

This article will take you through the master-slave, master-slave and read-write separation in MySQL. I hope it will be helpful to you!
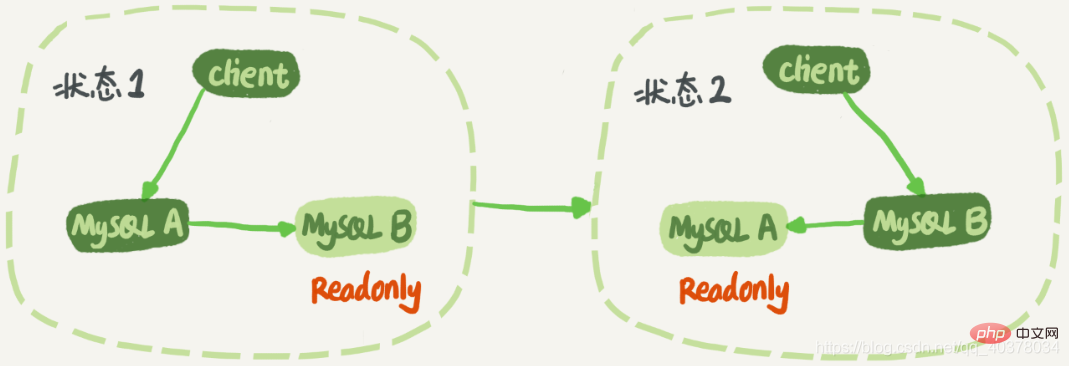
In state 1, the client directly accesses node A for reading and writing, while node B It is the standby database of A. It just synchronizes all updates of A and executes them locally. This keeps the data of nodes B and A the same. When it is necessary to switch, it switches to state 2. At this time, the client reads and writes to node B, and node A is B's standby database. [Related recommendations: mysql video tutorial]
In state 1, although node B is not directly accessed, it is recommended to set standby node B to read-only mode. There are several reasons:
1. Sometimes some operational query statements will be put into the standby database for query. Setting it to read-only can prevent misoperation
2. Prevent switching logic There is a bug
3. You can use the readonly status to determine the role of the node
If you set the standby database to read-only, how can you keep up to date with the main database?
The readonly setting is invalid for super-privileged users, and the thread used for synchronized updates has super-privileged
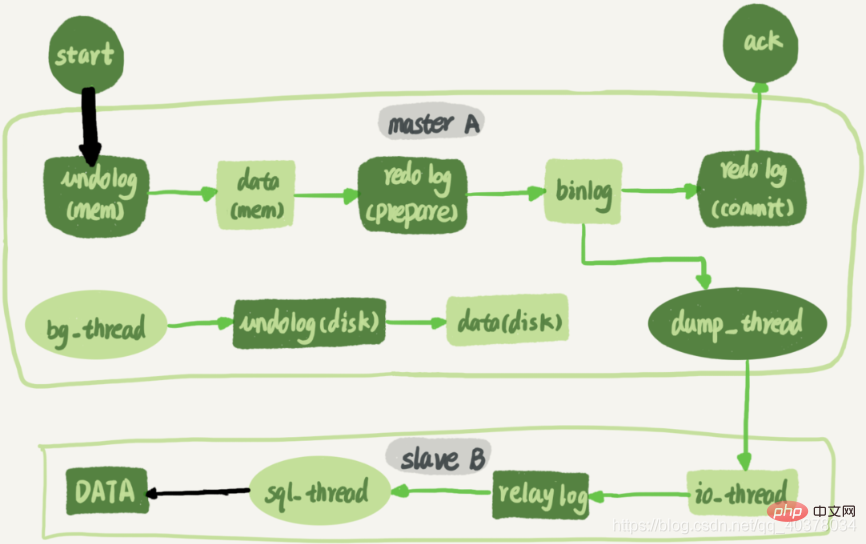
The following figure shows an update statement executed on node A, and then synchronized to node B The complete flow chart: 
A long connection is maintained between standby database B and primary database A. There is a thread inside the main library A, which is dedicated to serving the long connection of the standby library B. The complete process of transaction log synchronization is as follows:
1. Use the change master command on standby database B to set the IP, port, username, password of primary database A, and the location from which to start requesting binlog. This location contains the file name and log offset
2. Execute the start slave command on standby database B. At this time, the standby database will start two threads, namely io_thread and sql_thread in the figure. Among them, io_thread is responsible for establishing a connection with the main library
3. After the main library A verifies the user name and password, it starts to read the binlog from the local according to the location passed by the standby library B, and sends it to B
4. After standby database B gets the binlog, it writes it to a local file, which is called the transit log
5.sql_thread reads the transit log, parses out the commands in the log, and executes
Due to the introduction of multi-threaded replication scheme, sql_thread evolved into multiple threads
Double M structure:
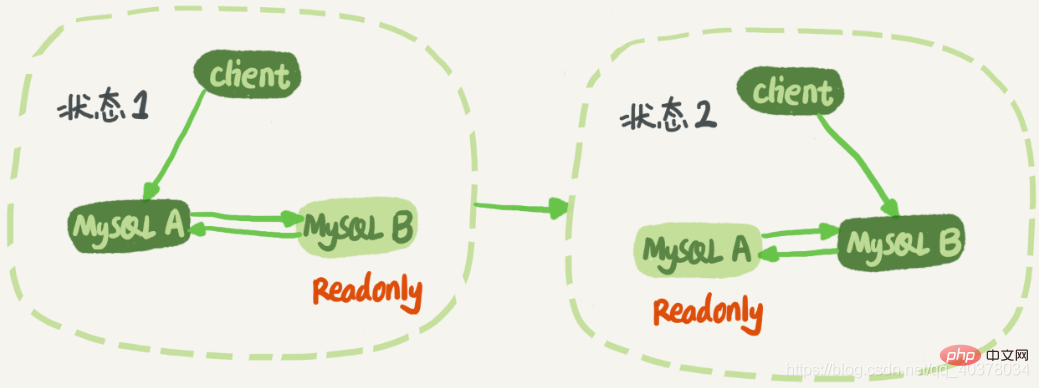
Node A and node B have a master-standby relationship with each other. In this way, there is no need to modify the active-standby relationship during the switch.
There is a problem to be solved in the double-M structure. The business logic updates a statement on node A, and then sends the generated binlog to node B. Node B After B executes this update statement, binlog will also be generated. Then, if node A is also the standby database of node B, it is equivalent to taking the newly generated binlog of node B and executing it once. Then, the update statement will be continuously executed in a loop between nodes A and B, that is, loop replication
MySQL records the server id of the instance where this command was executed for the first time in the binlog. Therefore, the following logic can be used to solve the problem of circular replication between two nodes:
1. It is stipulated that the server IDs of the two libraries must be different. If they are the same, they cannot be set as the primary and secondary servers. Relationship
2. A standby database receives the binlog and during the replay process, generates a new binlog that is the same as the server id of the original binlog
3. Each database receives the binlog from After the log is sent from your own main library, first determine the server ID. If it is the same as your own, it means that the log was generated by yourself, and you will directly discard the log.
The execution flow of the double M structure log is as follows:
1. For transactions updated from node A, the server id of A is recorded in the binlog.
2. After being transmitted to node B and executed once, the server id of the binlog generated by node B is also A. The server id
3. Then it is sent back to node A. A determines that the server id is the same as its own and will not process the log anymore. Therefore, the infinite loop is broken here
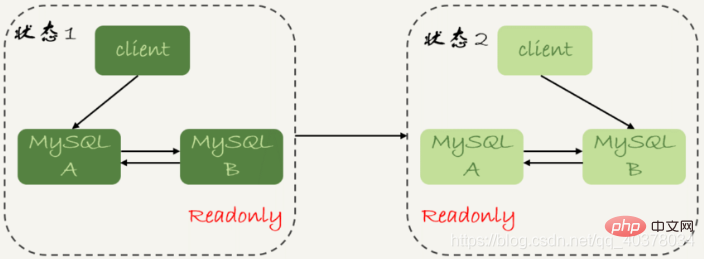
The time points related to data synchronization mainly include the following three:
1. Main library A completes a transaction and writes it to binlog. This moment is recorded as T1
2. Then pass it to standby database B. The time when standby database B receives the binlog is recorded as T2
3. After standby database B completes the transaction, the time is recorded as T3
The so-called master-slave delay is the difference between the time when the slave database is executed and the time when the master database is completed for the same transaction, that is, T3-T1
You can execute show on the slave database slave status command, its return result will display seconds_behind_master, which is used to indicate how many seconds the current standby database has been delayed.
The calculation method of seconds_behind_master is as follows:
1. There is a time field in the binlog of each transaction, which is used to record the time written on the main database.
2. The standby database takes out the value of the time field of the currently executing transaction and calculates The difference between it and the current system time is seconds_behind_master
If the system time settings of the main and standby database machines are inconsistent, it will not lead to inaccurate values of the main and standby delay. When the standby database is connected to the primary database, it will obtain the system time of the current primary database through the SELECTUNIX_TIMESTAMP() function. If it is found that the system time of the main database is inconsistent with its own, the standby database will automatically deduct the difference when performing seconds_behind_master calculation
Under normal network conditions, the main source of delay between the primary and standby database is that the standby database has received The time difference between binlog and the execution of this transaction
The most direct manifestation of the master-backup delay is that the speed at which the backup database consumes transfer logs is slower than the speed at which the main database produces binlog
1. Under some deployment conditions, the performance of the machine where the backup database is located is worse than the performance of the machine where the primary database is located
2. high pressure. The main database provides writing capabilities, and the standby database provides some reading capabilities. Ignoring the pressure control of the standby database, the query on the standby database consumes a lot of CPU resources, affects the synchronization speed, and causes the delay of the primary and secondary databases
You can do the following processing:
3. Big business. Because the main database must wait for the transaction to be executed before it is written to the binlog and then passed to the standby database. Therefore, if a statement on the main database is executed for 10 minutes, then this transaction is likely to cause a 10-minute delay on the slave database.
Typical large transaction scenario: using the delete statement to delete too much data and large tables at once DDL
Under the double M structure, the slave The detailed process of switching from state 1 to state 2 is as follows:
1. Determine the current seconds_behind_master of standby database B. If it is less than a certain value, continue to the next step, otherwise continue to retry this step
2. Change the main library A to a read-only state, that is, set readonly to true
3. Determine the value of seconds_behind_master of the standby library B until the value becomes 0
4. Change library B to a read-write state, that is, set readonly to false
5. Switch the business request to standby library B
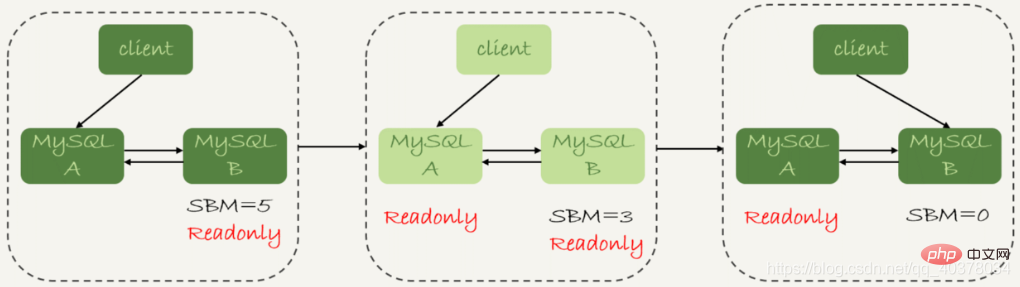
Is there any problem in this switching process? Used time. After step 2, both main database A and standby database B are in the readonly state, which means that the system is in a non-writable state and cannot be restored until step 5 is completed. In this unavailable state, the more time-consuming step is step 3, which may take several seconds. This is also why we need to make a judgment first in step 1 to ensure that the value of seconds_behind_master is small enough
The unavailability time of the system is determined by this data reliability priority strategy
Availability priority strategy: If steps 4 and 5 of the reliability priority strategy are forcibly adjusted to be executed at the beginning, that is to say, the connection will be directly switched to the standby database without waiting for the main and standby data to be synchronized. B, and allowing standby database B to read and write, then the system will have almost no unavailable time. The cost of this switching process is the possibility of data inconsistency
mysql> CREATE TABLE `t` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c` int(11) unsigned DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);
Table t defines an auto-incrementing primary key id. After the data is initialized, there are 3 rows of data in the main database and the standby database. Continue to execute the two insert statement commands on table t, in order:
insert into t(c) values(4);insert into t(c) values(5);
Assume that there are a large number of updates to other data tables on the main database, causing the main-standby delay to reach 5 seconds. After inserting a statement with c=4, an active/standby switchover is initiated
The following figure shows the switching process and data results when the availability priority strategy is available and binlog_format=mixed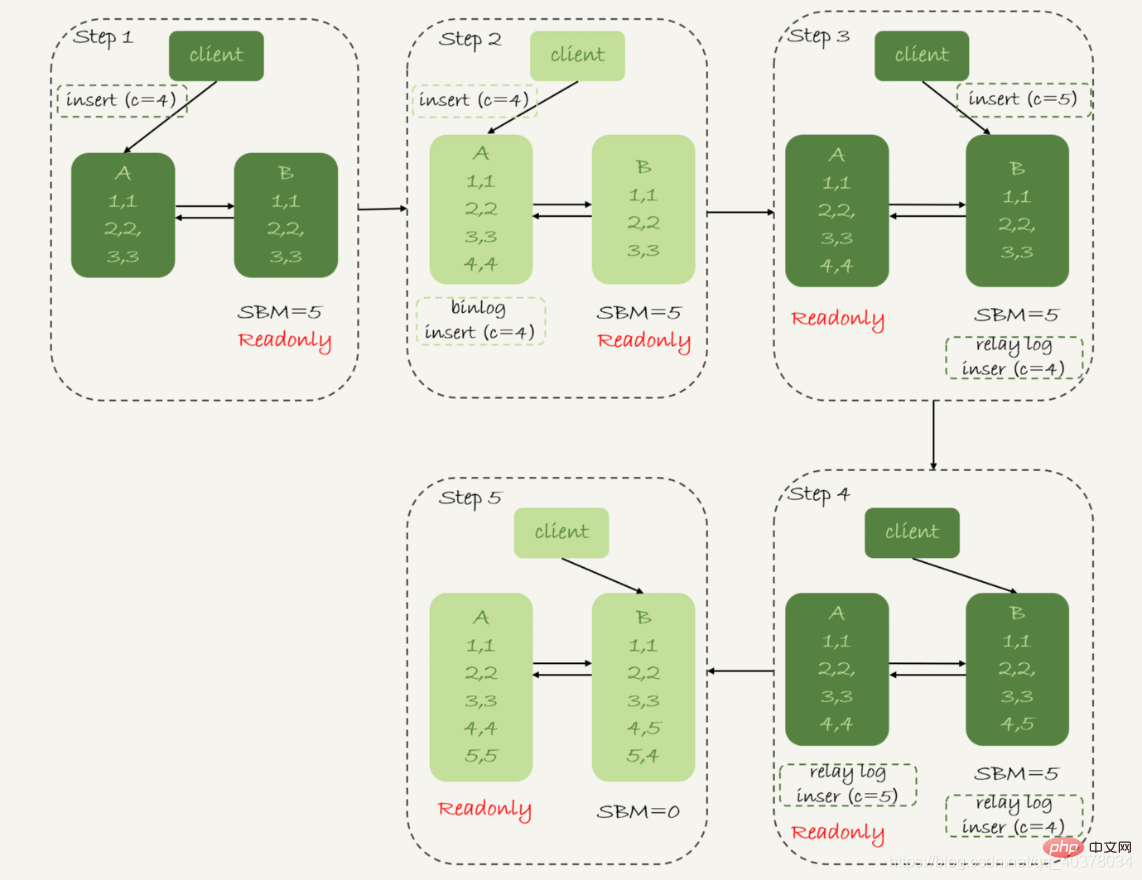
1. In step 2, the main database A finishes executing the insert statement and inserts a row of data (4,4), and then starts the active-standby switch
2. In step 3, due to the 5-second delay between the active and standby , so before standby database B has time to apply the transfer log that inserts c=4, it starts to receive the client’s command to insert c=5
3. In step 4, standby database B inserts a row of data (4, 5), and send this binlog to the main database A
4. In step 5, the standby database B inserts the transfer log c=4 and inserts a row of data (5,4). The insert c=5 statement that is directly executed in the standby database B is passed to the main database A, and a new row of data (5,5) is inserted.
The final result is that the main database A and the standby database B Two rows of inconsistent data appear
Availability priority strategy, set binlog_format=row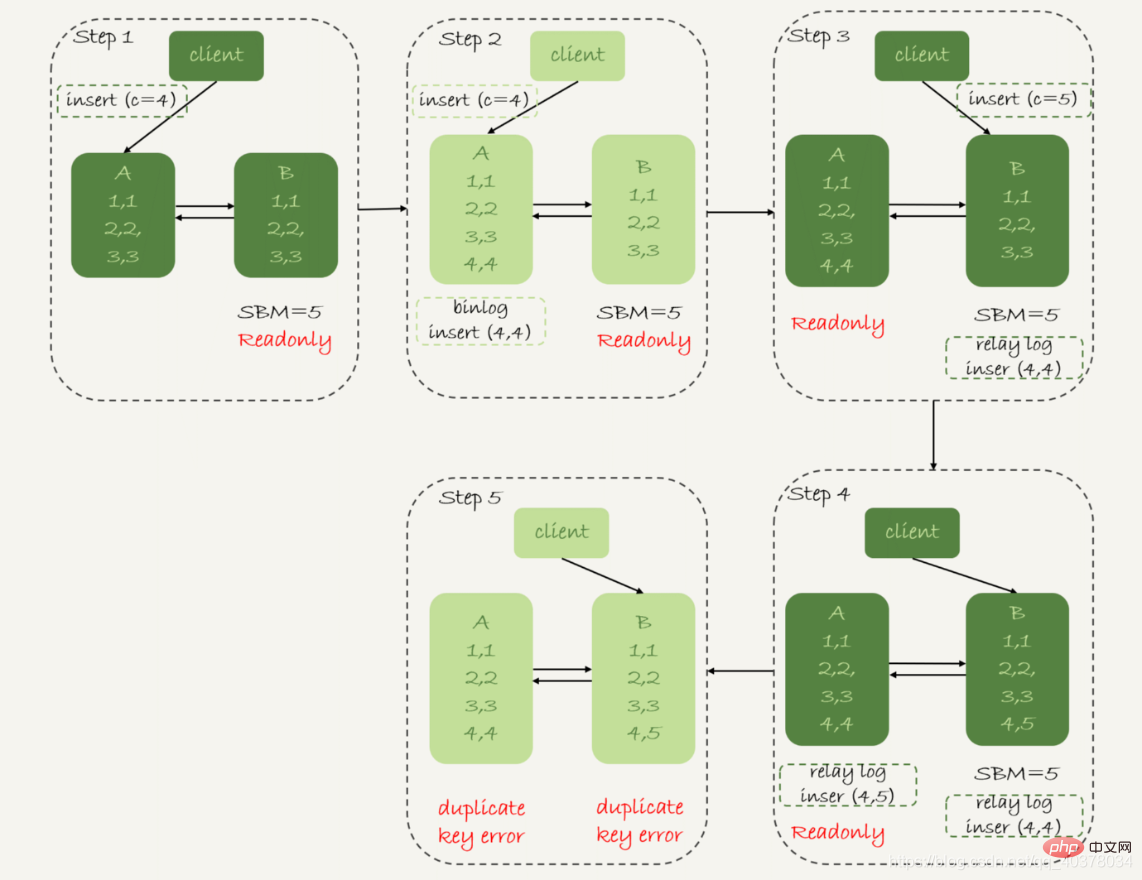
Therefore, when row format records binlog, it will record all field values of the newly inserted row, so in the end there will only be one row that is inconsistent. Moreover, the application threads of the active and standby synchronization on both sides will report a duplicate key error and stop. In other words, in this case, the two rows of data (5,4) in standby database B and (5,5) in primary database A will not be executed by the other party
1. When using binlog in row format, data inconsistency problems are easier to find. When using mixed or statement format binlog, it may take a long time to discover the data inconsistency problem
2. The availability priority strategy of active-standby switchover will lead to data inconsistency. Therefore, in most cases, it is recommended to adopt the reliability priority strategy
Primary and secondary Regarding the parallel replication capability, what you should pay attention to are the two black arrows in the picture above. One represents the client writing to the main database, and the other represents the sql_thread execution transfer log on the standby database.
Before the MySQL version 5.6, MySQL only supported single-thread replication. Therefore, when the main database concurrency was high and TPS was high, Serious master-backup delay problems will occur
The multi-thread replication mechanism splits the sql_thread with only one thread into multiple threads, which is consistent with the following model:
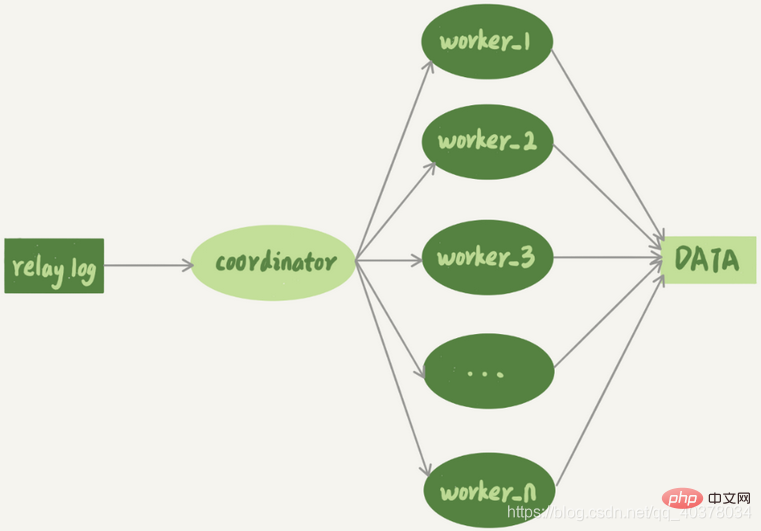
The coordinator is the original sql_thread, but now it no longer updates data directly, it is only responsible for reading the transit log and distributing transactions. What actually updates the log becomes the worker thread. The number of worker threads is determined by the parameter slave_parallel_workers. When distributing, the coordinator needs to meet the following two basic requirements:
. The parallel effect of this strategy depends on the pressure model. If there are multiple DBs on the main database, and the pressure of each DB is balanced, the effect of using this strategy will be very good
Two advantages of this strategy:
Construct the hash value It is very fast, only the library name1. Transactions submitted together in a group have the same commit_id, the next group is commit_id 1
2. Commit_id is written directly into the binlog
3. When transmitted to the standby database application, transactions with the same commit_id are distributed to multiple workers for execution
4. After all the execution of this group is completed, the coordinator will take down the next batch
In the figure below, it is assumed that the execution of three groups of transactions in the main library, when trx1, trx2 and trx3 are submitted, trx4, trx5 and trx6 are executing. In this way, when the first group of transactions is submitted, the next group of transactions will soon enter the commit state
According to MariaDB's parallel replication strategy, the execution effect on the standby database is as follows : 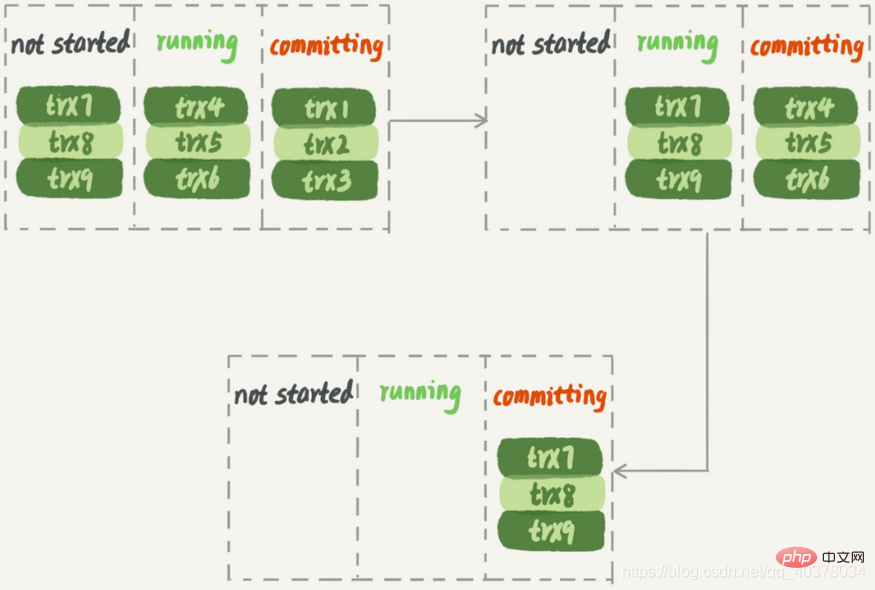
When executing on the standby database, the second group of transactions must wait until the first group of transactions is completely executed before the second group of transactions can start executing. In this way, the system throughput will not be enough. 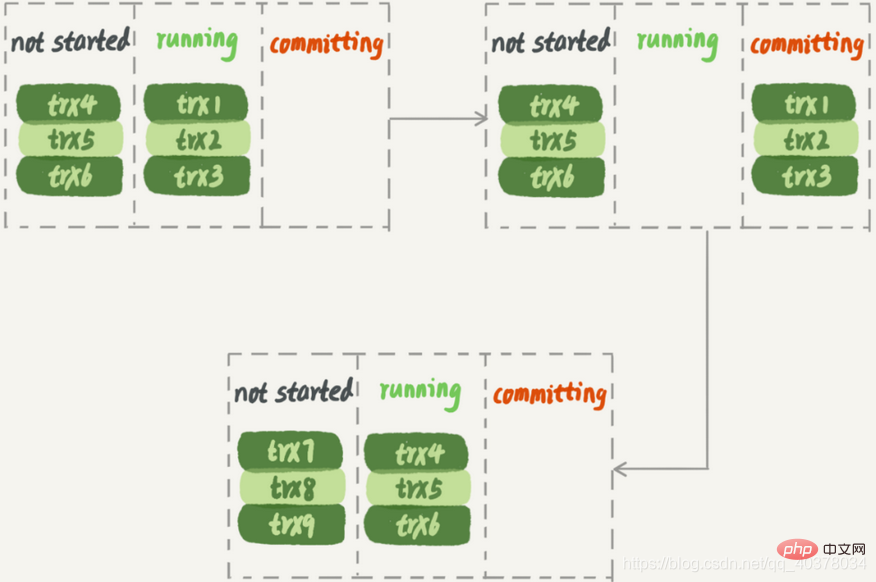
In addition, this plan is easily hindered by major events. Assuming that trx2 is a very large transaction, when the standby database is applied, after the execution of trx1 and trx3 is completed, the next group can start execution. Only one worker thread is working, which is a waste of resources
不可以,因为这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的worker,就会出现备库跟主库不一致的情况
而MariaDB这个策略的核心是所有处于commit状态的事务可以并行。事务处于commit状态表示已经通过了锁冲突的检验了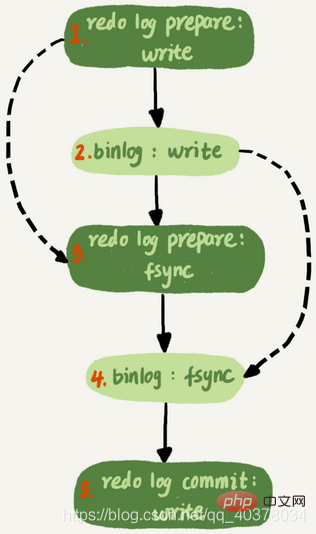
其实只要能够达到redo log prepare阶段就表示事务已经通过锁冲突的检验了
因此,MySQL5.7并行复制策略的思想是:
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
binlog组提交的时候有两个参数:
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL5.7的并行复制策略里,它们可以用来制造更多的同时处于prepare阶段的事务。这样就增加了备库复制的并行度。也就是说,这两个参数既可以故意让主库提交得慢些,又可以让备库执行得快些
MySQL5.7.22增加了一个新的并行复制策略,基于WRITESET的并行复制,新增了一个参数binlog-transaction-dependency-tracking用来控制是否启用这个新策略。这个参数的可选值有以下三种:
为了唯一标识,hash值是通过库名+表名+索引名+值计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值
1.writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候不需要解析binlog内容
2.不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存
3.由于备库的分发策略不依赖于binlog内容,索引binlog是statement格式也是可以的
对于表上没主键和外键约束的场景,WRITESET策略也是没法并行的,会暂时退化为单线程模型
下图是一个基本的一主多从结构
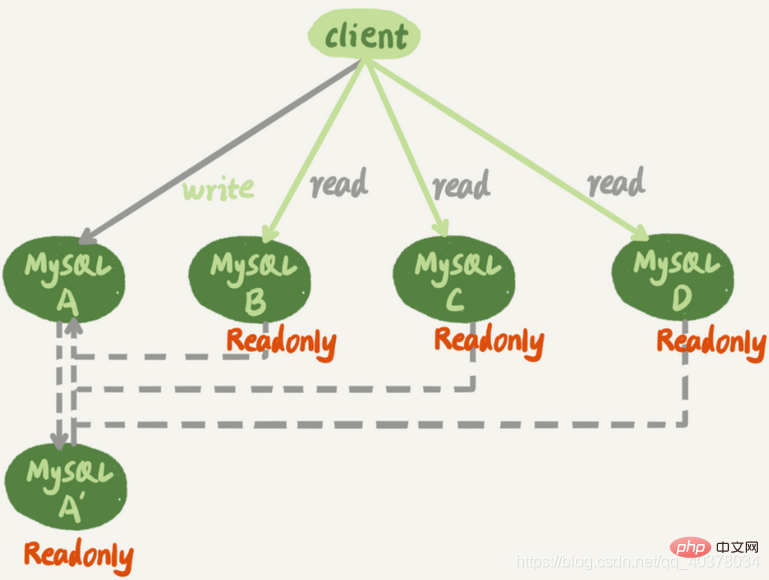
图中,虚线箭头表示的是主备关系,也就是A和A’互为主备,从库B、C、D指向的是主库A。一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担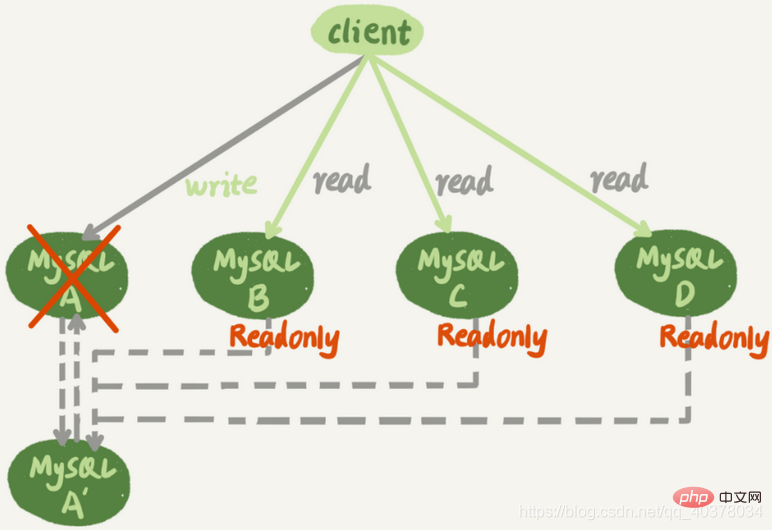
一主多从结构在切换完成后,A’会成为新的主库,从库B、C、D也要改接到A’
当我们把节点B设置成节点A’的从库的时候,需要执行一条change master命令:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
找同步位点很难精确取到,只能取一个大概位置。一种去同步位点的方法是这样的:
1.等待新主库A’把中转日志全部同步完成
2.在A’上执行show master status命令,得到当前A’上最新的File和Position
3.取原主库A故障的时刻T
4.用mysqlbinlog工具解析A’的File,得到T时刻的位点,这个值就可以作为$master_log_pos
这个值并不精确,有这么一种情况,假设在T这个时刻,主库A已经执行完成了一个insert语句插入了一行数据R,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A的主机就掉电了。那么,这时候系统的状态是这样的:
1.在从库B上,由于同步了binlog,R这一行已经存在
2.在新主库A’上,R这一行也已经存在,日志是写在master_log_pos这个位置之后的
3.在从库B上执行change master命令,指向A’的File文件的master_log_pos位置,就会把插入R这一行数据的binlog又同步到从库B去执行,造成主键冲突,然后停止tongue
通常情况下,切换任务的时候,要先主动跳过这些错误,有两种常用的方法
一种是,主动跳过一个事务
set global sql_slave_skip_counter=1;start slave;
另一种方式是,通过设置slave_skip_errors参数,直接设置跳过指定的错误。这个背景是,我们很清楚在主备切换过程中,直接跳过这些错误是无损的,所以才可以设置slave_skip_errors参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了
MySQL5.6引入了GTID,是一个全局事务ID,是一个事务提交的时候生成的,是这个事务的唯一标识。它的格式是:
GTID=source_id:transaction_id
GTID模式的启动只需要在启动一个MySQL实例的时候,加上参数gtid_mode=on和enforce_gtid_consistency=on就可以了
在GTID模式下,每个事务都会跟一个GTID一一对应。这个GTID有两种生成方式,而使用哪种方式取决于session变量gtid_next的值
1.如果gtid_next=automatic,代表使用默认值。这时,MySQL就把GTID分配给这个事务。记录binlog的时候,先记录一行SET@@SESSION.GTID_NEXT=‘GTID’。把这个GTID加入本实例的GTID集合
2.如果gtid_next是一个指定的GTID的值,比如通过set gtid_next=‘current_gtid’,那么就有两种可能:
一个current_gtid只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样每个MySQL实例都维护了一个GTID集合,用来对应这个实例执行过的所有事务
在GTID模式下,备库B要设置为新主库A’的从库的语法如下:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
其中master_auto_position=1就表示这个主备关系使用的是GTID协议
实例A’的GTID集合记为set_a,实例B的GTID集合记为set_b。我们在实例B上执行start slave命令,取binlog的逻辑是这样的:
1.实例B指定主库A’,基于主备协议建立连接
2.实例B把set_b发给主库A’
3.实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的GTID的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
4.之后从这个事务开始,往后读文件,按顺序取binlog发给B去执行
如果是由于索引缺失引起的性能问题,可以在线加索引来解决。但是,考虑到要避免新增索引对主库性能造成的影响,可以先在备库加索引,然后再切换,在双M结构下,备库执行的DDL语句也会传给主库,为了避免传回后对主库造成影响,要通过set sql_log_bin=off关掉binlog,但是操作可能会导致数据和日志不一致
两个互为主备关系的库实例X和实例Y,且当前主库是X,并且都打开了GTID模式。这时的主备切换流程可以变成下面这样:
set GTID_NEXT="source_id_of_Y:transaction_id";begin;commit;set gtid_next=automatic;start slave;
这样做的目的在于,既可以让实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这条更新
读写分离的基本结构如下图:
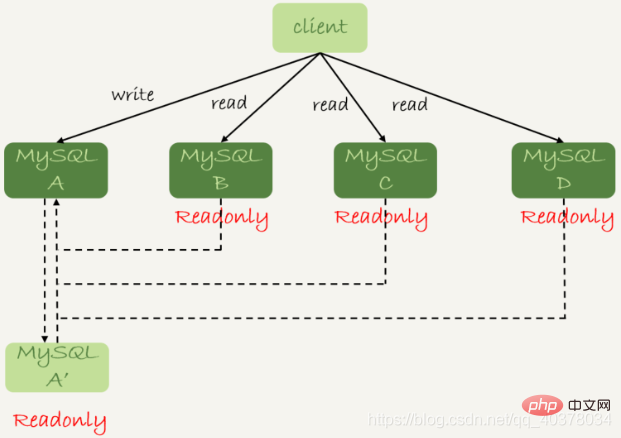
读写分离的主要目的就是分摊主库的压力。上图中的结构是客户端主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。由客户端来选择后端数据库进行查询
还有一种架构就是在MySQL和客户端之间有一个中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路由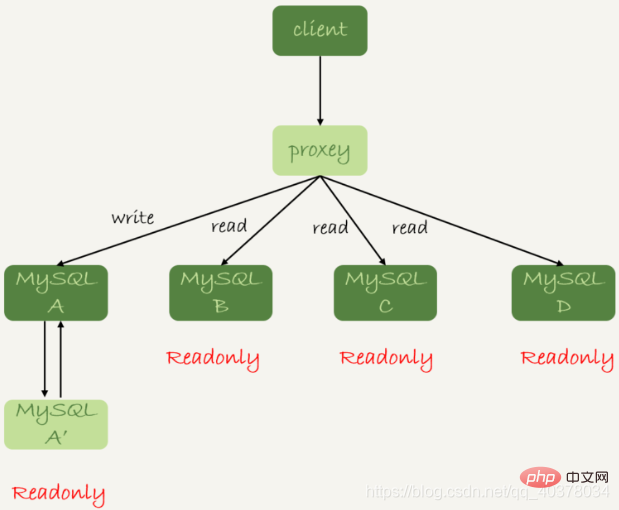
1.客户端直连方案,因此少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发
2.带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高,而且proxy也需要有高可用架构
在从库上会读到系统的一个过期状态的现象称为过期读
强制走主库方案其实就是将查询请求做分类。通常情况下,可以分为这么两类:
1.对于必须要拿到最新结果的请求,强制将其发到主库上
2.对于可以读到旧数据的请求,才将其发到从库上
这个方案最大的问题在于,有时候可能会遇到所有查询都不能是过期读的需求,比如一些金融类的业务。这样的话,就需要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以很大概率拿到最新的数据
以买家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为最新商品显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题
但这个方案并不精确:
1.如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒
2.如果延迟超过1秒,还是会出现过期读
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短
1.第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0,那就必须等到这个参数变为0才能执行查询请求
show slave status结果的部分截图如下:
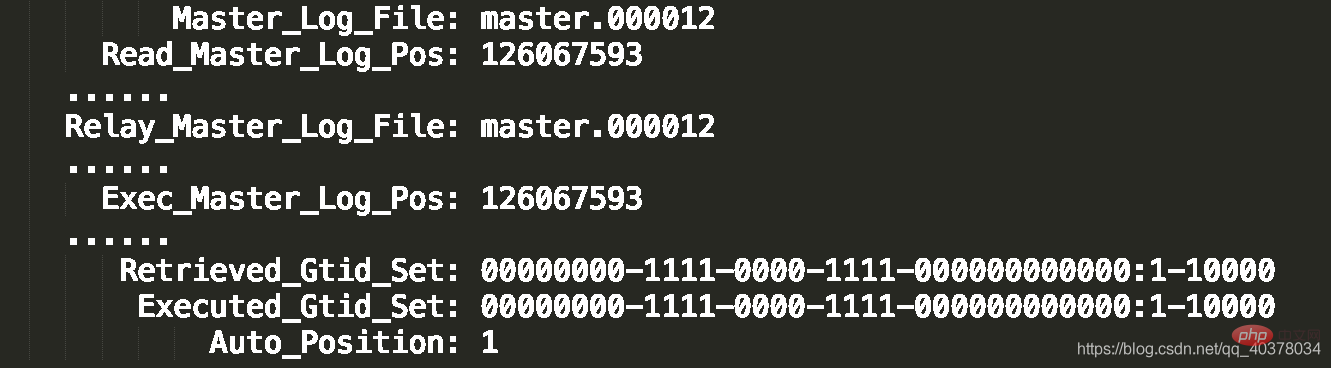
2.第二种方法,对比位点确保主备无延迟:
如果Master_Log_File和Read_Master_Log_Pos和Relay_Master_Log_File和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成
3.第三种方法,对比GTID集合确保主备无延迟:
如果这两个集合相同,也表示备库接收到的日志都已经同步完成
4.一个事务的binlog在主备库之间的状态:
1)主库执行完成,写入binlog,并反馈给客户端
2)binlog被从主库发送给备库,备库收到
3)在备库执行binlog完成
上面判断主备无延迟的逻辑是备库收到的日志都执行完成了。但是,从binlog在主备之间状态的分析中,有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态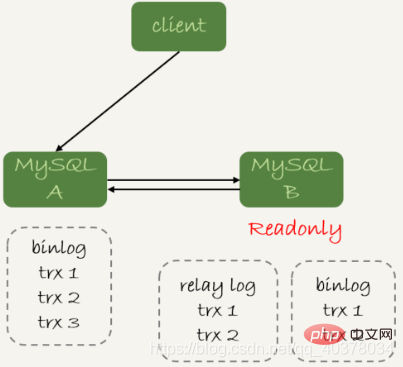
这时,主库上执行完成了三个事务trx1、trx2和trx3,其中:
如果这时候在从库B上执行查询请求,按照上面的逻辑,从库认为已经没有同步延迟,但还是查不到trx3的
要解决上面的问题,就要引入半同步复制。semi-sync做了这样的设计:
1.事务提交的时候,主库把binlog发送给从库
2.从库收到binlog以后,发回给主库一个ack,表示收到了
3.主库收到这个ack以后,才能给客户端返回事务完成的确认
如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志
semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
1.如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据
2.但如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很有可能出现从库上迟迟无法响应查询请求的情况
上图从状态1到状态4,一直处于延迟一个事务的状态。但是,其实客户端是在发完trx1更新后发起的select语句,我们只需要确保trx1已经执行完成就可以执行select语句了。也就是说,如果在状态3执行查询请求,得到的就是预期结果了
semi-sync配合主备无延迟的方案,存在两个问题:
1.一主多从的时候,在某些从库执行查询请求会存在过期读的现象
2.在持续延迟的情况下,可能出现过度等待的问题
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
1.它是在从库执行的
2.参数file和pos指的是主库上的文件名和位置
3.timeout可选,设置为正整数N表示这个函数最多等待N秒
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务
1.如果执行期间,备库同步线程发生异常,则返回NULL
2.如果等待超过N秒,就返回-1
3.如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0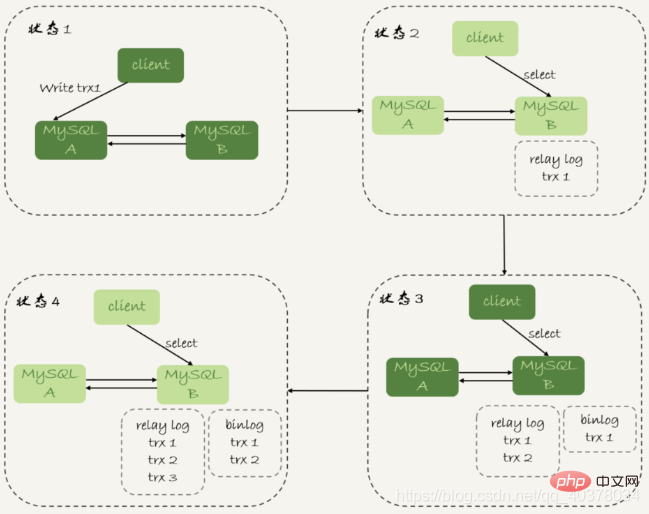
对于上图中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,可以使用这个逻辑:
1.trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position
2.选定一个从库执行查询语句
3.在从库上执行select master_pos_wait(file, pos, 1)
4.如果返回值是>=0的正整数,则在这个从库执行查询语句
5.否则,到主库执行查询语句
流程如下:
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑如下:
1.等待,直到这个库执行的事务中包含传入的gtid_set,返回0
2.超时返回1
等主库位点方案中,执行完事务后,还要主动去主库执行show master status。而MySQL5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案可以减少一次查询
等GTID的流程如下:
1.trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询语句
3. Execute select wait_for_executed_gtid_set(gtid1, 1);
4. If the return value is 0, execute the query statement on the slave library
5. Otherwise, Go to the main database to execute the query statement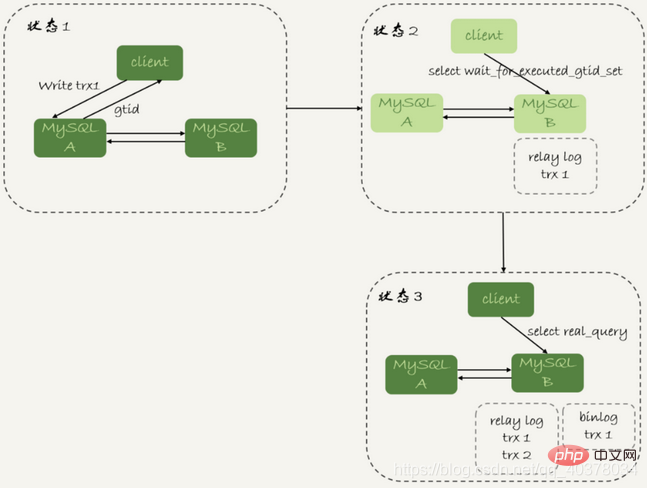
For more programming-related knowledge, please visit:Introduction to Programming! !
The above is the detailed content of Learn more about master-standby, master-slave, and read-write separation in MySQL. For more information, please follow other related articles on the PHP Chinese website!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



