

Teach you how to use JavaScript regular expressions in one trick

本篇文章给大家详细介绍一下吃通javascript正则表达式的方法。有一定的参考价值,有需要的朋友可以参考一下,希望对大家有所帮助。

正则表达式的作用
简单来讲正则表达式的作用就是进行字符串的增删改查,虽然javascritpt语言已经有及其完善的操作字符串的api,但是正则表达式会让你操作字符串更简单方便
创建正则表达式的方式
字面量形式
需要注意的是 字面量形式的正则表达式 是没有办法操作变量的,如下
const reg = "sattre is smart" let x = 's' console.log(/x/.test(reg)); //false
除非改成这样
// eval是把字符串变成js表达式
console.log(eval(`/${x}/`).test(str));使用对象的形式创建正则表达式
使用对象的形式创建的好处就是能够直接接受正则变量
const x = 'a' let regs = new RegExp(x) let str = 'All we need is love' let reg = new RegExp('A', 'g') // 第二个参数代表匹配的模式 console.log(reg.test(str));
小案例-实现输入字符高亮
其实就是和浏览器的ctrl+f功能差不多
<!DOCTYPE html><html lang="en"><head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title></head><body>
<p id="main">
All we need is love </p></body><script>
const cin = prompt('输入想要高亮内容')
const reg = new RegExp(cin, 'g')
let mainp = document.querySelector('#main')
console.log(mainp);
mainp.innerHTML = mainp.innerHTML.replace(reg, matched => {
return `<span style="color:red">${matched}</span>`
})</script></html>选择符
‘ | ’ 此为选择符,选择符两边的字符都可以匹配,都有效
let str1 = 'a' let str2 = 'b' console.log(/a|b/.test(str1)); //true console.log(/a|b/.test(str2)); //true
对转义的理解
自己的话理解就是,有些特殊符号如:{} [] . 等本来在正则表达式中就已经赋予了它的含义,如果单独使用会按照本身赋予的含义编译,如果需要匹配这些特殊符号本身,那么需要在这些符号前面加上一个 ‘’ 来加以区别
小数点本身的正则含义是除换行符外的任何字符
// 匹配小数点 \. let price = 23.34 console.log(/\d+\.\d+/.test(23.34)); //true
但是需要注意的来了
如果你是用对象方法声明的正则表达式的话,你需要在转义字符前多使用一次 ’ / ’ ,因为对象声明正则表达式传入的是字符串,他的解析方式不同
如下
let reg = new RegExp('\d+\.\d+') console.log(reg.test(price)); //false
console.log('/\d+\.\d+/');
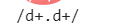
需要改成:
let reg1 = new RegExp('\\d+\\.\\d+') console.log(reg1.test(price)); //true
再来一个
const url = 'https://space.bilibili.com/17819768/' console.log(/https?:\/\/\w+\.\w+\.\w+\/\d+\//.test(url)); //true
字符边界约束
- ^ : 限定以其后面的第一个字符为开始
- $: 限定以其前面的第一个字符为结束
写一个监测必须以数字开头结束的字符串
let str = '2dasdjifeiorepo' let str2 = '3dsf5' console.log(/^\d\w+\d$/.test(str)); console.log(/^\d\w+\d$/.test(str2));
注意:^ 如果用在[ ] 中 还有除了[ ] 中的字符以外都可以匹配的意思
let str = `张三:155565666523,李四:2564154156561` console.log(str.match(/[^\d,:]+/g));
注意 :这里如果没有 ^ $ 的话 任意的超过6个的字符串都会成功,因为没有开始和结束的限定,match会在字符串中任意取6个字符,所以也算作是成功的
<!DOCTYPE html><html lang="en"><head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title></head><body>
<input type="text" name="user">
<span></span>
<script>
let input = document.querySelector("[name='user']")
let span = document.querySelector('span')
console.log(input);
input.addEventListener('keyup', function () {
// console.log(this.value.match(/^\w{3,6}$/));
if (this.value.match(/^\w{3,6}$/)) {
span.innerHTML = '正确格式'
}else{
span.innerHTML = '请输入3-6位字符'
}
})
</script></body></html>元字符
| 元字符 | 匹配 |
|---|---|
| \d | 匹配数字 |
| \D | 匹配除了数字的其他字符 |
| \s | 匹配空白(换行符也算) |
| \S | 除了空白的其他字符 |
| \w | 匹配字母 数字 下划线 |
| \W | 除了字母数字下划线 |
| . | 匹配除了换行符的任意字符 |
匹配一个邮箱
let str = `#$%483023989@qq.com` let str2 = `483023989@qq.com` console.log(str.match(/^\w+@\w+\.\w+$/)); console.log(str2.match(/^\w+@\w+\.\w+$/));

用 [ ] 巧妙匹配所有字符
如下,如果不加[ ] 代表完整匹配abc ,加了 [ ] ,代表可以匹配abc中的任意一个字符
let str = 'aaaabsdsc' console.log(str.match(/[abc]/g)); console.log(str.match(/abc/g));

可以用 [\s\S] [\d\D] 匹配所有字符
let str = '$%^&*()(*&^&*(sfhsdjf asdoia ..fdsdgf nsefxg\][iogjpsf' console.log(str.length); console.log(str.match(/[\s\S]/g));
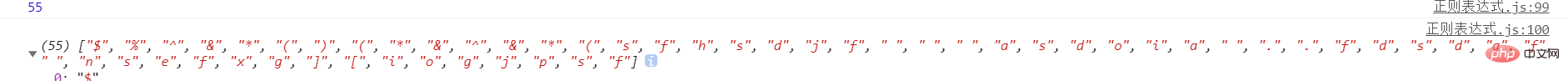
模式符
- i : 不区分大小写
- g: 全局匹配
let str = 'Www' console.log(str.match(/w/gi)); //["W", "w", "w"]
多行匹配
// 多行匹配
let str = `
#1 js,200元 #
#2 vue,500元 #
#3 angular,199元 # song
#4 node.js,188元 #
`let res = str.match(/\s*#\d+\s+.+\s+#\s+$/gm).map(item => {
item = item.replace(/\s*#\d+\s*/, '').replace(/#/, '')
let [name, price] = item.split(",")
return { name, price }})console.log(res);字符属性
\p 后面加上{x} x代表要匹配的字符属性 具体意思如下
元字符 含义
- \p{L} 所有字母
- \p{N} 所有数字,类似于 \d
- [\p{N}\p{L}] 所有数字和所有字母,类似于 \w
- \P{L} 不是字母,等价于 [^\p{L}]
- \P{N} 不是数字,等价于 [^\p{N}]
let str = "sadhusafsafha.啥事爱上撒大声地?!"// 匹配字符
console.log(str.match(/\p{L}/gu));// 匹配标点符号
console.log(str.match(/\p{P}/gu));// 匹配汉字
console.log(str.match(/\p{sc=Han}/gu));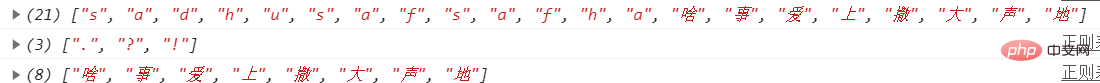
模式符 u
此修饰符标识能够正确处理大于\uFFFF的Unicode字符。
也就是说,会正确处理四个字节的UTF-16编码。
此修饰符是ES2015新增,更多正则表达式新特性可以参阅ES2015 正则表达式新增特性一章节。
比如有些时候,一些宽字节的字符匹配不到,就需要用到模式符/u
lastIndex属性
let str = 'nihaowoshizhongguoren'
let reg = /\w/g
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
while ((res = reg.exec(str))) {
console.log(res);}
有效率的y模式
和g的区别就是,g模式只要还有满足条件的字符就会继续下去匹配,而y模式只要下一个字符不满足匹配条件,就会停止匹配。它的作用是让匹配更具有效率,一旦遇到条件不符合的就不会再检测后面的字符了
let str = '尼采的电话是:516515614,111111111,2222222222 没重要的事千万不要打给他,因为他已经疯了' let reg = /(\d+),?/yreg.lastIndex = 7 console.log(reg.exec(str)); console.log(reg.exec(str)); console.log(reg.exec(str)); console.log(reg.exec(str));

原子表和原子组的基本使用
[] 代表原子表:可选择匹配 ()代表原子组
let str = 'paul_sattre' console.log(str.match(/st/g)); //需要st一起才能匹配 console.log(str.match(/[st]/g)); //需要只要有s 或者 t 就可以匹配
let date1 = '2021/4/9' let date2 = '2021-4-9' console.log(date1.match(/\d+[-\/]\d+[-\/]\d+/)); console.log(date2.match(/\d+[-\/]\d+[-\/]\d+/));

其实上面还是有点缺陷
就是将date改成这样的时候 2021-4/9 前后两个符号不一致的时候还是能够匹配到,这个时候就可以用到原子组了
let date1 = '2021/4/9' let date2 = '2021-4-9' let date3 = '2021-4/9' console.log(date1.match(/\d+([-\/])\d+\1\d+/)); console.log(date2.match(/\d+([-\/])\d+\1\d+/)); console.log(date3.match(/\d+([-\/])\d+\1\d+/));

加了一个 () 后面的\1代表要和前面的()相同才能行
邮箱验证
// 邮箱验证 let str = '483023989@qq.com.cn' let reg = /^[\w]+@[\w]+(\.[\w]+)+///["483023989@qq.com.cn", ".cn", index: 0, input: "483023989@qq.com.cn", groups: undefined] console.log(str.match(reg));// (\.[\w]+)+ 表示括号之内的内容有1个或多个

原子组的替换操作
替换h标签为p标签
let str = `
<h1 id="hello">hello</h1>
<h2 id="asdas">asdas</h2>
<h3 id="dasdad">dasdad</h3>
`let reg = /<(h[1-6])>([\s\S]+)<\/\1>/gi// console.log(str.replace(reg, '<p>$2</p>'));/**
*
<p>hello</p>
<p>asdas</p>
<p>dasdad</p>
*/let res = str.replace(reg, ($0, $1, $2) => {
return `<p>${$2}</p>`})/**
* 上面回调函数中的 $0 代表的是整个匹配到的内容,之后的$1 $2 就是从左
* 到右的原子组匹配到的内容
*/console.log(res);
不记录分组
https? 代表前面的字符s可以有也可以没有 代表不记录到我们的
下面的(?:\w+.) 原子组中的 ?: 代表不记录到我们的组编号之中
let str = `
https://www.nihao.com
http://nihao.com
`
let reg = /https?:\/\/((?:\w+\.)?\w+\.(?:com|cn|net))/gi
let urls = []
while ((res = reg.exec(str))) {
urls.push(res[1])
}
console.log(urls);所以有没有www都能匹配到
多种重复匹配基本使用
+ : 一个或多个
* : 零个或多个
{a,b}: a-b范围内的出现次数
?: 零个或1个
// 多种重复匹配基本使用
let str = 'asddddddddd'
let str2 = 'as'
console.log(str.match(/sd+/)); //1个或多个
console.log(str2.match(/sd*/)); //0个或多个
console.log(str.match(/sd{2,3}/)); // 2或3个
console.log(str.match(/sd?/)); // 0个或1个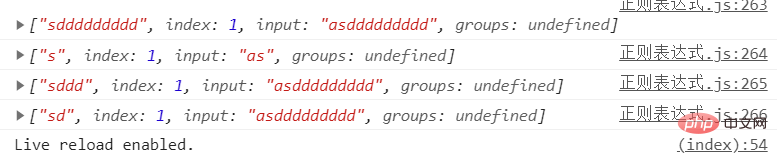
// 重复匹配对原子组的影响 let str = 'asdddddsd' console.log(str.match(/(sd)+/g)); //["sd", "sd"]
限定用户名为3-8位并且是以字母开头
// 限定用户名为3-8位并且是以字母开头
let username = 'a_Coding'
let username1 = '2fdsdfd'
let username2 = 's'
let username3 = 'asdsadsadsad';
console.log(/^[a-z]\w{2,7}$/i.test(username));
console.log(/^[a-z]\w{2,7}$/i.test(username1));
console.log(/^[a-z]\w{2,7}$/i.test(username2));
console.log(/^[a-z]\w{2,7}$/i.test(username3));
禁止贪婪
使用正则/sd+/ 匹配上面字符串时+会默认贪婪多个d,+后面加个?就只会匹配一个d了 这就是禁止贪婪
// 禁止贪婪
let str = 'asdddddd'/**
* 使用正则/sd+/ 匹配上面字符串时+会默认贪婪多个d
* +后面加个?就只会匹配一个d了 这就是禁止贪婪
*/console.log(str.match(/sd+/)); //sdddddd
console.log(str.match(/sd+?/)); //sd
console.log(str.match(/sd*/)); //sdddddd
console.log(str.match(/sd*?/)); //sd
console.log(str.match(/sd{1,4}/));//sdddd
console.log(str.match(/sd{1,4}?/));//sd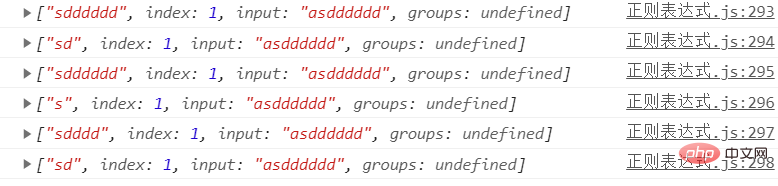
断言匹配
?= 后边是什么的
应该注意的是:断言只是对前面匹配的条件限定,并不参与实际的匹配结果中。
?= 中的等于号后面如果是个a,那么前面的匹配字符需要后面是a才会被匹配
// 断言匹配 ?= 后边是什么的 let str = '我爱你,你爱他' let reg = /爱(?=你)/ //匹配后面有一个,号的love console.log(str.replace(reg, '不爱')); //我不爱你,你爱他
使用断言规范价格
let lessons = `
js,343元,400次
node.js,300.00元,134次
java,500元,432次
`let reg = /(\d+)(.00)?(?=元)/gi
lessons = lessons.replace(reg, (v, ...args) => {
console.log(args);
args[1] = args[1] || '.00'
return args.slice(0, 2).join('')})console.log(lessons);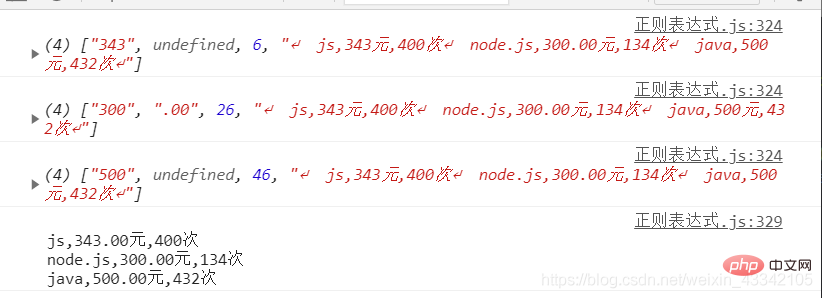
?<= 前面是什么的
理解上面的第一个断言这个也就能猜到意思了
// ?<= 前面是什么的 let str = '我爱你,你爱他' let reg1 = /(?<=你)爱/ console.log(str.replace(reg1, '不爱'));// 我爱你,你不爱他
使用断言模糊电话号码
let users = `
乔丹电话:54088888888,
艾弗森电话;08888888845
`// 给电话号码的后4位变成*
let reg = /(?<=\d{7})\d+/g//
console.log(users.match(reg));
users = users.replace(reg, '*'.repeat(4))
console.log(users);
?! 后面不是什么的就匹配
let str = 'hfewhieuwhf43758435efhiuewfhiew' let reg = /[a-z]+(?!\d+)$/i //取后面不是数字的字母 注意这里的这个$非常重要 console.log(str.match(reg)); //efhiuewfhiew
?let str = 'asdae334dsfdsff'
let reg = /(?<!\d+)[a-z]+/i
console.log(str.match(reg)); //asdae
Copy after login字符串正则方法
- search : 返回索引值,找不到就是-1
- match: 返回匹配后的字符结果 数组
- matchAll 返回全局匹配的迭代对象
- split 分割字符串形成数组
/// 字符串正则方法
let str = 'i love you'
console.log(str.search('u')); // 返回索引值,找不到就是-1
console.log(str.search(/o/));
// 返回匹配后的字符结果 数组
console.log(str.match(/o/)); //["o", index: 3, input: "i love you", groups: undefined]
// matchAll split
let date = '2001-1/1'
console.log(date.split(/[-\/]/)); //["2001", "1", "1"]
Copy after login
let str = 'asdae334dsfdsff' let reg = /(?<!\d+)[a-z]+/i console.log(str.match(reg)); //asdae
/// 字符串正则方法 let str = 'i love you' console.log(str.search('u')); // 返回索引值,找不到就是-1 console.log(str.search(/o/)); // 返回匹配后的字符结果 数组 console.log(str.match(/o/)); //["o", index: 3, input: "i love you", groups: undefined] // matchAll split let date = '2001-1/1' console.log(date.split(/[-\/]/)); //["2001", "1", "1"]
matchAll
<body>
<h1 id="all-nbsp-we-nbsp-need-nbsp-is-nbsp-love">all we need is love</h1>
<h2 id="all-nbsp-we-nbsp-need-nbsp-is-nbsp-love">all we need is love</h2>
<h3 id="all-nbsp-we-nbsp-need-nbsp-is-nbsp-love">all we need is love</h3>
<script>
let reg = /<(h[1-6])>([\s\S]+?)<\/\1>/gi
const content = document.body.innerHTML.matchAll(reg)
// console.log(content);
let res = []
for (const it of content) {
// console.log(it);
res.push(it[2])
}
console.log(res);
let str = 'woainiw'
// 为低端浏览器自定义原型方法matchALl
String.prototype.matchAll = function (reg) {
let res = this.match(reg)
if (res) {
let str = this.replace(res[0], '^'.repeat(res[0].length))
let match = str.matchAll(reg) || []
return [res, ...match]
}
}
console.log(str.matchAll(/(w)/i));
</script></body>
$符号在正则替换中的使用
$& 代表匹配到的内容
$` 代表匹配到的前面内容
$’ 代表匹配到的后面内容
let date = '2013/5/6'
let str = '(010)88888888 (020)88888888'
let reg = /\((\d{3,4})\)(\d{7,8})/g
console.log(str.replace(reg, "$1-$2"));
// 010-88888888 020-88888888
// $& 代表匹配到的内容
// $` 代表匹配到的前面内容
// $' 代表匹配到的后面内容
let str = '我爱你'
console.log(str.replace(/爱/, '不$&')); //我不爱你
console.log(str.replace(/爱/, "$`")); //我我你
console.log(str.replace(/爱/, "$'")); //我你你【推荐学习:javascript高级教程】
The above is the detailed content of Teach you how to use JavaScript regular expressions in one trick. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 PHP regular expression validation: number format detection
Mar 21, 2024 am 09:45 AM
PHP regular expression validation: number format detection
Mar 21, 2024 am 09:45 AM
PHP regular expression verification: Number format detection When writing PHP programs, it is often necessary to verify the data entered by the user. One of the common verifications is to check whether the data conforms to the specified number format. In PHP, you can use regular expressions to achieve this kind of validation. This article will introduce how to use PHP regular expressions to verify number formats and provide specific code examples. First, let’s look at common number format validation requirements: Integers: only contain numbers 0-9, can start with a plus or minus sign, and do not contain decimal points. floating point
 How to validate email address in Golang using regular expression?
May 31, 2024 pm 01:04 PM
How to validate email address in Golang using regular expression?
May 31, 2024 pm 01:04 PM
To validate email addresses in Golang using regular expressions, follow these steps: Use regexp.MustCompile to create a regular expression pattern that matches valid email address formats. Use the MatchString function to check whether a string matches a pattern. This pattern covers most valid email address formats, including: Local usernames can contain letters, numbers, and special characters: !.#$%&'*+/=?^_{|}~-`Domain names must contain at least One letter, followed by letters, numbers, or hyphens. The top-level domain (TLD) cannot be longer than 63 characters.
 How to match timestamps using regular expressions in Go?
Jun 02, 2024 am 09:00 AM
How to match timestamps using regular expressions in Go?
Jun 02, 2024 am 09:00 AM
In Go, you can use regular expressions to match timestamps: compile a regular expression string, such as the one used to match ISO8601 timestamps: ^\d{4}-\d{2}-\d{2}T \d{2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Use the regexp.MatchString function to check if a string matches a regular expression.
 Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
JavaScript tutorial: How to get HTTP status code, specific code examples are required. Preface: In web development, data interaction with the server is often involved. When communicating with the server, we often need to obtain the returned HTTP status code to determine whether the operation is successful, and perform corresponding processing based on different status codes. This article will teach you how to use JavaScript to obtain HTTP status codes and provide some practical code examples. Using XMLHttpRequest
 PHP regular expressions: exact matching and exclusion of fuzzy inclusions
Feb 28, 2024 pm 01:03 PM
PHP regular expressions: exact matching and exclusion of fuzzy inclusions
Feb 28, 2024 pm 01:03 PM
PHP Regular Expressions: Exact Matching and Exclusion Fuzzy inclusion regular expressions are a powerful text matching tool that can help programmers perform efficient search, replacement and filtering when processing text. In PHP, regular expressions are also widely used in string processing and data matching. This article will focus on how to perform exact matching and exclude fuzzy inclusion operations in PHP, and will illustrate it with specific code examples. Exact match Exact match means matching only strings that meet the exact condition, not any variations or extra words.
 How to verify password using regular expression in Go?
Jun 02, 2024 pm 07:31 PM
How to verify password using regular expression in Go?
Jun 02, 2024 pm 07:31 PM
The method of using regular expressions to verify passwords in Go is as follows: Define a regular expression pattern that meets the minimum password requirements: at least 8 characters, including lowercase letters, uppercase letters, numbers, and special characters. Compile regular expression patterns using the MustCompile function from the regexp package. Use the MatchString method to test whether the input string matches a regular expression pattern.
 Chinese character filtering: PHP regular expression practice
Mar 24, 2024 pm 04:48 PM
Chinese character filtering: PHP regular expression practice
Mar 24, 2024 pm 04:48 PM
PHP is a widely used programming language, especially popular in the field of web development. In the process of web development, we often encounter the need to filter and verify text input by users, among which character filtering is a very important operation. This article will introduce how to use regular expressions in PHP to implement Chinese character filtering, and give specific code examples. First of all, we need to clarify that the Unicode range of Chinese characters is from u4e00 to u9fa5, that is, all Chinese characters are in this range.
 How to get HTTP status code in JavaScript the easy way
Jan 05, 2024 pm 01:37 PM
How to get HTTP status code in JavaScript the easy way
Jan 05, 2024 pm 01:37 PM
Introduction to the method of obtaining HTTP status code in JavaScript: In front-end development, we often need to deal with the interaction with the back-end interface, and HTTP status code is a very important part of it. Understanding and obtaining HTTP status codes helps us better handle the data returned by the interface. This article will introduce how to use JavaScript to obtain HTTP status codes and provide specific code examples. 1. What is HTTP status code? HTTP status code means that when the browser initiates a request to the server, the service
