用field方法或者直接使用空 的field方法都能做到):
Db::table('think_user')->select();
Db::table('think_user')->field('*')->select();上面的用法是等效的,都相当于执行SQL:
SELECT * FROM table
但是这并不是我说的获取所有字段,而是显式的调用所有字段(对于对性能要求比较高的系统,这个要求并不过分,起码是一个比较好的习惯),下面的用法可以完成预期的作用:
Db::table('think_user')->field(true)->select();field(true) 的用法会显式的获取数据表的所有字段列表,哪怕你的数据表有100个字段。
字段排除
如果我希望获取排除数据表中的 content 字段(文本字段的值非常耗内存)之外的所有字段值,我们就可 以使用field方法的排除功能,例如下面的方式就可以实现所说的功能:
Db::table('think_user')->field('content',true)->select();则表示获取除了content之外的所有字段,要排除更多的字段也可以:
Db::table('think_user')->field('user_id,content',true)->select();//或者用Db::table('think_user')->field(['user_id','content'],true)->select();注意:字段排除功能不支持跨表和join操作。
用于写入
除了查询操作之外,field方法还有一个非常重要的安全功能--字段合法性检测。field方法结合数据库的写入方法使用就可以完成表单提交的字段合法性检测,如果我们在表单提交的处理方法中使用了:
Db::table('think_user')->field('title,email,content')->insert($data);即表示表单中的合法字段只有 title , email 和 content 字段,无论用户通过什么手段更改或者添加了浏览器的提交字段,都会直接屏蔽。因为,其他是所有字段我们都不希望由用户提交来决定,你可以通过自动完成功能定义额外的字段写入。
order
order方法属于模型的连贯操作方法之一,用于对操作的结果排序。
用法如下:
Db::table('think_user')->where('status=1')->order('id desc')->limit(5)->select();注意:连贯操作方法没有顺序,可以在select方法调用之前随便改变调用顺序。
支持对多个字段的排序,例如:
Db::table('think_user')->where('status=1')->order('id desc,status')->limit(5)->select();如果没有指定desc或者asc排序规则的话,默认为asc。
如果你的字段和mysql关键字有冲突,那么建议采用数组方式调用,例如:
Db::table('think_user')->where('status=1')->order(['order','id'=>'desc'])->limit(5)->select();limit
limit方法也是模型类的连贯操作方法之一,主要用于指定查询和操作的数量,特别在分页查询的时候使用较多。
ThinkPHP的limit方法可以兼容所有的数据库驱动类的。
限制结果数量
例如获取满足要求的10个用户,如下调用即可:
Db::table('think_user') ->where('status=1') ->field('id,name') ->limit(10) ->select();limit方法也可以用于写操作,例如更新满足要求的3条数据:
Db::table('think_user') ->where('score=100') ->limit(3) ->update(['level'=>'A']);分页查询
用于文章分页查询是limit方法比较常用的场合,例如:
Db::table('think_article')->limit('10,25')->select();表示查询文章数据,从第10行开始的25条数据(可能还取决于where条件和order排序的影响 这个暂且不提。
你也可以这样使用,作用是一样的:
Db::table('think_article')->limit(10,25)->select();对于大数据表,尽量使用limit限制查询结果,否则会导致很大的内存开销和性能问题。
page
page方法也是模型的连贯操作方法之一,是完全为分页查询而诞生的一个人性化操作方法。
我们在前面已经了解了关于limit方法用于分页查询的情况,而page方法则是更人性化的进行分页查询的方法,例如还是以文章列表分页为例来说,如果使用limit方法,我们要查询第一页和第二页(假设我们每页输出10条数据)写法如下:
// 查询第一页数据
Db::table('think_article')->limit('0,10')->select();
// 查询第二页数据
Db::table('think_article')->limit('10,10')->select();虽然利用扩展类库中的分页类Page可以自动计算出每个分页的limit参数,但是如果要自己写就比较费力了,如果用page方法来写则简单多了,例如:
// 查询第一页数据
Db::table('think_article')->page('1,10')->select();
// 查询第二页数据
Db::table('think_article')->page('2,10')->select();显而易见的是,使用page方法你不需要计算每个分页数据的起始位置,page方法内部会自动计算。
和limit方法一样,page方法也支持2个参数的写法,例如:
Db::table('think_article')->page(1,10)->select();
// 和下面的用法等效
Db::table('think_article')->page('1,10')->select();page方法还可以和limit方法配合使用,例如:
Db::table('think_article')->limit(25)->page(3)->select();当page方法只有一个值传入的时候,表示第几页,而limit方法则用于设置每页显示的数量,也就是说上面的写法等同于:
Db::table('think_article')->page('3,25')->select();group
GROUP方法也是连贯操作方法之一,通常用于结合合计函数,根据一个或多个列对结果集进行分组。
group方法只有一个参数,并且只能使用字符串。
例如,我们都查询结果按照用户id进行分组统计:
Db::table('think_user') ->field('user_id,username,max(score)') ->group('user_id') ->select();生成的SQL语句是:
SELECT user_id,username,max(score) FROM think_score GROUP BY user_id
也支持对多个字段进行分组,例如:
Db::table('think_user') ->field('user_id,test_time,username,max(score)') ->group('user_id,test_time') ->select();生成的SQL语句是:
SELECT user_id,test_time,username,max(score) FROM think_score GROUP BY user_id,test_time
having
HAVING方法也是连贯操作之一,用于配合group方法完成从分组的结果中筛选(通常是聚合条件)数据。
having方法只有一个参数,并且只能使用字符串,例如:
Db::table('think_user') ->field('username,max(score)') ->group('user_id') ->having('count(test_time)>3') ->select();生成的SQL语句是:
SELECT username,max(score) FROM think_score GROUP BY user_id HAVING count(test_time)>3
join
join通常有下面几种类型,不同类型的join操作会影响返回的数据结果。
- INNER JOIN: 等同于 JOIN(默认的JOIN类型),如果表中有至少一个匹配,则返回行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
说明
object join ( mixed join [, mixed $condition = null [, string $type = 'INNER']] )
JOIN方法也是连贯操作方法之一,用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
参数
join
要关联的(完整)表名以及别名
支持三种写法:
- 写法1:[ '完整表名或者子查询'=>'别名' ]
- 写法2:'完整表名 别名'
- 写法3:'不带数据表前缀的表名'
condition
关联条件。可以为字符串或数组, 为数组时每一个元素都是一个关联条件。
type
关联类型。可以为:INNER、LEFT、RIGHT、FULL,不区分大小写,默认为INNER。
返回值
模型对象
举例
Db::table('think_artist') ->alias('a') ->join('think_work w','a.id = w.artist_id') ->join('think_card c','a.card_id = c.id') ->select();
Db::table('think_artist') ->alias('a') ->join('__WORK__ w','a.id = w.artist_id') ->join('__CARD__ c','a.card_id = c.id') ->select();$join = [
['think_work w','a.id=w.artist_id'],
['think_card c','a.card_id=c.id'],];
Db::table('think_user')->alias('a')->join($join)->select();以上三种写法的效果一样, __WORK__ 和__CARD__ 在最终解析的时候会转换为 think_work 和 think_card 。注意:'_表名_'这种方式中间的表名需要用大写
如果不想使用别名,后面的条件就要使用表全名,可以使用下面这种方式
Db::table('think_user')->join('__WORK__','__ARTIST__.id = __WORK__.artist_id')->select();默认采用INNER JOIN 方式,如果需要用其他的JOIN方式,可以改成
Db::table('think_user')->alias('a')->join('word w','a.id = w.artist_id','RIGHT')->select();表名也可以是一个子查询
$subsql = Db::table('think_work')->where(['status'=>1])->field('artist_id,count(id) count')->group('artist_id')->buildSql();
Db::table('think_user')->alias('a')->join([$subsql=> 'w'], 'a.artist_id = w.artist_id')->select();因buildSql返回的语句带有(),所以这里不需要在两端再加上()。
union
UNION操作用于合并两个或多个 SELECT语句的结果集。
使用示例:
Db::field('name') ->table('think_user_0') ->union('SELECT name FROM think_user_1') ->union('SELECT name FROM think_user_2') ->select();闭包用法:
Db::field('name') ->table('think_user_0') ->union(function($query){ $query->field('name')->table('think_user_1');
}) ->union(function($query){ $query->field('name')->table('think_user_2');
}) ->select();或者
Db::field('name'->table('think_user_0'->union(['SELECT name FROM think_user_1','SELECT name FROM think_user_2'])
->select();支持UNION ALL 操作,例如:
Db::field('name') ->table('think_user_0') ->union('SELECT name FROM think_user_1',true) ->union('SELECT name FROM think_user_2',true) ->select();或者
Db::field('name') ->table('think_user_0') ->union(['SELECT name FROM think_user_1','SELECT name FROM think_user_2'],true) ->select();每个union方法相当于一个独立的SELECT语句。
注意:UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条SELECT 语句中的列的顺序必须相同。
distinct
DISTINCT 方法用于返回唯一不同的值 。
例如数据库表中有以下数据
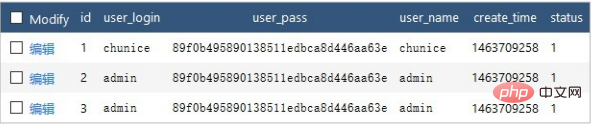
以下代码会返回 user_login 字段不同的数据
Db::table('think_user')->distinct(true)->field('user_login')->select();生成的SQL语句是:
SELECT DISTINCT user_login FROM think_user
返回以下数组
array(2) {
[0] => array(1) {
["user_login"] => string(7) "chunice"
}
[1] => array(1) {
["user_login"] => string(5) "admin"
}
}distinct方法的参数是一个布尔值。
lock
Lock方法是用于数据库的锁机制,如果在查询或者执行操作的时候使用:
lock(true);
就会自动在生成的SQL语句最后加上 FOR UPDATE 或者 FOR UPDATE NOWAIT (Oracle数据库)。
cache
cache方法用于查询缓存操作,也是连贯操作方法之一。 cache可以用于 select 、 find 、 value 和 column 方法,以及其衍生方法,使用 cache 方法后,在缓存有效期之内不会再次进行数据库查询操作,而是直接获取缓存中的数据,关于数据缓存的类型和设置可以参考缓存部分。
下面举例说明,例如,我们对find方法使用cache方法如下:
Db::table('think_user')->where('id=5')->cache(true)->find();第一次查询结果会被缓存,第二次查询相同的数据的时候就会直接返回缓存中的内容,而不需要再次进行数据库查询操作。
默认情况下, 缓存有效期是由默认的缓存配置参数决定的,但 cache 方法可以单独指定,例如:
Db::table('think_user')->cache(true,60)->find();
// 或者使用下面的方式 是等效的
Db::table('think_user')->cache(60)->find();表示对查询结果的缓存有效期60秒。
cache方法可以指定缓存标识:
Db::table('think_user')->cache('key',60)->find();指定查询缓存的标识可以使得查询缓存更有效率。
这样,在外部就可以通过 \think\Cache 类直接获取查询缓存的数据,例如:
$result = Db::table('think_user')->cache('key',60)->find();$data = \think\Cache::get('key');cache 方法支持设置缓存标签,例如:
Db::table('think_user')->cache('key',60,'tagName')->find();缓存自动更新
这里的缓存自动更新是指一旦数据更新或者删除后会自动清理缓存(下次获取的时候会自动重新缓存)。
当你删除或者更新数据的时候,可以使用cache方法手动更新(清除)缓存,例如:
Db::table('think_user')->cache('user_data')->select([1,3,5]);
Db::table('think_user')->cache('user_data')->update(['id'=>1,'name'=>'thinkphp']);
Db::table('think_user')->cache('user_data')->select([1,5]);最后查询的数据不会受第一条查询缓存的影响,确保查询和更新或者删除使用相同的缓存标识才能自动清除缓存。
如果使用 find 方法并且使用主键查询的情况,不需要指定缓存标识,会自动清理缓存,例如:
Db::table('think_user')->cache(true)->find(1);
Db::table('think_user')->update(['id'=>1,'name'=>'thinkphp']);
Db::table('think_user')->cache(true)->find(1);最后查询的数据会是更新后的数据。
comment
COMMENT方法 用于在生成的SQL语句中添加注释内容,例如:
Db::table('think_score')->comment('查询考试前十名分数') ->field('username,score') ->limit(10) ->order('score desc') ->select();最终生成的SQL语句是:
SELECT username,score FROM think_score ORDER BY score desc LIMIT 10 /* 查询考试前十名分数*/
fetchSql
fetchSql用于直接返回SQL而不是执行查询,适用于任何的CURD操作方法。 例如:
$result = Db::table('think_user')->fetchSql(true)->find(1);输出result结果为:
SELECT * FROM think_user where id = 1
force
force 方法用于数据集的强制索引操作,例如:
Db::table('think_user')->force('user')->select();对查询强制使用user索引,user必须是数据表实际创建的索引名称。
bind
bind方法用于手动参数绑定,大多数情况,无需进行手动绑定,系统会在查询和写入数据的时候自动使用参数绑定。
bind方法用法如下:
// 用于查询
Db::table('think_user') ->where('id',':id') ->where('name',':name')
->bind(['id'=>[10,\PDO::PARAM_INT],'name'=>'thinkphp']) ->select();
// 用于写入
Db::table('think_user') ->bind(['id'=>[10,\PDO::PARAM_INT],'email'=>'thinkphp@qq.com','name'=>'thinkphp']) ->where('id',':id') ->update(['name'=>':name','email'=>':email');partition
partition 方法用于是数据库水平分表
partition($data, $field, $rule);// $data 分表字段的数据 // $field 分表字段的名称 // $rule 分表规则
注意:不要使用任何 SQL 语句中会出现的关键字当表名、字段名,例如 order 等。会导致数据模型拼装 SQL 语句语法错误。
partition 方法用法如下:
// 用于写入$data = [ 'user_id' => 110,
'user_name' => 'think'];$rule = [ 'type' => 'mod',
// 分表方式
'num' => 10
// 分表数量
];
Db::name('log') ->partition(['user_id' => 110], "user_id", $rule) ->insert($data);
// 用于查询Db::name('log') ->partition(['user_id' => 110], "user_id", $rule)
->where(['user_id' => 110]) ->select();strict
strict 方法用于设置是否严格检查字段名,用法如下:
// 关闭字段严格检查
Db::name('user') ->strict(false) ->insert($data);注意,系统默认值是由数据库配置参数 fields_strict 决定,因此修改数据库配置参数可以进行全局的严格检查配置,如下:
// 关闭严格检查字段是否存在'fields_strict' => false,
如果开启字段严格检查的话,在更新和写入数据库的时候,一旦存在非数据表字段的值,则会抛出异常。
failException
failException 设置查询数据为空时是否需要抛出异常,如果不传入任何参数,默认为开启,用于 select 和 find方法,例如:
// 数据不存在的话直接抛出异常
Db:name('blog')->where(['status' => 1])->failException()->select();
// 数据不存在返回空数组 不抛异常
Db:name('blog')->where(['status' => 1])->failException(false)->select();或者可以使用更方便的查空报错
// 查询多条
Db:name('blog')->where(['status' => 1])->selectOrFail();
// 查询单条
Db:name('blog')->where(['status' => 1])->findOrFail();sequence
sequence 方法用于 pgsql 数据库指定自增序列名,其它数据库不必使用,用法为:
Db::name('user')->sequence('id')->insert(['name'=>'thinkphp']);The above is the detailed content of ThinkPHP database operation query method, query syntax, chain operation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to run thinkphp project
Apr 09, 2024 pm 05:33 PM
How to run thinkphp project
Apr 09, 2024 pm 05:33 PM
To run the ThinkPHP project, you need to: install Composer; use Composer to create the project; enter the project directory and execute php bin/console serve; visit http://localhost:8000 to view the welcome page.
 There are several versions of thinkphp
Apr 09, 2024 pm 06:09 PM
There are several versions of thinkphp
Apr 09, 2024 pm 06:09 PM
ThinkPHP has multiple versions designed for different PHP versions. Major versions include 3.2, 5.0, 5.1, and 6.0, while minor versions are used to fix bugs and provide new features. The latest stable version is ThinkPHP 6.0.16. When choosing a version, consider the PHP version, feature requirements, and community support. It is recommended to use the latest stable version for best performance and support.
 How to run thinkphp
Apr 09, 2024 pm 05:39 PM
How to run thinkphp
Apr 09, 2024 pm 05:39 PM
Steps to run ThinkPHP Framework locally: Download and unzip ThinkPHP Framework to a local directory. Create a virtual host (optional) pointing to the ThinkPHP root directory. Configure database connection parameters. Start the web server. Initialize the ThinkPHP application. Access the ThinkPHP application URL and run it.
 Development suggestions: How to use the ThinkPHP framework to implement asynchronous tasks
Nov 22, 2023 pm 12:01 PM
Development suggestions: How to use the ThinkPHP framework to implement asynchronous tasks
Nov 22, 2023 pm 12:01 PM
"Development Suggestions: How to Use the ThinkPHP Framework to Implement Asynchronous Tasks" With the rapid development of Internet technology, Web applications have increasingly higher requirements for handling a large number of concurrent requests and complex business logic. In order to improve system performance and user experience, developers often consider using asynchronous tasks to perform some time-consuming operations, such as sending emails, processing file uploads, generating reports, etc. In the field of PHP, the ThinkPHP framework, as a popular development framework, provides some convenient ways to implement asynchronous tasks.
 Which one is better, laravel or thinkphp?
Apr 09, 2024 pm 03:18 PM
Which one is better, laravel or thinkphp?
Apr 09, 2024 pm 03:18 PM
Performance comparison of Laravel and ThinkPHP frameworks: ThinkPHP generally performs better than Laravel, focusing on optimization and caching. Laravel performs well, but for complex applications, ThinkPHP may be a better fit.
 How to install thinkphp
Apr 09, 2024 pm 05:42 PM
How to install thinkphp
Apr 09, 2024 pm 05:42 PM
ThinkPHP installation steps: Prepare PHP, Composer, and MySQL environments. Create projects using Composer. Install the ThinkPHP framework and dependencies. Configure database connection. Generate application code. Launch the application and visit http://localhost:8000.
 How is the performance of thinkphp?
Apr 09, 2024 pm 05:24 PM
How is the performance of thinkphp?
Apr 09, 2024 pm 05:24 PM
ThinkPHP is a high-performance PHP framework with advantages such as caching mechanism, code optimization, parallel processing and database optimization. Official performance tests show that it can handle more than 10,000 requests per second and is widely used in large-scale websites and enterprise systems such as JD.com and Ctrip in actual applications.
 Development suggestions: How to use the ThinkPHP framework for API development
Nov 22, 2023 pm 05:18 PM
Development suggestions: How to use the ThinkPHP framework for API development
Nov 22, 2023 pm 05:18 PM
Development suggestions: How to use the ThinkPHP framework for API development. With the continuous development of the Internet, the importance of API (Application Programming Interface) has become increasingly prominent. API is a bridge for communication between different applications. It can realize data sharing, function calling and other operations, and provides developers with a relatively simple and fast development method. As an excellent PHP development framework, the ThinkPHP framework is efficient, scalable and easy to use.
