
 Backend Development
PHP Tutorial
'Xiaobai' will take you to understand the modules and working principles of Nginx! ! !
Backend Development
PHP Tutorial
'Xiaobai' will take you to understand the modules and working principles of Nginx! ! !
'Xiaobai' will take you to understand the modules and working principles of Nginx! ! !

NGINX is known for its high-performance load balancers, caches, and web servers, powering more than 40% of the world's busiest websites, so
has It has a certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.

1. Nginx Modules and working principles
Nginx consists of a kernel and modules. The kernel is designed to be very small and concise, and the work done is also very simple. It only needs to find the configuration file to transfer the client to the client. The end request is mapped to a location block (location is a directive in the Nginx configuration, used for URL matching), and each directive configured in this location will start different modules to complete the corresponding work.
Nginx modules are structurally divided into core modules, basic modules and third-party modules:
Core modules: HTTP module, EVENT module and MAIL module
Basic modules: HTTP Access module, HTTP FastCGI module, HTTP Proxy module and HTTP Rewrite module,
Three-party modules: HTTP Upstream Request Hash module, Notice module and HTTP Access Key module.
Modules developed by users according to their own needs are third-party modules. It is precisely with the support of so many modules that Nginx's functions are so powerful.
Nginx modules are functionally divided into the following three categories.
Handlers (processor module). This type of module directly processes requests and performs operations such as outputting content and modifying header information. Generally, there can only be one Handlers processor module.
Filters (filter module). This type of module mainly modifies the content output by other processor modules, and is finally output by Nginx.
Proxies (proxy class module). Such modules are modules such as Nginx's HTTP Upstream. These modules mainly interact with some back-end services such as FastCGI to implement functions such as service proxy and load balancing.
Figure 1-1 shows the normal HTTP request and response process of the Nginx module.
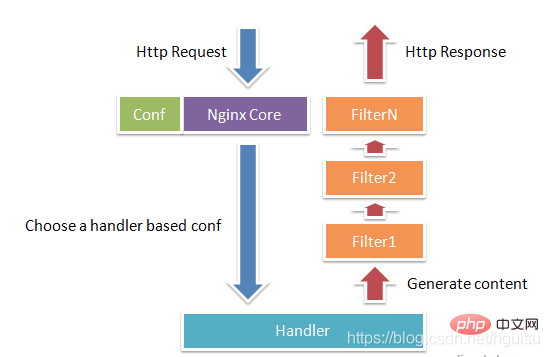
##Nginx itself actually does very little work. When it receives an HTTP request, it just searches for the configuration file. This request is mapped to a location block, and each instruction configured in this location will start different modules to complete the work, so the modules can be regarded as the real labor workers of Nginx. Usually instructions in a location involve a handler module and multiple filter modules (of course, multiple locations can reuse the same module). The handler module is responsible for processing requests and completing the generation of response content, while the filter module processes the response content.
Nginx modules are directly compiled into Nginx, so it is a static compilation method. After starting Nginx, the Nginx module is automatically loaded. Unlike Apache, the module is first compiled into an so file, and then whether to load is specified in the configuration file. When parsing the configuration file, each module of Nginx may process a certain request, but the same processing request can only be completed by one module.2. Nginx process model
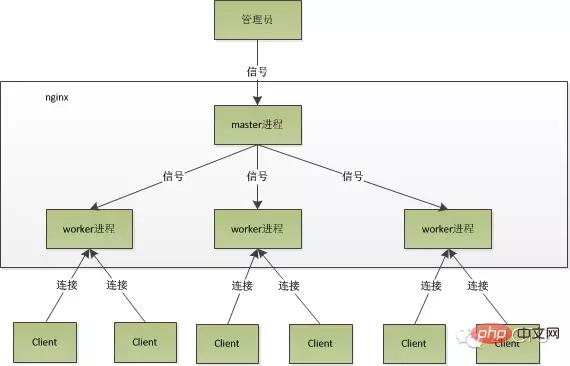
In terms of working method, Nginx is divided into single worker processes and multiple worker processes. In the single worker process mode, in addition to the main process, there is also a worker process, and the worker process is single-threaded; in the multi-worker process mode, each worker process contains multiple threads. Nginx defaults to single worker process mode. After Nginx is started, there will be a master process and multiple worker processes.
1. Master process: management process
The master process is mainly used to manage the worker process, including the following 4 main functions:
(1) Receive signals from the outside world .
(2) Send signals to each worker process.
(3) Monitor the running status of the woker process.
(4) When the woker process exits (under abnormal circumstances), the new woker process will be automatically restarted.
User interaction interface: The master process serves as the interactive interface between the entire process group and the user, and also monitors the process. It does not need to handle network events and is not responsible for business execution. It only manages worker processes to implement functions such as service restart, smooth upgrade, log file replacement, and configuration files taking effect in real time.
Restart the work process: To control nginx, we only need to send a signal to the master process through kill. For example, kill -HUP pid tells nginx to restart nginx gracefully. We usually use this signal to restart nginx or reload the configuration. Because it restarts gracefully, the service is not interrupted.
What does the master process do after receiving the HUP signal?
1). First, after receiving the signal, the master process will reload the configuration file, then start a new worker process, and send signals to all old worker processes to tell them that they can be glorious. retired.
2). After the new worker starts, it starts to receive new requests, while the old worker stops receiving new requests after receiving the signal from the master, and in the current process After all unprocessed requests are processed, exit.
Send signals directly to the master process. This is a more traditional operation method. After nginx version 0.8, a series of command line parameters were introduced to facilitate our management. For example, ./nginx -s reload is to restart nginx, and ./nginx -s stop is to stop nginx from running. How to do it? Let's take reload as an example. We see that when executing the command, we start a new nginx process, and after the new nginx process parses the reload parameter, we know that our purpose is to control nginx to reload the configuration file. , it will send a signal to the master process, and then the next action will be the same as if we sent the signal directly to the master process.
2. Worker process: processing requests
The basic network events are handled in the worker process. Multiple worker processes are peer-to-peer. They compete equally for requests from clients, and each process is independent of each other. A request can only be processed in one worker process, and a worker process cannot process requests from other processes. The number of worker processes can be set. Generally, we will set it to be consistent with the number of CPU cores of the machine. The reason for this is inseparable from the process model and event processing model of nginx.
Worker processes are equal, and each process has the same opportunity to process requests. When we provide http service on port 80 and a connection request comes, each process may handle the connection. How to do this?
Nginx uses an asynchronous non-blocking method to handle network events, similar to Libevent. The specific process is as follows:
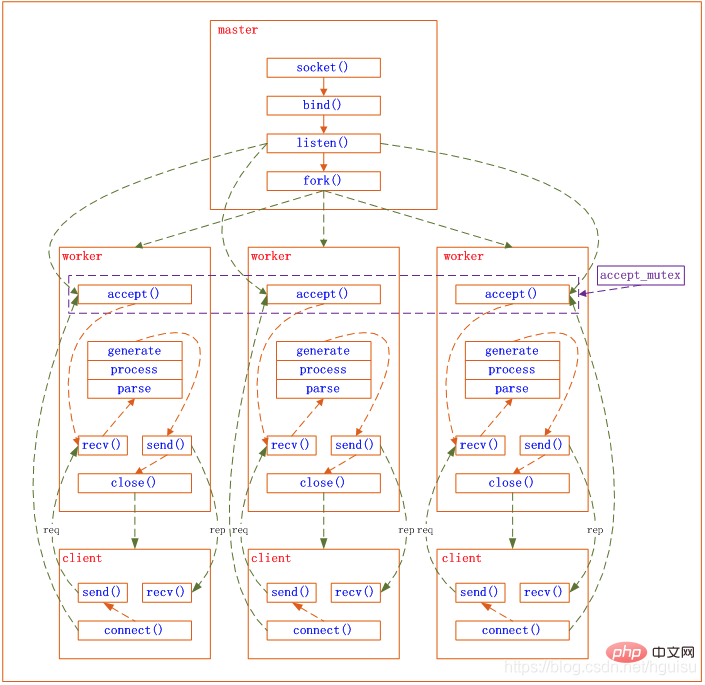
1) Receive requests: First, each worker process It is forked from the master process. After the master process establishes the socket (listenfd) that needs to be listened, it then forks out multiple worker processes. The listenfd of all worker processes will become readable when a new connection arrives, and each worker process can accept this socket (listenfd). When a client connection arrives, all accept work processes will be notified, but only one process can accept successfully, and the others will fail to accept. To ensure that only one process handles the connection, Nginx provides a shared lock accept_mutex to ensure that only one work process accepts the connection at the same time. All worker processes grab accept_mutex before registering the listenfd read event. The process that grabs the mutex lock registers the listenfd read event and calls accept in the read event to accept the connection.
2) Processing requests: After a worker process accepts the connection, it begins to read the request, parse the request, process the request, generate data, and then return it to the client. Finally, Just disconnect, such a complete request is like this.
We can see that a request is completely processed by the worker process, and is only processed in one worker process. Worker processes are equal, and each process has the same opportunity to process requests.
nginx’s process model can be represented by the following figure:
#3. Why Nginx has high performance - multi-process IO model
Reference http://mp.weixin.qq.com/s?__biz=MjM5NTg2NTU0Ng==&mid=407889757&idx=3&sn=cfa8a70a5fd2a674a91076f67808273c&scene=23&srcid=0401aeJQEraSG6uvLj69Hf ve#rd
1 , The benefits of nginx using a multi-process model
First, for each worker process, it is an independent process and does not need to be locked, so the overhead caused by the lock is eliminated, and at the same time, It will also be much more convenient when programming and problem finding.Secondly, using independent processes will not affect each other. After one process exits, other processes are still working and the service will not be interrupted. The master process will quickly start a new worker. process. Of course, if the worker process exits abnormally, there must be a bug in the program. Abnormal exit will cause all requests on the current worker to fail, but it will not affect all requests, so the risk is reduced.
2. nginx multi-process event model: asynchronous and non-blocking
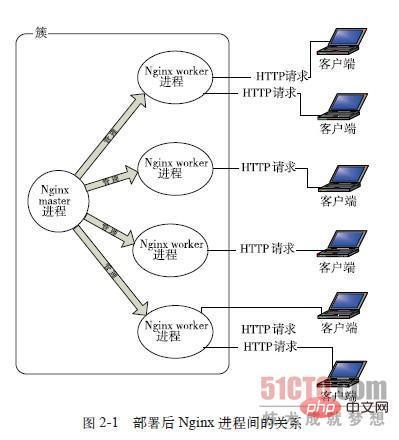
Although nginx uses a multi-worker method to process requests, there is only one main thread in each worker, so the number of concurrencies that can be processed is very limited. How many concurrencies can be processed by as many workers as possible, so how can it achieve high concurrency? No, this is the brilliance of nginx. nginx uses an asynchronous and non-blocking method to process requests, that is to say, nginx can process them at the same time Thousands of requests. The number of requests that a worker process can handle at the same time is only limited by the memory size, and in terms of architectural design, there are almost no restrictions on synchronization locks when processing concurrent requests between different worker processes, and worker processes usually do not enter sleep state. , therefore, when the number of processes on Nginx is equal to the number of CPU cores (it is best for each worker process to be bound to a specific CPU core), the cost of switching between processes is minimal.
Every A process only handles one request at a time , Therefore, when the number of concurrency reaches several thousand, there will be thousands of processes processing requests at the same time. This is a big challenge for the operating system. The memory usage caused by process is very large. The context switching of process brings a lot of CPU overhead, so the performance will naturally increase. Don't go, and the expense is completely meaningless.
# Why can nginx be processed in an asynchronous non -blocking method, or what happened to the asynchronous non -blocking? For details, please see: Using libevent and libev to improve network application performance - History of I/O model evolution
Let’s go back to the origin and look at the complete process of a request: first, the request comes and a connection needs to be established. Then receive the data, and then send the data after receiving the data.
Specific to the bottom layer of the system, it is the read and write events. When the read and write events are not ready, they must be inoperable. If you do not call it in a non-blocking way, you have to block the call and the event is not ready. , then you can only wait. When the event is ready, you can continue. Blocking calls will enter the kernel and wait, and the CPU will be used by others. For single-threaded workers, it is obviously not suitable. When there are more network events, everyone is waiting, and no one uses the CPU when it is idle. CPU utilization Naturally, the rate cannot go up, let alone high concurrency. Well, you said increasing the number of processes, what is the difference between this and Apache's threading model? Be careful not to increase unnecessary context switching. Therefore, in nginx, blocking system calls are the most taboo. Don't block, then it's non-blocking. Non-blocking means that if the event is not ready, it will return to EAGAIN immediately to tell you that the event is not ready yet. Why are you panicking? Come back later. Okay, after a while, check the event again until the event is ready. During this period, you can do other things first, and then check whether the event is ready. Although it is no longer blocked, you have to check the status of the event from time to time. You can do more things, but the overhead is not small.
About IO model: http://blog.csdn.net/hguisu/article/details/7453390
The event models supported by nginx are as follows (nginx wiki):
Nginx supports the following methods for processing connections (I/O multiplexing methods). These methods can be specified through the use directive.
- select – Standard method. It is the compile-time default method if there is no more efficient method for the current platform. You can enable or disable this module using the configuration parameters –with-select_module and –without-select_module.
- poll – Standard method. It is the compile-time default method if there is no more efficient method for the current platform. You can enable or disable this module using the configuration parameters –with-poll_module and –without-poll_module.
- kqueue – Efficient method for FreeBSD 4.1, OpenBSD 2.9, NetBSD 2.0 and MacOS X. Using kqueue on dual-processor MacOS Causes a kernel crash.
- epoll – An efficient method, used in Linux kernel version 2.6 and later systems. In some distributions, such as SuSE 8.2, there is a patch to support epoll in the 2.4 kernel.
- rtsig – Executable real-time signal, used in systems with Linux kernel version 2.2.19 or later. By default, no more than 1024 POSIX real-time (queued) signals can appear in the entire system. This situation is inefficient for heavily loaded servers; so it is necessary to increase the queue size by adjusting the kernel parameter /proc/sys/kernel/rtsig-max. However, starting from Linux kernel version 2.6.6-mm2, this parameter is no longer used, and there is an independent signal queue for each process. The size of this queue can be adjusted with the RLIMIT_SIGPENDING parameter. When this queue becomes too congested, nginx abandons it and starts using the poll method to handle connections until normalcy returns.
- /dev/poll – Efficient method for Solaris 7 11/99, HP/UX 11.22 (eventport), IRIX 6.5.15 and Tru64 UNIX 5.1A.
- eventport – Efficient method, used on Solaris 10. In order to prevent kernel crashes, it is necessary to install this security patch.
Under Linux, only epoll is an efficient method
Let’s take a look at how efficient epoll is
Epoll is made by the Linux kernel to handle large batches of handles Improved poll. To use epoll, you only need these three system calls: epoll_create(2), epoll_ctl(2), epoll_wait(2). It was introduced in the 2.5.44 kernel (epoll(4) is a new API introduced in Linux kernel 2.5.44) and is widely used in the 2.6 kernel.
## Epoll's advantages
- # Support a process to open a large number of Socket descriptors (FD)
- IO efficiency does not decrease linearly as the number of FDs increases
Another fatal weakness of traditional select/poll is that when you have a large socket set, due to network delay, Only some sockets are "active" at any time, but each call to select/poll will linearly scan the entire collection, resulting in a linear decline in efficiency. But epoll does not have this problem, it will only operate on "active" sockets - this is because in the kernel implementation, epoll is implemented based on the callback function on each fd. Then, only "active" sockets will actively call the callback function, and other idle state sockets will not. At this point, epoll implements a "pseudo" AIO, because at this time the driving force is in the os kernel. In some benchmarks, if all sockets are basically active - such as a high-speed LAN environment, epoll is not more efficient than select/poll. On the contrary, if epoll_ctl is used too much, the efficiency will drop slightly. But once idle connections are used to simulate a WAN environment, the efficiency of epoll is far higher than that of select/poll.
- Use mmap to accelerate message passing between kernel and user space.
This point actually involves the specific implementation of epoll. Whether it is select, poll or epoll, the kernel needs to notify the user space of the FD message. How to avoid unnecessary memory copies is very important. At this point, epoll is implemented by mmap the same memory in the user space through the kernel. And if you have been following epoll since the 2.5 kernel like me, you will definitely not forget the manual mmap step.
- Kernel fine-tuning
This is actually not an advantage of epoll, but an advantage of the entire Linux platform. Maybe you can doubt the Linux platform, but you can't avoid the ability that the Linux platform gives you to fine-tune the kernel. For example, the kernel TCP/IP protocol stack uses a memory pool to manage the sk_buff structure, then the size of this memory pool (skb_head_pool) can be dynamically adjusted during runtime - completed by echo XXXX>/proc/sys/net/core/hot_list_length. Another example is the second parameter of the listen function (the length of the packet queue after TCP completes the three-way handshake), which can also be dynamically adjusted according to the memory size of your platform. We even tried the latest NAPI network card driver architecture on a special system where the number of data packets is huge but the size of each data packet itself is very small.
(epoll content, refer to epoll_Interactive Encyclopedia)
It is recommended to set the number of workers to the number of CPU cores, which is very convenient here. It is easy to understand that more workers will only cause processes to compete for CPU resources, resulting in unnecessary context switching. Moreover, in order to better utilize the multi-core features, nginx provides a cpu affinity binding option. We can bind a certain process to a certain core, so that the cache will not fail due to process switching. Small optimizations like this are very common in nginx, and it also illustrates the painstaking efforts of the nginx author. For example, when nginx compares 4-byte strings, it will convert the 4 characters into an int type and then compare them to reduce the number of CPU instructions and so on.
Code to summarize the nginx event processing model:
while (true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks: /* sorted already */
if (t.time <= now) {
t.timeout_handler();
} else {
timeout = t.time - now;
break;
}
nevents = poll_function(events, timeout);
for i in nevents:
task t;
if (events[i].type == READ) {
t.handler = read_handler;
} else { /* events[i].type == WRITE */
t.handler = write_handler;
}
run_tasks_add(t);
}
4. Nginx FastCGI operating principle
1. What is FastCGI
FastCGI is a scalable, high-speed An interface for communication between HTTP servers and dynamic scripting languages. Most popular HTTP servers support FastCGI, including Apache, Nginx, lighttpd, etc. At the same time, FastCGI is also supported by many scripting languages, including PHP.
FastCGI is developed and improved from CGI. The main disadvantage of the traditional CGI interface method is poor performance, because every time the HTTP server encounters a dynamic program, the script parser needs to be restarted to perform parsing, and then the results are returned to the HTTP server. This is almost unusable when dealing with high concurrent access. In addition, the traditional CGI interface method has poor security and is rarely used now.
FastCGI interface mode adopts C/S structure, which can separate the HTTP server and the script parsing server, and start one or more script parsing daemons on the script parsing server. Every time the HTTP server encounters a dynamic program, it can be delivered directly to the FastCGI process for execution, and then the result is returned to the browser. This method allows the HTTP server to exclusively process static requests or return the results of the dynamic script server to the client, which greatly improves the performance of the entire application system.
2. Nginx FastCGI operating principle
Nginx does not support direct calls or parsing of external programs. All external programs (including PHP) Must be called through the FastCGI interface. The FastCGI interface is a socket under Linux (this socket can be a file socket or an ip socket).
wrapper: In order to call a CGI program, a FastCGI wrapper is also needed (a wrapper can be understood as a program used to start another program). This wrapper is bound to a fixed socket, such as a port Or file socket. When Nginx sends a CGI request to this socket, the wrapper receives the request through the FastCGI interface, and then Forks (derives) a new thread. This thread calls the interpreter or external program to process the script and read the return data; then, The wrapper then passes the returned data to Nginx through the FastCGI interface and along the fixed socket; finally, Nginx sends the returned data (html page or picture) to the client. This is the entire operation process of Nginx FastCGI, as shown in Figure 1-3.
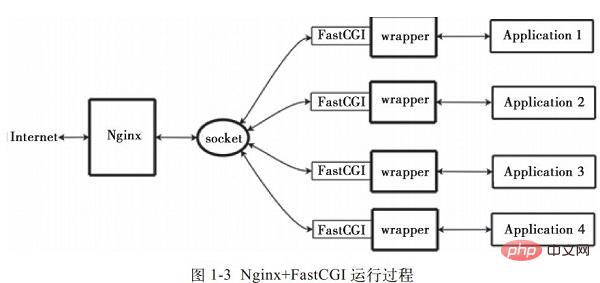
So, we first need a wrapper. The work that this wrapper needs to complete:
- Communicate with ningx through socket by calling the function of fastcgi (library) (reading and writing socket is a function implemented internally by fastcgi and is non-transparent to wrapper)
- Scheduling thread, fork and kill
- Communicate with application (php)
3. spawn-fcgi and PHP-FPM
## FastCGI interface method starts a script on the script parsing server Or multiple daemon processes parse dynamic scripts. These processes are the FastCGI process manager, or FastCGI engine. spawn-fcgi and PHP-FPM are two FastCGI process managers that support PHP. Therefore, HTTPServer is completely liberated and can respond better and handle concurrently.
The similarities and differences between spawn-fcgi and PHP-FPM: 1) spawn-fcgi is part of the HTTP server lighttpd. It has become an independent project and is generally used in conjunction with lighttpd. PHP is supported. However, ligttpd's spwan-fcgi may cause memory leaks or even automatically restart FastCGI during high concurrent access. That is: the PHP script processor crashes. If the user accesses it at this time, a white page may appear (that is, PHP cannot be parsed or an error occurs).
So actually it looks like thisnginx is very flexible. It can be connected with any third-party parsing processor to realize the parsing of PHP(Easy to set ) in nginx.conf. nginx can also use spwan-fcgi(needs to be installed together with lighttpd, but You need to avoid the port for nginx. Some earlier blog have installation tutorials in this regard), but because spawn-fcgi has the defects gradually discovered by users as mentioned above, the use of nginx spawn-fcgi# is now slowly reduced. ##Combined. Due to the defects of spawn-fcgi, there is now a third-party (currently added to PHP core) PHP FastCGI processor PHP-FPM. Compared with spawn-fcgi, it has the following advantages : Since it is developed as a PHP patch, it needs to be compiled together with the PHP source code during installation, which means it is compiled into PHP core, so it is better in terms of performance;
At the same time, it is also better than spawn-fcgi in handling high concurrency, at least it will not automatically restart the fastcgi processor. Therefore, it is recommended to use the Nginx PHP/PHP-FPM combination to parse PHP.
Compared to Spawn-FCGI, PHP-FPM has better CPU and memory control, and the former crashes easily and must be monitored with crontab, while PHP-FPM does not have such troubles.
The main advantage of FastCGI is to separate dynamic languages from HTTP Server, so Nginx and PHP/PHP-FPM are often deployed on different servers to share the pressure on the front-end Nginx server and enable Nginx to exclusively handle static requests. and forward dynamic requests, while the PHP/PHP-FPM server exclusively parses PHP dynamic requests.4. Nginx PHP-FPM
PHP-FPM is a manager for managing FastCGI. It exists as a plug-in for PHP. When you install PHP and want to use PHP-FPM, Older versions of php (before php5.3.3) need to install PHP-FPM into PHP in the form of a patch, and PHP must be consistent with the PHP-FPM version, which is necessary)
PHP-FPM It is actually a patch to the PHP source code, designed to integrate FastCGI process management into the PHP package. It must be patched into your PHP source code and can be used after compiling and installing PHP.
PHP5.3.3 has integrated php-fpm and is no longer a third-party package. PHP-FPM provides a better PHP process management method, which can effectively control memory and processes, and can smoothly reload PHP configuration. It has more advantages than spawn-fcgi, so it is officially included in PHP. You can enable PHP-FPM by passing the –enable-fpm parameter in ./configure.
Fastcgi is already in the core of php5.3.5. There is no need to add --enable-fastcgi when configuring. Older versions such as php5.2 need to add this item.
When we install Nginx and PHP-FPM, the configuration information:
The default configuration of PHP-FPM php-fpm.conf:
listen_address 127.0.0.1:9000 #This represents the IP address and port that PHP's fastcgi process listens to
start_servers
min_spare_servers
max_spare_servers
Nginx configuration to run php: Edit nginx.conf and add the following statement:
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000; specifies the port on which the fastcgi process listens , nginx interacts with php through here
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /usr/local/nginx/html$fastcgi_script_name;
}
NginxThrough the location directive, all files with the suffix php are handed over to 127.0.0.1:9000 for processing, and the IP address and port here are the IP addresses and ports monitored by the FastCGI process. port.
Its overall workflow:
1) FastCGI process manager php-fpm initializes itself, starts the main process php-fpm and starts start_servers CGI child process.
The main process php-fpm mainly manages the fastcgi sub-process and listens to port 9000.
fastcgi subprocessWaiting for a connection from the Web Server.
2) When the client request reaches Web Server Nginx, Nginx uses the location directive to hand over all files with php as the suffix to 127.0.0.1:9000 To process, that is, Nginx uses the location directive to hand over all files with php as the suffix to 127.0.0.1:9000 for processing.
3) FastCGI Process Manager PHP-FPM selects and connects to a child process CGI interpreter. The Web server sends CGI environment variables and standard input to the FastCGI child process.
4) After the FastCGI sub-process completes processing, it returns standard output and error information to the Web Server from the same connection. When the FastCGI child process closes the connection, the request is processed.
5). The FastCGI child process then waits for and processes the next connection from the FastCGI process manager (running in WebServer).
5. Correct configuration of Nginx PHP
Generally, the web has a unified entrance: all PHP requests are Send it to the same file, and then implement routing by parsing "REQUEST_URI" in this file.
Nginx configuration file is divided into many blocks. The common ones from outside to inside are "http", "server", "location", etc. The default inheritance relationship is from outside to inside. That is to say, the inner block will automatically obtain the value of the outer block as the default value.
For example:
server {
listen 80;
server_name foo.com;
root /path;
location / {
index index.html index.htm index.php;
if (!-e $request_filename) {
rewrite . /index.php last;
}
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /path$fastcgi_script_name;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
}
}1) 不应该在location 模块定义index
一旦未来需要加入新的「location」,必然会出现重复定义的「index」指令,这是因为多个「location」是平级的关系,不存在继承,此时应该在「server」里定义「index」,借助继承关系,「index」指令在所有的「location」中都能生效。
2) 使用try_files
接下来看看「if」指令,说它是大家误解最深的Nginx指令毫不为过:
if (!-e $request_filename) {
rewrite . /index.php last;
}
很多人喜欢用「if」指令做一系列的检查,不过这实际上是「try_files」指令的职责:
try_files $uri $uri/ /index.php;
除此以外,初学者往往会认为「if」指令是内核级的指令,但是实际上它是rewrite模块的一部分,加上Nginx配置实际上是声明式的,而非过程式的,所以当其和非rewrite模块的指令混用时,结果可能会非你所愿。
3)fastcgi_params」配置文件:
include fastcgi_params;
Nginx有两份fastcgi配置文件,分别是「fastcgi_params」和「fastcgi.conf」,它们没有太大的差异,唯一的区别是后者比前者多了一行「SCRIPT_FILENAME」的定义:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
注意:$document_root 和 $fastcgi_script_name 之间没有 /。
原本Nginx只有「fastcgi_params」,后来发现很多人在定义「SCRIPT_FILENAME」时使用了硬编码的方式,于是为了规范用法便引入了「fastcgi.conf」。
不过这样的话就产生一个疑问:为什么一定要引入一个新的配置文件,而不是修改旧的配置文件?这是因为「fastcgi_param」指令是数组型的,和普通指令相同的是:内层替换外层;和普通指令不同的是:当在同级多次使用的时候,是新增而不是替换。换句话说,如果在同级定义两次「SCRIPT_FILENAME」,那么它们都会被发送到后端,这可能会导致一些潜在的问题,为了避免此类情况,便引入了一个新的配置文件。
此外,我们还需要考虑一个安全问题:在PHP开启「cgi.fix_pathinfo」的情况下,PHP可能会把错误的文件类型当作PHP文件来解析。如果Nginx和PHP安装在同一台服务器上的话,那么最简单的解决方法是用「try_files」指令做一次过滤:
try_files $uri =404;
依照前面的分析,给出一份改良后的版本,是不是比开始的版本清爽了很多:
server {
listen 80;
server_name foo.com;
root /path;
index index.html index.htm index.php;
location / {
try_files $uri $uri/ /index.php;
}
location ~ \.php$ {
try_files $uri =404;
include fastcgi.conf;
fastcgi_pass 127.0.0.1:9000;
}
}六. Nginx优化
1. 编译安装过程优化
1).减小Nginx编译后的文件大小
在编译Nginx时,默认以debug模式进行,而在debug模式下会插入很多跟踪和ASSERT之类的信息,编译完成后,一个Nginx要有好几兆字节。而在编译前取消Nginx的debug模式,编译完成后Nginx只有几百千字节。因此可以在编译之前,修改相关源码,取消debug模式。具体方法如下:
在Nginx源码文件被解压后,找到源码目录下的auto/cc/gcc文件,在其中找到如下几行:
# debug CFLAGS=”$CFLAGS -g”
注释掉或删掉这两行,即可取消debug模式。
2.为特定的CPU指定CPU类型编译优化
在编译Nginx时,默认的GCC编译参数是“-O”,要优化GCC编译,可以使用以下两个参数:
- --with-cc-opt='-O3'
- --with-cpu -opt=CPU #Compile for a specific CPU. Valid values include:
pentium, pentiumpro, pentium3, # pentium4, athlon, opteron, amd64, sparc32, sparc64, ppc64
To determine the CPU type, you can use the following command: #cat /proc/cpuinfo | grep "model name"
2. Use TCMalloc to optimize the performance of Nginx
The full name of TCMalloc is Thread-Caching Malloc, which is one of the open source tools google-perftools developed by Google. member. Compared with the standard glibc library's Malloc, the TCMalloc library is much more efficient and fast in memory allocation, which greatly improves the performance of the server in high concurrency situations, thereby reducing the load on the system. The following is a brief introduction on how to add TCMalloc library support to Nginx.
To install the TCMalloc library, you need to install two software packages: libunwind (32-bit operating systems do not need to be installed) and google-perftools. The libunwind library provides a basic function call chain for programs based on 64-bit CPUs and operating systems. and function call register functions. The following describes the specific operation process of using TCMalloc to optimize Nginx.
1). Install the libunwind library
You can download the corresponding libunwind version from http://download.savannah.gnu.org/releases/libunwind, downloaded here It's libunwind-0.99-alpha.tar.gz. The installation process is as follows
#tar zxvf libunwind-0.99-alpha.tar.gz
# cd libunwind-0.99-alpha/
#CFLAGS=-fPIC ./configure
#make CFLAGS= -fPIC
#make CFLAGS=-fPIC install
2). Install google-perftools
from http://google-perftools.googlecode.com Download the corresponding google-perftools version. The one downloaded here is google-perftools-1.8.tar.gz. The installation process is as follows:
[root@localhost home]#tar zxvf google-perftools-1.8.tar.gz
[root@localhost home]#cd google-perftools-1.8/
[root @localhost google-perftools-1.8]# ./configure
[root@localhost google-perftools-1.8]#make && make install
[root@localhost google-perftools-1.8]#echo "/usr/
local/lib" > /etc/ld.so.conf.d/usr_local_lib.conf
[root@localhost google-perftools-1.8]# ldconfig
At this point, the installation of google-perftools is completed .
3). Recompile Nginx
In order for Nginx to support google-perftools, you need to add the "-with-google_perftools_module" option during the installation process to recompile Nginx. The installation code is as follows:
[root@localhostnginx-0.7.65]#./configure \
>--with-google_perftools_module --with-http_stub_status_module --prefix=/opt/nginx
[root@localhost nginx-0.7.65]#make
[root@localhost nginx-0.7.65]#make install
The Nginx installation is completed here.
4). Add a thread directory for google-perftools
Create a thread directory and place the file under /tmp/tcmalloc. The operation is as follows:
[root@localhost home]#mkdir /tmp/tcmalloc
[root@localhost home]#chmod 0777 /tmp/tcmalloc
5). Modification Nginx main configuration file
Modify the nginx.conf file and add the following code below the pid line:
#pid logs/nginx.pid;
google_perftools_profiles /tmp/ tcmalloc;
Then, restart Nginx to complete the loading of google-perftools.
6). Verify the running status
In order to verify that google-perftools has been loaded normally, you can view it through the following command:
[root@ localhost home]# lsof -n | grep tcmalloc
nginx 2395 nobody 9w REG 8,8 0 1599440 /tmp/tcmalloc.2395
nginx 2396 nobody 11w REG 8,8 0 1599443 /tmp /tcmalloc.2396
nginx 2397 nobody 13w REG 8,8 0 1599441 /tmp/tcmalloc.2397
nginx 2398 nobody 15w REG 8,8 0 159944 2 /tmp/tcmalloc.2398
Because in The value of worker_processes is set to 4 in the Nginx configuration file, so 4 Nginx threads are opened, and each thread will have a row of records. The numerical value after each thread file is the pid value of started Nginx.
At this point, the operation of using TCMalloc to optimize Nginx is completed.
3.Nginx kernel parameter optimization
The optimization of kernel parameters is mainly the optimization of system kernel parameters for Nginx applications in Linux systems.
An optimization example is given below for reference.
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4 .tcp_syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4 .tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
will Add the above kernel parameter values to the /etc/sysctl.conf file, and then execute the following command to make it effective:
[root@ localhost home]#/sbin/sysctl -p
The following introduces the meaning of the options in the example:
TCP parameter settings:
net .ipv4.tcp_max_tw_buckets: The option is used to set the number of timewait. The default is 180 000, here it is set to 6000.
net.ipv4.ip_local_port_range: option is used to set the port range that the system is allowed to open. In high concurrency situationsotherwise the port number will not be enough. When NGINX acts as a proxy, each connection to the upstream server uses an ephemeral or ephemeral port.
net.ipv4.tcp_tw_recycle: option is used to set and enable timewait fast recycling.
net.ipv4.tcp_tw_reuse: option is used to set up reuse, allowing TIME-WAIT sockets to be reused for new TCP connections.
net.ipv4.tcp_syncookies: option is used to set up SYN Cookies. When the SYN waiting queue overflows, cookies are enabled for processing.
net.ipv4.tcp_max_orphans: option is used to set the maximum number of TCP sockets in the system that are not associated with any user file handle. If this number is exceeded, the orphaned connection will be reset immediately and a warning message printed. This restriction is only to prevent simple DoS attacks. You cannot rely too much on this limit or even artificially reduce this value. In more cases, you should increase this value.
net.ipv4.tcp_max_syn_backlog: option is used to record the maximum value of connection requests that have not yet received client confirmation information. The default value of this parameter is 1024 for systems with 128MB of memory, and 128 for systems with small memory.
The value of the net.ipv4.tcp_synack_retries parameter determines the number of SYN ACK packets sent before the kernel gives up the connection.
net.ipv4.tcp_syn_retries option indicates the number of SYN packets sent before the kernel gives up establishing a connection.
The net.ipv4.tcp_fin_timeout option determines how long the socket remains in the FIN-WAIT-2 state. The default value is 60 seconds. It is very important to set this value correctly. Sometimes even a lightly loaded web server will have a large number of dead sockets and risk memory overflow.
net.ipv4.tcp_syn_retries option indicates the number of SYN packets sent before the kernel gives up establishing a connection.
If the sender requests to close the socket, the net.ipv4.tcp_fin_timeout option determines how long the socket remains in the FIN-WAIT-2 state. The receiving end can make errors and never close the connection, or even crash unexpectedly.
The default value of net.ipv4.tcp_fin_timeout is 60 seconds. It should be noted that even a web server with a small load will run the risk of memory overflow due to a large number of dead sockets. FIN-WAIT-2 is less dangerous than FIN-WAIT-1 because it can only consume up to 1.5KB of memory, but its lifetime is longer.
net.ipv4.tcp_keepalive_time option indicates how often TCP sends keepalive messages when keepalive is enabled. The default value is 2 (units are hours).
Buffer queue:
##net.core.somaxconn:# The default value of the ## option is 128. This parameter is used to adjust the number of TCP connections initiated by the system at the same time. In highly concurrent requests, the default value may cause the link to time out or retransmit. Therefore, concurrent requests need to be combined. number to adjust this value.
Determined by the number acceptable to NGINX. The default value is usually low, but acceptable because NGINX receives connections very quickly, but you should increase this value if your website has heavy traffic. Error messages in the kernel log will remind you that this value is too small. Increase the value until the error message disappears. Note: If you set this value to be greater than 512, you must also change the backlog parameter of the NGINX listen command accordingly.
net.core.netdev_max_backlog: option indicates when each network interface is receiving packets faster than the kernel can process them The maximum number of packets allowed to be sent to the queue.
4.Optimization of PHP-FPMIf your high-load website uses PHP-FPM to manage FastCGI, these tips may be useful Useful for you:
1) Increase the number of FastCGI processesAdjust the number of PHP FastCGI sub-processes to 100 or above. On a server with 4G memory, 200 is recommended. Stress test to get the best value.
2) Increase the limit of PHP-FPM open file descriptorsThe tag rlimit_files is used to set the limit of PHP-FPM on open file descriptors. The default value is 1024 . The value of this label must be associated with the number of open files in the Linux kernel. For example, to set this value to 65 535, you must execute "ulimit -HSn 65536" on the Linux command line.
Then
Increase the limit of PHP-FPM open file descriptors: ##“
. Restart PHP-FPM.
ulimit -n should be adjusted to
65536 or even larger. How to adjust this parameter, you can refer to some articles on the Internet. Execute ulimit -n 65536 on the command line to modify it. If it cannot be modified, you need to set /etc/security/limits.conf and add * hard nofile65536
* soft nofile 65536
## 3) Appropriately increase max_requests
## The maximum number of requests a child can handle before being closed. The default setting is 500.
5.nginx.conf parameter optimization
The number of processes to be opened by nginx is generally equal to the total number of cores of the CPU. In fact, under normal circumstances, 4 or 8 can be opened.
The memory consumed by each nginx process is 10 megabytes.worker_cpu_affinity
Only applicable to linux, use this option to bind the worker process and CPU (2.4 The kernel machine cannot be used)
If it is 8 cpu, the allocation is as follows:
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000
00100000 01000000 10000000
nginx can use multiple worker process, for the following reasons:
to use SMP
to decrease latency when workers blockend on disk I/O
to limit number of connections per process when select() /poll() is
used The worker_processes and worker_connections from the event sections
allows you to calculate maxclients value: k max_clients = worker_processes * worker_connections
worker_rlimit_nofile 102400;
The configuration of the maximum number of open file descriptors for each nginx process must be consistent with the number of open files for a single process in the system. The number of open files under the Linux 2.6 kernel is 65535. The worker_rlimit_nofile should be filled in with 65535 accordingly. When nginx is scheduled, the allocation request is The process is not so balanced. If it exceeds the limit, a 502 error will be returned. What I write here is bigger
use epoll
Nginx uses the latest epoll (Linux 2.6 kernel) and kqueue (freebsd) network I/O model, while Apache The traditional select model is used.
To handle the reading and writing of a large number of connections, the select network I/O model used by Apache is very inefficient. In high-concurrency servers, polling I/O is the most time-consuming operation. Currently, Linux can withstand high concurrency. Both Squid and Memcached accessed use the epoll network I/O model.
worker_processesNumber of NGINX worker processes (default value is 1). In most cases, it is best to run one worker process per CPU core, and it is recommended to set this instruction to automatic. Sometimes you may want to increase this value, such as when the worker process needs to do a lot of disk I/O.
worker_connections 65535; The maximum number of simultaneous connections allowed per worker process (Maxclient = work_processes * worker_connections)
Keepalive timeout time
Here you need to pay attention to the official sentence:
The parameters can differ from each other. Line Keep-Alive:
timeout=time understands Mozilla and Konqueror. MSIE itself shuts
keep-alive connection approximately after 60 seconds.
##client_header_buffer_size 16k
large_client_header_buffers 4 32k
Customer request header buffer size
nginx will use the client_header_buffer_size buffer by default to read the header value. If the header is too large, it will use large_client_header_buffers to read If the HTTP header is set too small /Cookie will report 400 error nginx 400 bad request
If the request exceeds the buffer, it will report HTTP 414 error (URI Too Long) nginx accepts the longest HTTP header size must be larger than one of the buffers, otherwise it will Report a 400 HTTP error (Bad Request).
open_file_cache max 102400
Use fields: http, server, location This directive specifies whether the cache is enabled. If enabled, the following information about the file will be recorded: ·Opened file description character, size information and modification time. · Existing directory information. · Error message during file search - without this file, it cannot be read correctly, refer to open_file_cache_errors directive options: · max - specifies the maximum number of caches , if the cache overflows, the longest used file (LRU) will be removed
Example: open_file_cache max=1000 inactive=20s; open_file_cache_valid 30s; open_file_cache_min_uses 2; open_file_cache_errors on;
open_file_cache_errors
Syntax: open_file_cache_errors on | off Default value: open_file_cache_errors off Fields used: http, server, location This directive specifies whether to search for a file and log cache errors.
open_file_cache_min_uses
Syntax: open_file_cache_min_uses number Default value: open_file_cache_min_uses 1 Usage fields: http, server, location This directive specifies the minimum number of files that can be used within a certain time range in the invalid parameters of the open_file_cache directive. If a larger value is used, the file description The symbol is always open in the cache. open_file_cache_valid
Syntax: open_file_cache_valid time Default value: open_file_cache_valid 60 Usage fields: http, server, location This directive specifies when it is necessary to check the validity of the cached items in open_file_cache Information.
Turn on gzip
gzip on; gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/ plain application/x-javascript text/css
application/xml;
gzip_vary on;
Cache static files:
expires 1m; }
Response buffer:
For example, our Nginx Tomcat proxy access JS cannot be fully loaded. These parameters affect:
proxy_buffer_size 128k;
proxy_buffers 32 128k;
proxy_busy_buffers_size 128k;
Nginx obtains the corresponding file after proxying the corresponding service or based on the UpStream and location we configured. First, the file will be Parse into nginx's memory or temporary file directory, and then nginx will respond. Then when proxy_buffers, proxy_buffer_size and proxy_busy_buffers_size are too small, the content will be generated into a temporary file according to the nginx configuration, but the size of the temporary file also has a default value. Therefore, when these four values are too small, only part of some files will be loaded. Therefore, proxy_buffers and proxy_buffer_size as well as proxy_busy_buffers_size and proxy_temp_file_write_size must be appropriately adjusted according to our server conditions. The details of the specific parameters are as follows:
proxy_buffers 32 128k; 32 buffer areas are set up, each with a size of 128k
proxy_buffer_size 128k; The size of each buffer area is 128k, when When the two values are inconsistent and no specific valid one is found, it is recommended to be consistent with the above settings.
proxy_busy_buffers_size 128k;Set the size of the buffer area in use and control the maximum cache transferred to the client
proxy_temp_file_write_size The size of the cache file
6. Optimize access logs
Recording each request consumes CPU and I/O cycles. One way to reduce this impact is to buffer access logs . Using buffering, rather than performing a separate write operation for each log record, NGINX buffers a series of log records and writes them together to a file in a single operation.
To enable the cache of access logs, it involves the parameter buffer=size in the access_log directive. When the buffer reaches the size value, NGINX will write the contents of the buffer to the log. To have NGINX write to the cache after a specified period of time, include the flush=time parameter. When both parameters are set, NGINX will write the entry to the log file when the next log entry exceeds the buffer value or the log entry in the buffer exceeds the set time value. This is also logged when the worker process reopens its log file or exits. To completely disable access logging, set the access_log directive to the off parameter.
7. Current limit
You can set multiple limits to prevent users from consuming Too many resources to avoid affecting system performance, user experience and security. The following are the relevant directives:
limit_conn and limit_conn_zone: NGINX accepts a limit on the number of customer connections, such as connections from a single IP address. Setting these directives prevents a single user from opening too many connections and consuming more resources than they can use.
limit_rate: The limit on the response speed of the transfer to the client (each client opening multiple connections consumes more bandwidth). Setting this limit prevents overloading the system and ensures a more uniform quality of service for all clients.
limit_req and limit_req_zone: The rate limit for NGINX processing requests, which has the same function as limit_rate. You can improve security, especially for login pages, by setting a reasonable value for the user limit request rate to prevent too slow programs from overwriting your application requests (such as DDoS attacks).
max_conns: Server command parameters in the upper game configuration block. The maximum number of concurrencies a single server can accept in an upstream server group. Use this limit to prevent overloading the upstream server. Setting a value of 0 (the default) means no limit.
queue (NGINX Plus): Create a queue to store the number of requests in the upstream server that exceed their maximum max_cons limit. This directive sets the maximum number of queued requests and optionally sets the maximum waiting time before returning an error (default is 60 seconds). If this directive is omitted, the request will not be queued.
7. Error troubleshooting
1. Nginx 502 Bad Gateway:
A server working as a gateway or proxy received an invalid response from the upstream server when trying to perform a request.
Common reasons:
1. If the backend service hangs up, directly 502 (nginx error log: connect() failed (111: Connection refused))
2. Backend The service is restarting
Example: Turn off the backend service, and then send a request to the backend interface to nginx. You can see a 502 error in the nginx log.
If nginx php appears 502, error analysis:
The number of php-cgi processes is not enough, the php execution time is long (mysql is slow), or the php-cgi process dies, 502 will appear. mistake
Generally speaking, Nginx 502 Bad Gateway is related to the settings of php-fpm.conf, while Nginx 504 Gateway Time-out is related to the settings of nginx.conf
1), check the current PHP FastCGI Whether the number of processes is sufficient:
netstat -anpo | grep "php-cgi" | wc -l
If the actual "number of FastCGI processes" used is close to the default "number of FastCGI processes" , then it means that the "Number of FastCGI processes" is not enough and needs to be increased.
2). The execution time of some PHP programs exceeds the waiting time of Nginx. You can appropriately increase the timeout time of FastCGI in the nginx.conf configuration file, for example:
http {
...... fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
......
}
2, 504 Gateway Timeout:
nginxWhen a server working as a gateway or proxy tries to execute a request, Failure to receive a timely response from the upstream server (the server identified by the URI, such as HTTP, FTP, LDAP). Common reasons:
This interface is too time-consuming. The back-end service receives the request and starts execution, but fails to return data to nginx within the set time The overall load of the back-end server is too high, accept After the request was received, due to the busy thread, the interface for the request could not be arranged, resulting in the failure to return data to nginx at the set time
2, 413 Request Entity Too Large
## Solution: Increase client_max_body_size
client_max_body_size: The directive specifies the maximum allowed client connection Request entity size, which appears in the Content-Length field of the request header. If the request is larger than the specified value, the client will receive a "Request Entity Too Large" (413) error. Remember, the browser does not know how to display it. This error.
Increasepost_max_size and upload_max_filesize
upstream sent too big header while reading response header from upstream error1) If it is nginx reverse proxy
proxy is forwarded by nginx as client When used, if the header is too large, exceeding the default 1k, it will cause the above-mentioned upstream sent too big header (to put it bluntly, nginx sends external requests to the back-end server, and the header returned by the back-end server is too large for nginx to handle This leads to. server {
server_name *.xywy.com ;
large_client_header_buffers 4 16k;
location / {
#Add these 3 linesproxy_buffer_size 64k;
proxy_buffers 32 32k; proxy_busy_buffers_size 128k;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
2) If it is nginx PHPcgi
the error is with upstream: "fastcgi://127.0.0.1:9000". You should
add more:
fastcgi_buffer_size 128k; fastcgi_buffers 4 128k;
server { listen 80;
index index.html index.htm index.php; 4 128k; proxy_buffer_size 64k;
proxy_buffers 8 64k;
fastcgi_buffer_size 128k;
fastcgi_buffers 4 128k;
to
Vulnerability introduction: nginx is a high-performance web server that is widely used. Not only is it often used as a reverse proxy, it can also support the operation of PHP very well. 80sec discovered that there is a serious security issue. By default, the server may incorrectly parse any type of file in PHP. This will cause serious security issues and allow malicious attackers to compromise nginx that supports PHP. server.
Vulnerability analysis: nginx supports php running in cgi mode by default. For example, in the configuration file, you can location ~ .php$ {root html; fastcgi_pass 127.0 .0.1:9000; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params;}
supports parsing of PHP. When location selects a request, the URI environment variable is used. The key variable SCRIPT_FILENAME passed to the backend Fastcgi is determined by the $fastcgi_script_name generated by nginx. Through analysis, it can be seen that $fastcgi_script_name is directly controlled by the URI environment variable. This is where the problem arises. In order to better support the extraction of PATH_INFO, the cgi.fix_pathinfo option exists in the PHP configuration options. Its purpose is to extract the real script name from SCRIPT_FILENAME. So assuming there is http://www.80sec.com/80sec.jpg, we access <!-- --><br>http://www.80sec.com/80sec.jpg/80sec in the following way. php<br> will get a URI<br><br>/80sec.jpg/80sec.php<br><br> After the location instruction, the request will be handed over to the back-end fastcgi for processing, and nginx will Set the environment variable SCRIPT_FILENAME, the content is
/scripts/80sec.jpg/80sec.php
/scripts/80sec.jpg So this problem does not exist. When the backend fastcgi receives this option, it will decide whether to perform additional processing on SCRIPT_FILENAME based on the fix_pathinfo configuration. Generally, if fix_pathinfo is not set, it will affect applications that use PATH_INFO for routing selection, so this option is generally configured to be turned on. . After passing this option, Php will search for the real script file name. The search method is also to check whether the file exists. At this time, SCRIPT_FILENAME and PATH_INFO will be separated into
/scripts/80sec.jpg and 80sec.php# respectively.
## Finally, using /scripts/80sec.jpg as the script that needs to be executed for this request, the attacker can let nginx use PHP to parse any type of file. POC: Visit a site where nginx supports PHP, and add /80sec.php after any resource file such as robots.txt. At this time, you can see the following difference:
Visit http://www.80sec.com/robots.txt
HTTP/1.1 200 OK
Server: nginx/0.6.32
Date: Thu, 20 May 2010 10 :05:30 GMT Content-Type: text/plain Content-Length: 18
Last-Modified: Thu, 20 May 2010 06:26:34 GMT
Keep-Alive: timeout=20
Accept-Ranges: bytes
Visit http://www.80sec.com/robots.txt/80sec.php<br><br>HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:06:49 GMT<br> Content-Type: text/html<br> Transfer- Encoding: chunked<br> Connection: keep-alive<br> Keep-Alive: timeout=20 X-Powered-By: PHP/5.2.6
The Content-Type of If the change indicates a change in the backend's responsibility for parsing, the site may be vulnerable. Vulnerability vendor: http://www.nginx.org<br><br>Solution: <br><br>We have tried to contact the official, but before that you can reduce losses through the following methods <br><br><br>Close cgi.fix_pathinfo to 0
or
}PS: Thanks to laruence Daniel for his help during the analysis process
The above is the detailed content of 'Xiaobai' will take you to understand the modules and working principles of Nginx! ! !. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Alipay PHP SDK transfer error: How to solve the problem of 'Cannot declare class SignData'?
Apr 01, 2025 am 07:21 AM
Alipay PHP SDK transfer error: How to solve the problem of 'Cannot declare class SignData'?
Apr 01, 2025 am 07:21 AM
Alipay PHP...
 Explain JSON Web Tokens (JWT) and their use case in PHP APIs.
Apr 05, 2025 am 12:04 AM
Explain JSON Web Tokens (JWT) and their use case in PHP APIs.
Apr 05, 2025 am 12:04 AM
JWT is an open standard based on JSON, used to securely transmit information between parties, mainly for identity authentication and information exchange. 1. JWT consists of three parts: Header, Payload and Signature. 2. The working principle of JWT includes three steps: generating JWT, verifying JWT and parsing Payload. 3. When using JWT for authentication in PHP, JWT can be generated and verified, and user role and permission information can be included in advanced usage. 4. Common errors include signature verification failure, token expiration, and payload oversized. Debugging skills include using debugging tools and logging. 5. Performance optimization and best practices include using appropriate signature algorithms, setting validity periods reasonably,
 Explain the concept of late static binding in PHP.
Mar 21, 2025 pm 01:33 PM
Explain the concept of late static binding in PHP.
Mar 21, 2025 pm 01:33 PM
Article discusses late static binding (LSB) in PHP, introduced in PHP 5.3, allowing runtime resolution of static method calls for more flexible inheritance.Main issue: LSB vs. traditional polymorphism; LSB's practical applications and potential perfo
 Framework Security Features: Protecting against vulnerabilities.
Mar 28, 2025 pm 05:11 PM
Framework Security Features: Protecting against vulnerabilities.
Mar 28, 2025 pm 05:11 PM
Article discusses essential security features in frameworks to protect against vulnerabilities, including input validation, authentication, and regular updates.
 Customizing/Extending Frameworks: How to add custom functionality.
Mar 28, 2025 pm 05:12 PM
Customizing/Extending Frameworks: How to add custom functionality.
Mar 28, 2025 pm 05:12 PM
The article discusses adding custom functionality to frameworks, focusing on understanding architecture, identifying extension points, and best practices for integration and debugging.
 How to send a POST request containing JSON data using PHP's cURL library?
Apr 01, 2025 pm 03:12 PM
How to send a POST request containing JSON data using PHP's cURL library?
Apr 01, 2025 pm 03:12 PM
Sending JSON data using PHP's cURL library In PHP development, it is often necessary to interact with external APIs. One of the common ways is to use cURL library to send POST�...
 Describe the SOLID principles and how they apply to PHP development.
Apr 03, 2025 am 12:04 AM
Describe the SOLID principles and how they apply to PHP development.
Apr 03, 2025 am 12:04 AM
The application of SOLID principle in PHP development includes: 1. Single responsibility principle (SRP): Each class is responsible for only one function. 2. Open and close principle (OCP): Changes are achieved through extension rather than modification. 3. Lisch's Substitution Principle (LSP): Subclasses can replace base classes without affecting program accuracy. 4. Interface isolation principle (ISP): Use fine-grained interfaces to avoid dependencies and unused methods. 5. Dependency inversion principle (DIP): High and low-level modules rely on abstraction and are implemented through dependency injection.
 What exactly is the non-blocking feature of ReactPHP? How to handle its blocking I/O operations?
Apr 01, 2025 pm 03:09 PM
What exactly is the non-blocking feature of ReactPHP? How to handle its blocking I/O operations?
Apr 01, 2025 pm 03:09 PM
An official introduction to the non-blocking feature of ReactPHP in-depth interpretation of ReactPHP's non-blocking feature has aroused many developers' questions: "ReactPHPisnon-blockingbydefault...
