
 Database
Mysql Tutorial
Detailed explanation of count(), union() and group by statements in MySQL
Database
Mysql Tutorial
Detailed explanation of count(), union() and group by statements in MySQL
Detailed explanation of count(), union() and group by statements in MySQL

This article will take you through count(), union() and group by statements, and supplement MySQL knowledge points (the usage of different count(), union execution process, group by statement).

1. Different usages of count() in MySQL
count() is an aggregate function, for the returned result set , judge line by line, if the parameter of the count function is not NULL, the cumulative value will be added by 1, otherwise it will not be added. Finally, the cumulative value is returned. [Related recommendations: mysql video tutorial]
1. For count (primary key id), the InnoDB engine will traverse the entire table, take out the id value of each row, and return To the server layer. After the server layer gets the id, it determines that it cannot be empty, so it accumulates it by row
2. For count(1), the InnoDB engine traverses the entire table but does not take a value. The server layer puts a number 1 into each row returned. It is judged that it cannot be empty and accumulates
3 by row. For count (field), if this field is defined as not null , read this field from the record line by line, and judge that it cannot be null, and accumulate it line by line; if the field definition allows null, then when executing, it is judged that it may be null, and the value must be taken out and judged. Now, it’s not null that accumulates
4. For count(*), not all fields are taken out, but are specially optimized. No value is taken, count(*) is definitely not null, and is accumulated by row

## 2. Union execution process
In order to facilitate quantitative analysis, take the following table t1 as an examplecreate table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
END(select 1000 as f) union (select id from t1 order by id desc limit 2);

- The key=PRIMARY in the second row indicates that the second clause uses When it comes to the Extra field in the third row of index id, it means that when doing union on the result set of the subquery, a temporary table is used
3. Execute the second subquery:
- Get the first row id=1000 and try to insert it into the temporary table. But since the value 1000 already exists in the temporary table, it violates the uniqueness constraint, so the insertion fails, and then continues to execute to get the second row id=999, and the insertion into the temporary table is successful

3. Detailed explanation of group by statement
1. Group by execution process
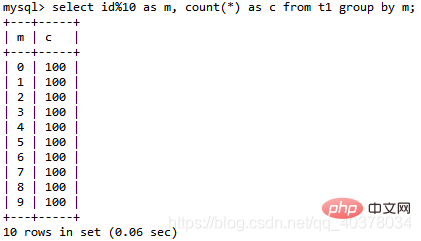
Still use the above table t1 to analyze the following SQL statement:select id%10 as m, count(*) as c from t1 group by m;
 In the Extra field, you can see three pieces of information:
In the Extra field, you can see three pieces of information:
- Using index, indicating that this statement uses a covering index, selected Index a, there is no need to return to the table Using temporary, indicating that a temporary table is used Using filesort, indicating that sorting is required
- If there is no row with primary key x in the temporary table, insert a record (x,1)If there is a row with primary key x in the table row, add 1 to the c value of the row
内存临时表排序流程图:
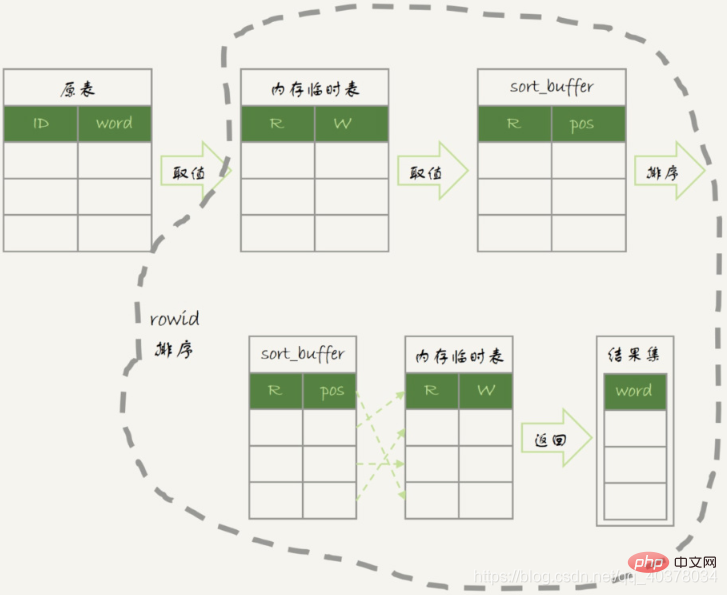
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
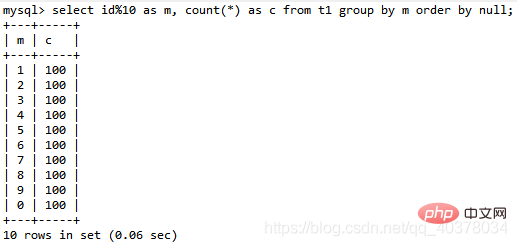
由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
2、group by优化方法——索引
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构

如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:
- 当碰到第一个1的时候,已经知道累积了X个0,结果集里的第一行就是(0,X)
- 当碰到第一个2的时候,已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;

从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了
3、group by优化方法——直接排序
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
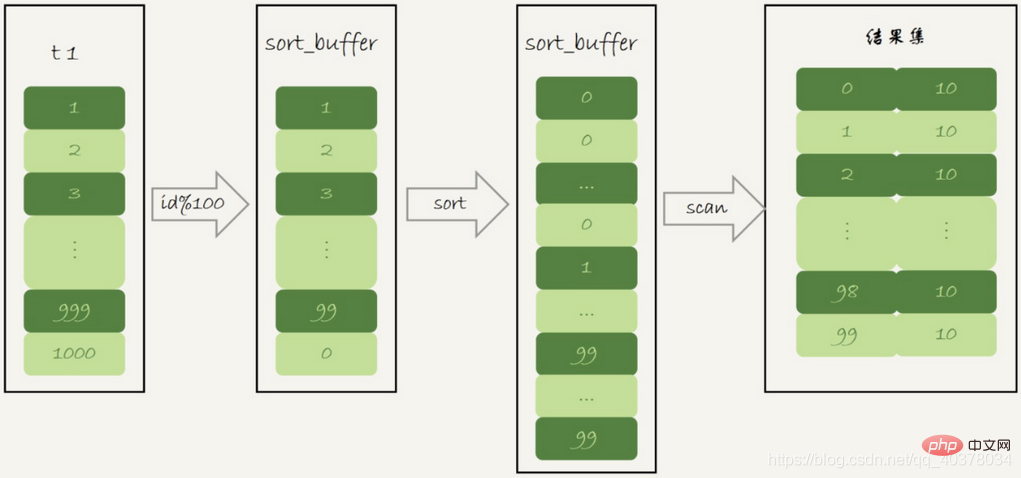
这个语句的执行没有再使用临时表,而是直接用了排序算法
,%20union()%20and%20group%20by%20statements%20in%20MySQL)
更多编程相关知识,请访问:编程入门!!
The above is the detailed content of Detailed explanation of count(), union() and group by statements in MySQL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
 How to view sql database error
Apr 10, 2025 pm 12:09 PM
How to view sql database error
Apr 10, 2025 pm 12:09 PM
The methods for viewing SQL database errors are: 1. View error messages directly; 2. Use SHOW ERRORS and SHOW WARNINGS commands; 3. Access the error log; 4. Use error codes to find the cause of the error; 5. Check the database connection and query syntax; 6. Use debugging tools.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
