

MYSQL advanced for big data learning

Free learning recommendations: mysql video tutorial
Article Directory
- 1 Several aspects that affect performance
- 1.1 Hardware aspects
- 1.2 Server system
- 1.3 Database storage Engine selection
- 1.4 Database parameter configuration
- 1.5 Database structure design and SQL statements (key points)
- 2 Hardware aspects
-
- 2.1 CPU resources and available memory size
- 2.1.1 How to choose CPU
- 2.1.2 Memory
- 2.1.2.1 Commonly used MySQL storage engines
- 2.1.2.2 Tips
- 2.1.2.3 How to choose memory
- 2.2 Disk configuration and selection
- 2.2.1 Using traditional machine hard disks
- 2.2.2 Using RAID to enhance the performance of traditional machine hard disks
- 2.2.2.1 What is RAID
- 2.2.2.2 RAID Level
- 2.2.2.2.1 RAID 0
- 2.2.2.2. 2 RAID 1
- 2.2.2.2.3 RAID 5 - Common RAID groups
- 2.2.2.2.4 RAID 10 - Common RAID groups
- 2.2.2.3 Selection of RAID level
- 2.2.3 Using solid-state storage SSD and PCIe card
- 2.2.4 Using network storage NAS and SAN
- 2.2.4.1 Network storage usage scenarios
- 2.2.4.2 Network performance limitations
- 2.2.4.3 Network impact on performance
- 2.3 Summary
- 3 Impact of operating system on performance
- 3.1 CentOS system Parameter optimization
- 4 The impact of file system on performance
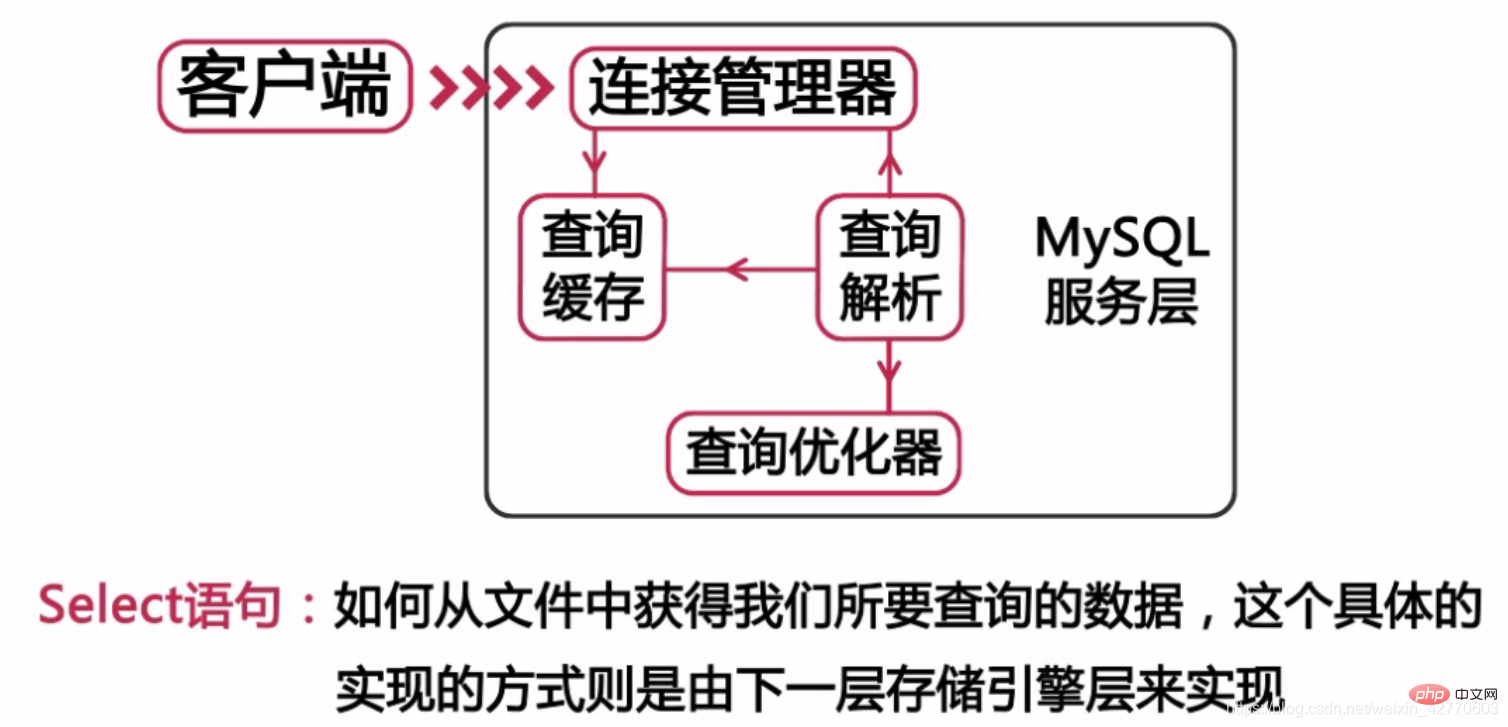
- 5 MySQL architecture
1 Several aspects that affect performance
1.1 Hardware aspect
Usually personal computers are slow, and we all say it is because of computer hardware problems, usually factors such as CPU, memory, disk IO, etc. , so this problem will also occur on the server.
1.2 Server system
Generally, the operating system of personal computers is windows. The performance of different versions of windows systems is different, or certain parameters are configured to cause performance s difference. This is the same for server systems, and parameter settings will also affect server performance.
1.3 Selection of database storage engine
MySQL has a plug-in storage engine, and different storage engines can be selected according to different business needs.
Different storage engines also have different characteristics:
- MyISAM: does not support transactions and table-level locks.
- InnoDB: transaction-level storage engine, perfectly supports row-level locks and transaction ACID features.
1.4 Database parameter configuration
For different storage engines, their parameter configurations are different. Some parameters have minimal impact on the storage engine, but Some parameters play a decisive role in performance. Therefore, it is also important to optimize parameters based on the selected storage engine and different business needs.
1.5 Database structure design and SQL statements (key points)
When we design the database structure, we should consider what kind of sql statements we will execute on the database in the future. , to query and update the table structure. Only in this way can a table structure that meets the requirements be designed.
For slow queries, it is the main culprit of low performance, and it is caused by our unreasonable design of the database table structure. This type of SQL is also the most difficult to optimize, because once the project is online, it is difficult to modify the database table structure.
Therefore, our focus on optimizing database performance is:
Database table structure design
Preparation and optimization of SQL statements
The following is a detailed description of each aspect.
2 Hardware aspects
2.1 CPU resources and available memory size
2.1.1 How to choose CPU
Usually when choosing a CPU, we all hope that the frequency and number of cores of the CPU are both as high as possible, but due to cost or various factors, we are often forced to choose only one of them. So how should we choose the best solution? Therefore, we need to pay attention to several issues when purchasing a CPU:
- Is our application CPU intensive?
- If our application is CPU-intensive, to speed up sql processing, obviously we need better CPUs, not more CPUs.
- For the current MySQL, duoCPU does not support concurrent processing of the same SQL.
- What is the concurrency of our system?
- If our system needs more throughput, then the more CPUs we have, the better. Assuming we have 40 CPUs, can we process 40 SQLs at the same time?
- Measurement of database processing capabilities: QPS, which refers to the number of SQLs processed simultaneously. But this indicator is the number of SQLs processed in 1s, but the simultaneous processing explained in the previous point is in the nanosecond dimension.
- MySQL is usually used in web applications, and the amount of concurrency is often relatively large. At this time, the number of CPUs is more important than the CPU frequency.
- The version of MySQL we use
- Before version 5.0, MySQL did not have good support for multi-core CPUs, and the restrictions on the system were very serious. In the current 5.6 and 5.7 versions, the support for multi-core CPUs has been greatly improved. Therefore, it is recommended to use the latest version of MySQL to achieve better performance.
- Choose 32-bit or 64-bit CPU?
- Currently, server CPUs are all 64-bit architecture by default, but be careful to check whether the system has a 32-bit server version installed on top of the 64-bit system. This will seriously affect server performance.
2.1.2 Memory
The size of the memory directly affects the performance of the database. Memory is currently much more efficient than disk. Therefore, caching data into memory can greatly improve server performance.
2.1.2.1 Commonly used MySQL storage engines
There are two commonly used storage engines: MyISAM and InnoDB.
MyISAM:
The index is stored in memory and the data is saved on the hard disk. 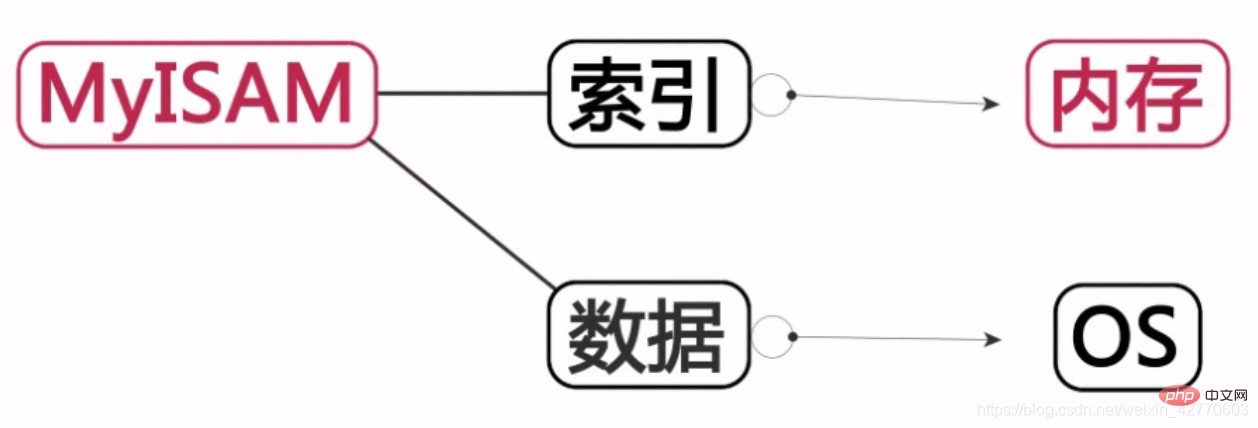
InnoDB:
Indexes and data are stored in memory, thereby improving the operating efficiency of the database. 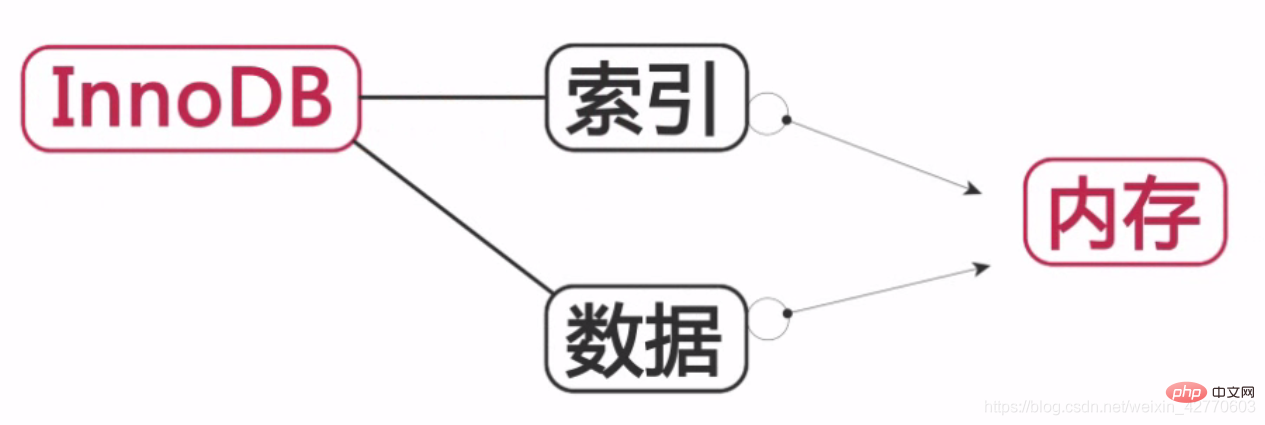
2.1.2.2 Tips
- Although the more memory, the better, the impact on system performance is limited.
If the data in our database is 100G, then the maximum performance can be achieved by selecting the memory around 128G. At this time, if all the data is hot data, it will be cached in the memory. There is no need to use 256G memory. However, choosing larger memory will also improve the performance of other services such as the operating system, and there is no need to consider upgrading the memory in the short term. - For memory cache write operations, you can delay writing to reduce the pressure on the database.
Memory already has good support for read operations, and write operations can also be completed in memory. In the end, we need to write data to the disk. Although we cannot avoid the operation of writing to the disk, we can Delay write operations and merge multiple writes into one write to reduce the pressure on the database. The database provides a similar function, which can merge multiple write operations into one in the cache pool and finally write them to the disk.
2.1.2.3 How to choose memory
Try to use the memory that the motherboard can support the maximum frequency
- To form a purchase upgrade, the memory of each channel should be of the same brand, particle size, frequency, voltage, verification technology and model.
- Select memory based on database size.
2.2 Disk configuration and selection
Although memory plays a big role in database performance, we cannot ignore the impact of the IO subsystem on performance. . At present, we commonly use the following 4 types of disk options:
2.2.1 Using traditional machine hard drives
Features: Large storage space, low price, most used, most common , reading and writing are slow
- How to choose a traditional machine hard disk?
- Storage capacity
- Transmission speed
- Access time
- Spindle speed
- Physical size
2.2.2 Use RAID to enhance the performance of traditional machine hard drives
2.2.2.1 What is RAID
RAID is disk redundancy The abbreviation of Redundant Arrays of Independent Disks. Simply put, the function of RAID is to combine multiple disks with smaller capacity into a group of disks with larger capacity and provide data redundancy to ensure data integrity.
2.2.2.2 RAID Level
##2.2.2.2.1 RAID 0
RAID 0 is the earliest RAID mode, also called data striping. It is the simplest form among component disk arrays. It only requires more than 2 hard disks. It is low cost and can improve the performance and throughput of the entire disk. RAID 0 does not provide redundancy or error recovery capabilities, but is the lowest cost to implement. However, when considering data recovery and reliability factors, RAID 0 has become the most expensive configuration, because there is no redundancy in RAID 0, and the probability of data damage is higher than in a single disk. Because data damage in any disk will cause data loss. For example, a RAID 0 consisting of three disks is three times more likely to be damaged than a single hard disk.
Therefore, RAID 0 is suitable for situations where no single data will be lost, such as: a standby database that can be cloned from other databases at any time or some databases that only need to be used once. 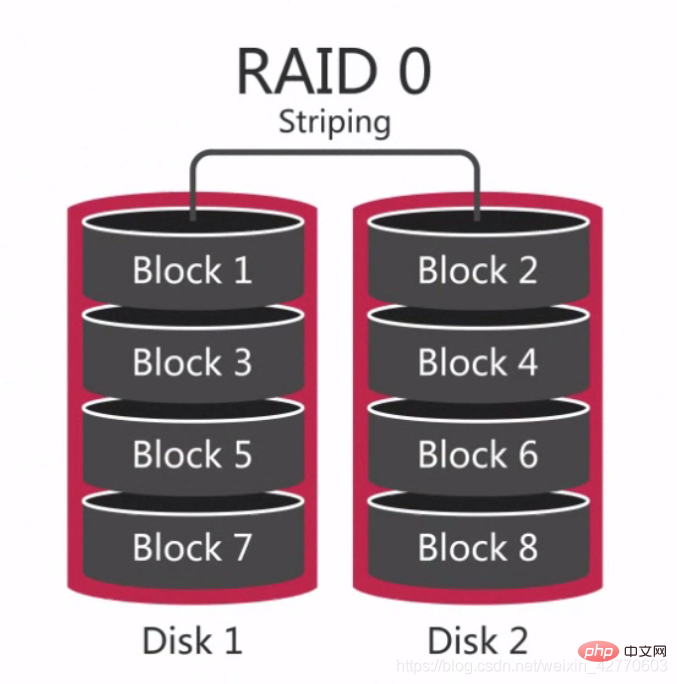
Simply put, RAID 0 is to connect hard disks in series to form a larger disk, such as: 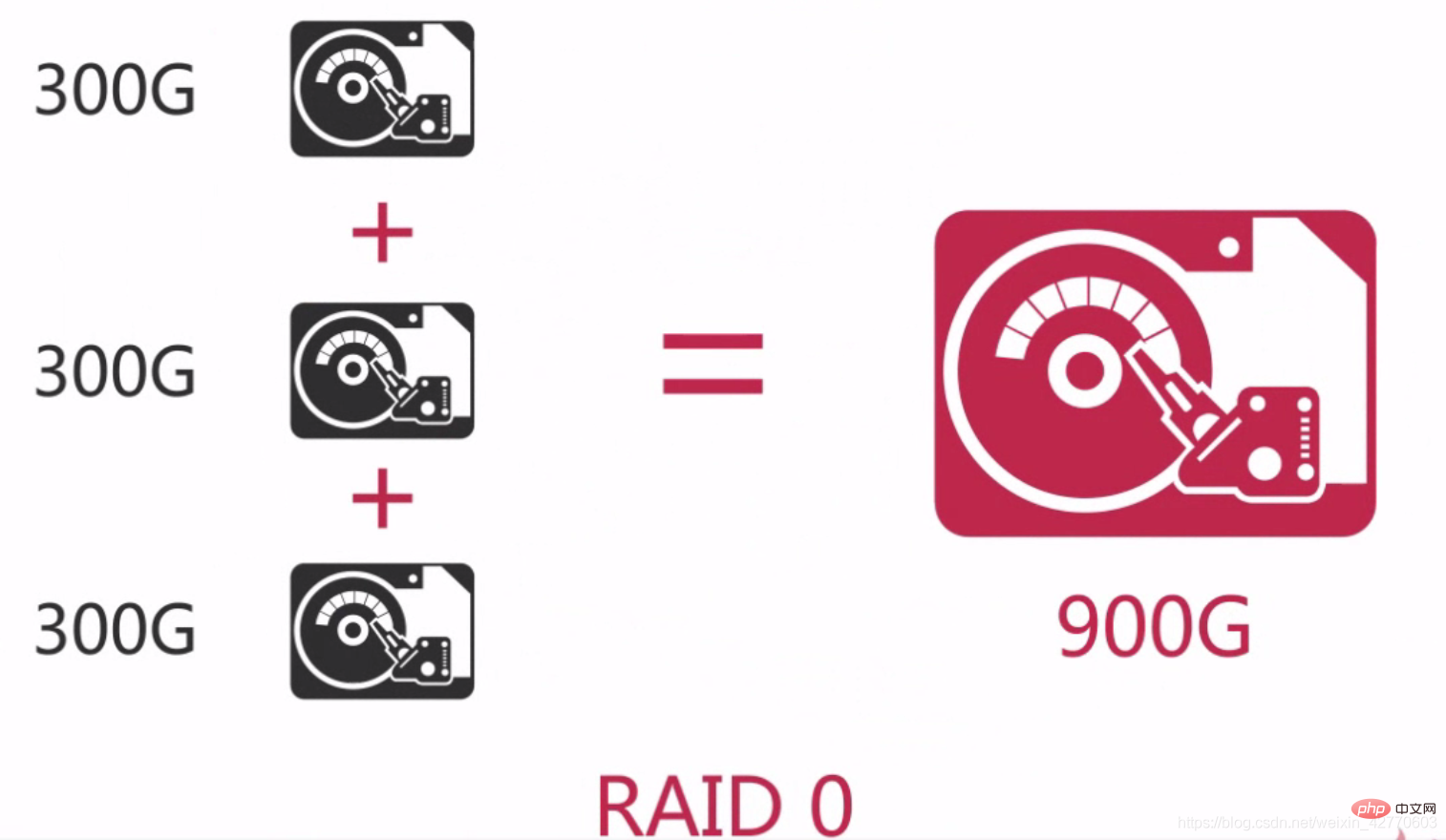
And in the concurrent process, it can reach the equivalent of 3x the performance of a single hard drive.
2.2.2.2.2 RAID 1
RAID 1 is also called disk mirroring. The principle is to mirror the data of one disk to another disk, that is to say, the data While writing to one disk, an image file will be generated on another restricted disk to ensure the reliability and repairability of the system to the greatest extent without affecting performance.
The difference between it and RAID 0 is that an equal sign is drawn in the middle. The data on both disks are the same and have good redundancy capabilities, but the cost will increase accordingly. When a disk failure occurs, it can run normally, but the failed disk needs to be replaced, otherwise the system will crash. 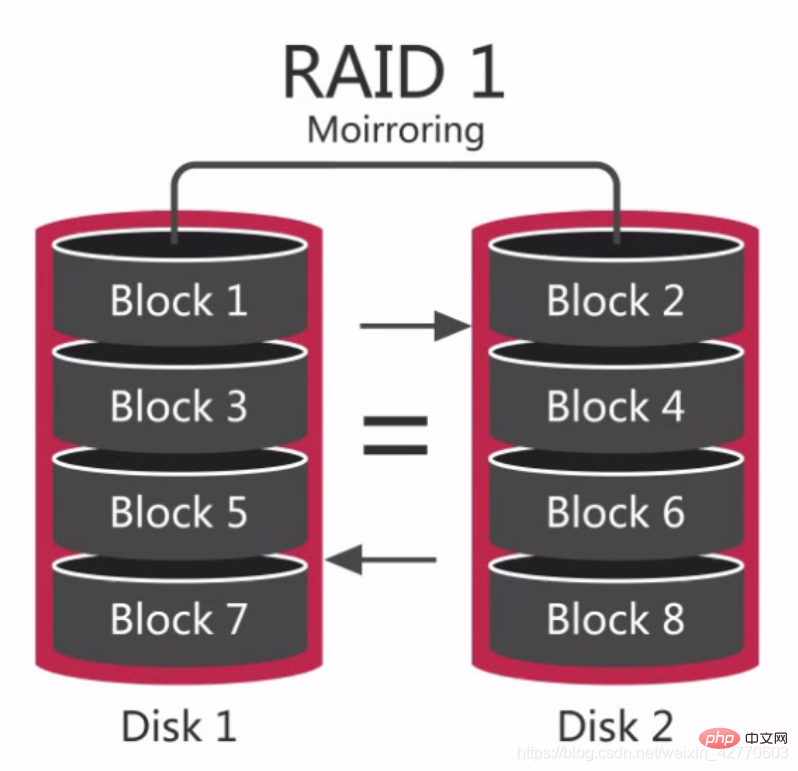 After replacing a new disk, data synchronization will take a lot of time. Although it will not affect data access, the system performance will be reduced.
After replacing a new disk, data synchronization will take a lot of time. Although it will not affect data access, the system performance will be reduced.
RAID 1 can provide good
read
performance in many cases, and redundant data between different disks, so the data redundancy is very good. RAID 1 is better at reading than RAID 0, so it is more suitable for storing logs or similar tasks. 2.2.2.2.3 RAID 5 - Common RAID group
RAID 5 is also called a distributed parity disk array. The
data is spread across multiple disks through distributed parity blocks, so that if any disk data fails, it can be reconstructed from the parity blocks. But if two disks fail, the entire volume's data cannot be recovered.
It can be seen that each disk has Dp, Cp, Bp, and Ap respectively. If there is a problem with one of the disks, the disk can be recalculated based on the data and parity values of the other three disks. The data. 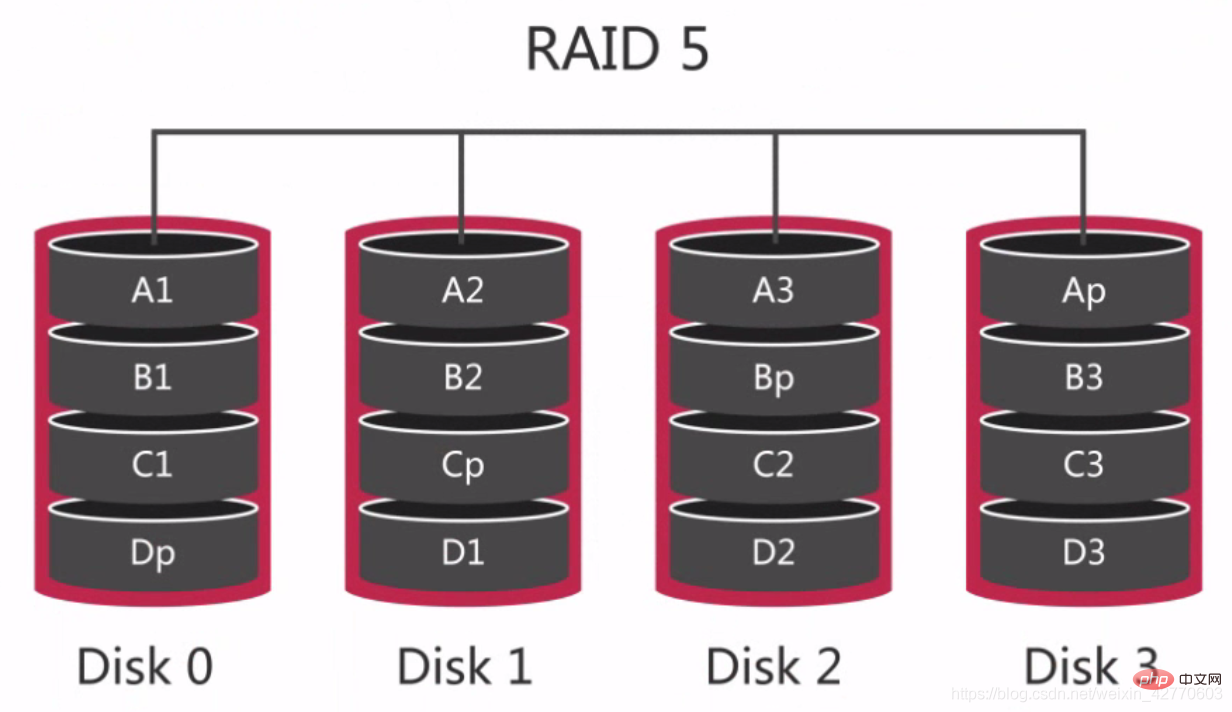 For RAID 0 and RAID 1, this is the most economical redundant configuration, because the entire array configuration only requires the capacity of one disk.
For RAID 0 and RAID 1, this is the most economical redundant configuration, because the entire array configuration only requires the capacity of one disk.
Writes are slower on RAID 5 because each write requires 2 reads and 2 writes between disks to calculate the value of the stored parity digit, however, both random and sequential reads are fast , because there is no need to calculate parity bits when reading, so RAID 5 is more suitable for read-oriented database services.
The biggest problem that occurs with RAID 5 is when the disk fails, because the data needs to be reallocated to other disks, which will seriously affect the performance of the disk, so it is best to use RAID 5 in the case of re-reading.
2.2.2.2.4 RAID 10 - Commonly used RAID groups
RAID 10 is also called sharded mirroring. It first performs RAID 1 on the disks and then performs RAID 0 on the two sets of RAID 1 disks, so it has good performance in reading and writing. Compared with RAID 5, it is easier to rebuild and faster.
On RAID 10, if one hard disk is damaged, it will have a serious impact on performance, because during the read and write process, two adjacent disks can be read at the same time. If one is damaged, then only reads can be made from a single disk, so in the worst case, our performance will be reduced by 50%. 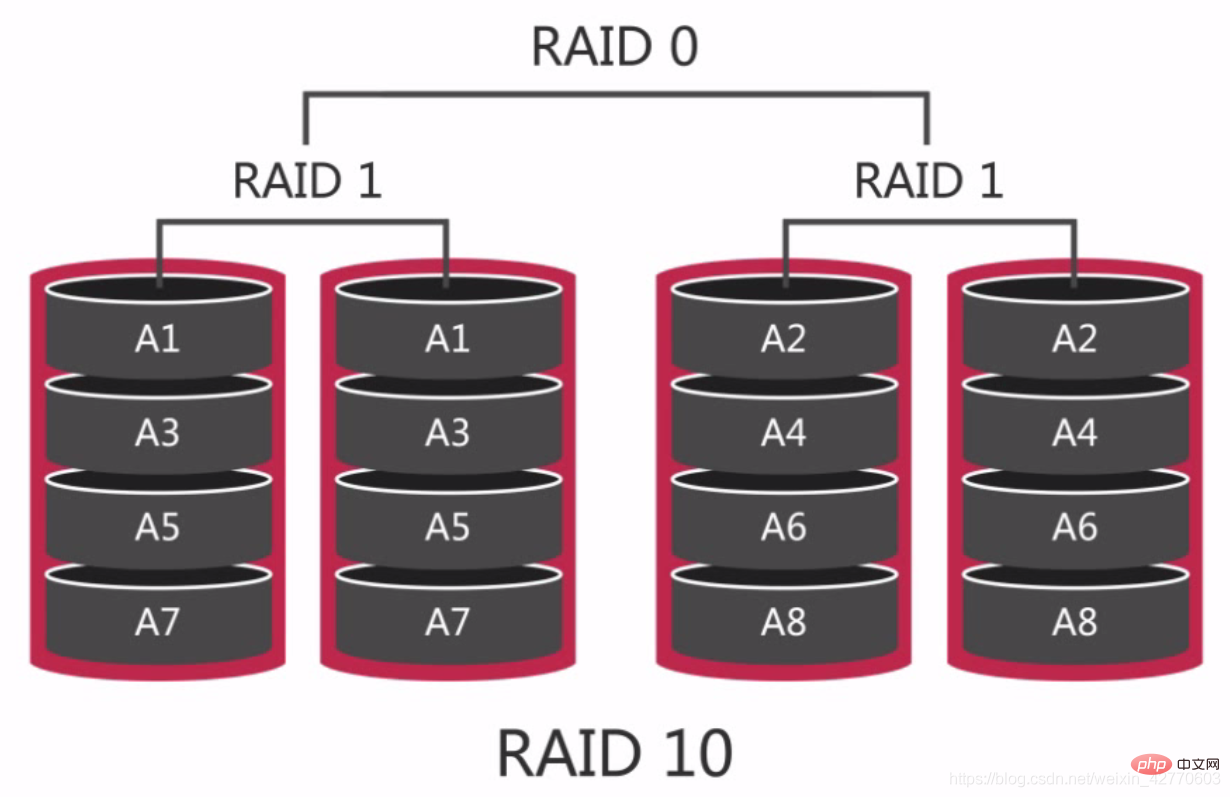
2.2.2.3 Selection of RAID level
| Level | Features | Whether it is redundant | Number of disks | Read | Write |
|---|---|---|---|---|---|
| Cheap, fast, dangerous | No | N | fast | fast | |
| High-speed reading, simple and safe | Yes | 2 | Fast | Slow | |
| Security, cost Trade-off | has | N 1 | fast | depends on the slowest disk | |
| Expensive, high-speed, safe | Have | 2N | fast | fast |


 Conclusion: Increase the number of open files to 65535 to ensure that enough file handles can be opened.
Conclusion: Increase the number of open files to 65535 to ensure that enough file handles can be opened. 





The above is the detailed content of MYSQL advanced for big data learning. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
