


Free learning recommendation: mysql database(Video )
Background
Alibaba Cloud RDS FOR MySQL (MySQL version 5.7) database business table adds more than 10 million new data every month. As the amount of data continues to increase, slow queries on large tables appear in our business. During peak business periods, slow queries on the main business table take dozens of seconds, seriously affecting the business
Program Overview
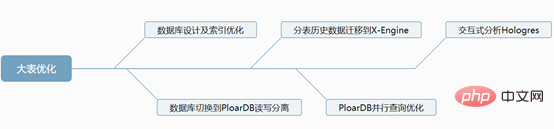
1. Database design and index optimization
The MySQL database itself is highly flexible, resulting in insufficient performance and heavy reliance on the developer's table design capabilities and indexing Optimization capabilities, here are some optimization suggestions
As the name suggests, it means leftmost priority. When creating a combined index, it should be used in the where clause according to business needs. The most frequent column is placed on the far left. A very important issue in a compound index is how to arrange the order of columns. For example, if the two fields c1 and c2 are used after where, then the order of the index is (c1, c2) or (c2, c1). The correct approach is to repeat The smaller the value, the higher it is placed. For example, if 95% of the values in a column are not repeated, then this column can generally be placed at the front.
2. Switch the database to PloarDB read-write separation
PolarDB It is a next-generation relational cloud database self-developed by Alibaba Cloud. It is 100% compatible with MySQL. The storage capacity can reach up to 100 TB. A single database can be expanded to up to 16 nodes. It is suitable for diversified database application scenarios of enterprises. PolarDB adopts an architecture that separates storage and computing. All computing nodes share a copy of data and provides minute-level configuration upgrades and downgrades, second-level fault recovery, global data consistency, and free data backup and disaster recovery services.
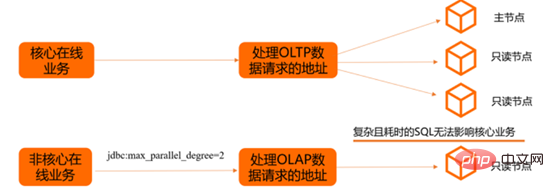
In offline mixed scenarios: different services use different connection addresses and use different data nodes to avoid mutual influence
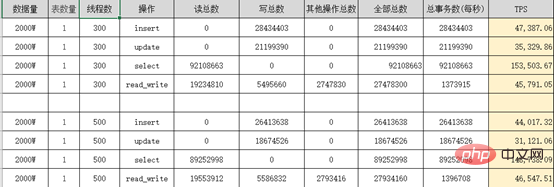
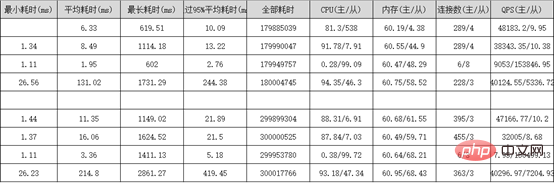
Sysbench performance stress test Report:
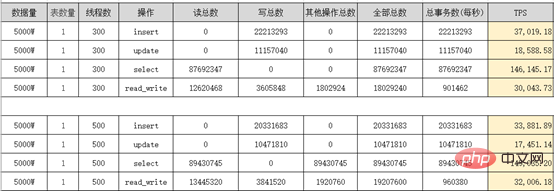
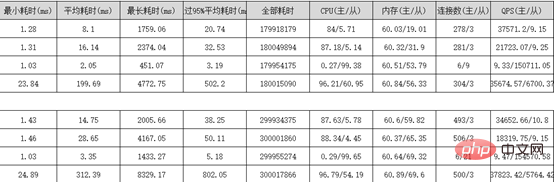
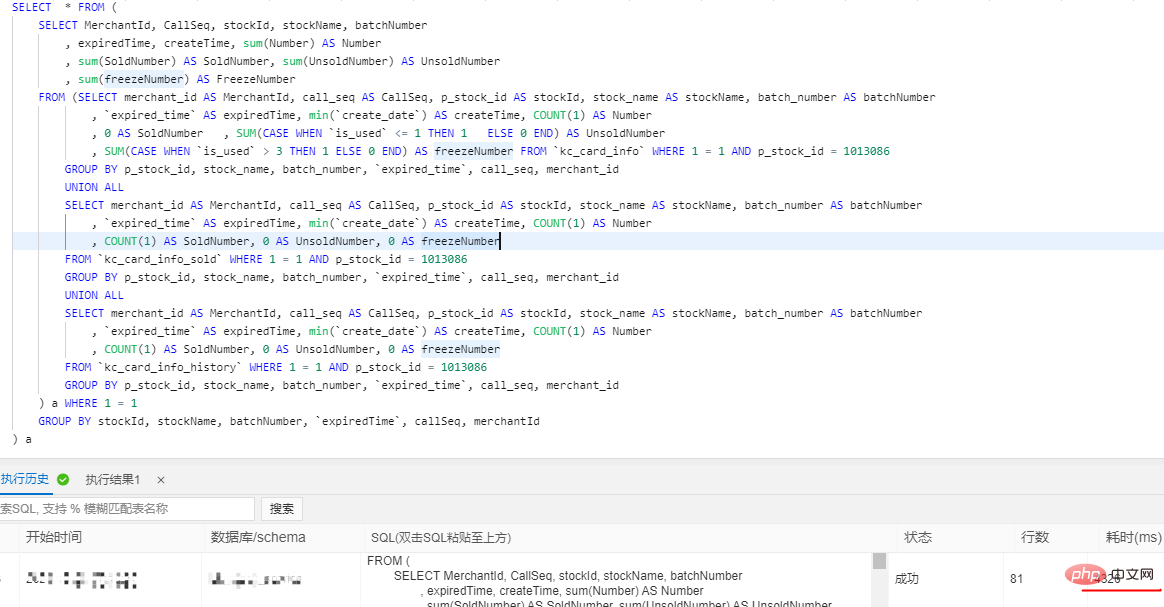
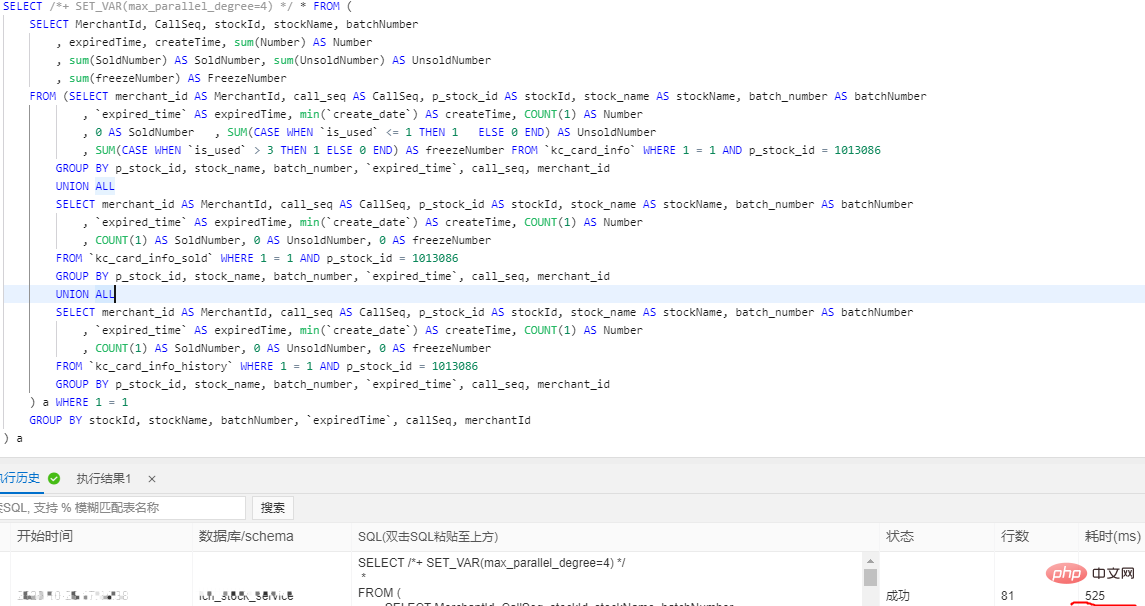
The split business table retains 3 months of data (this is based on the company's needs). Historical data is split into historical database X-Engine storage engine tables on a monthly basis. Why should we choose X-Engine storage engine tables? What are its advantages? ? X-Engine is an online transaction processing (OLTP) self-developed by Alibaba Cloud Database Product Division. Processing) database storage engine. 4. Parallel query of Alibaba Cloud PloarDB MySQL8.0 version After splitting the tables, our data volume is still very large Large, it does not completely solve our slow query problem, but only reduces the size of our business tables. For these slow queries, we need to use PolarDB’s parallel query optimization PolarDB MySQL 8.0 launches the parallel query framework , when the amount of your query data reaches a certain threshold, the parallel query framework will be automatically started, thereby exponentially reducing the query time. Parallel queries are suitable for most SELECT statements, such as large table queries, multi-table join queries, and queries with large calculation loads. For very short queries, the effect is less noticeable. Parallel query usage, you can use Hint syntax to control a single statement. For example, when the system turns off parallel queries by default, but you need to speed up a high-frequency slow SQL query, you can use Hint to Specific SQL is accelerated. SELECT / PARALLEL(x)/ … FROM …; – x >0 SELECT /* SET_VAR(max_parallel_degree=n) */ * FROM … // n > 0 Query test: The database is configured with 16 cores and 32G. The data volume of a single table exceeds 30 million It was 4326ms before parallel query was added, and it was 525ms after adding it, and the performance was improved by 8.24 times. ##5. Interactive analysis Hologre Here we recommend Alibaba Cloud’s interactive analysis Hologre ( 6. Postscript More related free learning recommendations: mysql tutorial(Video)
The X-Engine storage engine is not only seamlessly compatible with MySQL (thanks to the MySQL Pluginable Storage Engine feature), but X-Engine also uses a layered storage architecture. Because the goal is to store large-scale massive data, provide high concurrent transaction processing capabilities and reduce storage costs, in most large data volume scenarios, the opportunities for data to be accessed are uneven, and hot data that is frequently accessed actually accounts for Very rarely, X-Engine divides the data into multiple levels according to the frequency of data access. According to the access characteristics of each level of data, it designs the corresponding storage structure and writes it to the appropriate storage device
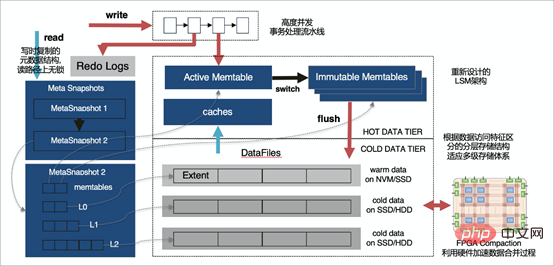
Split the data into different threads at the storage layer, and multiple threads will perform parallel calculations. The results of the pipeline are summarized into the main thread, and finally the main thread does a simple merge and returns it to the user to improve query efficiency.
Parallel Query utilizes the parallel processing capabilities of multi-core CPUs. Taking the 8-core 32 GB configuration as an example, the schematic diagram is as follows. 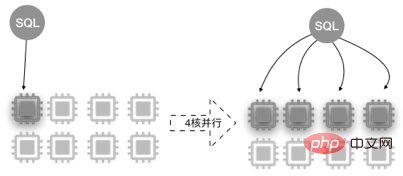
https://help.aliyun.com/product/113622.html) 
The above is the detailed content of Introducing the MySQL large table optimization solution. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



